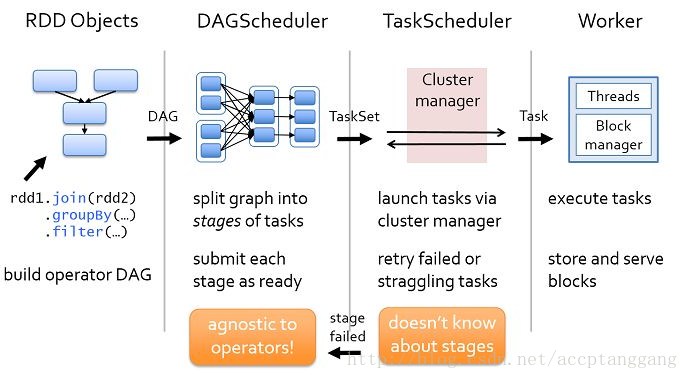
DAGScheduler:根据宽依赖操作,划分stage,将stage中的task封装成tastset
TaskScheduler:接收DAGScheduler提交的调度阶段,并将任务发送到节点,在节点执行任务。
1)针对RDD做各种转换操作,行动操作会触发job的生成,根据RDD血缘关系构建DAG图,DAGScheduler负责解析DAG图、
2)DAGScheduler根据宽依赖将DAG拆分成相互依赖的各个stage,每个stage包含若干个task,每个stage的task形成任务集,提交给TaskScheduler调度。
DAGScheduler计算最优的调度策略,例如选择数据本地化策略。
DAGScheduler监控调度过程,如果某个stage失败,DAGScheduler负责重新提交这一stage。
3)每个TaskScheduler只为一个SparkContext服务。TaskScheduler接收来自DAGScheduler分发的任务集,并分发给各个Executor执行。TaskScheduler负责监控任务执行情况,负责任务重试机制。
4)Executor接收TaskScheduler的任务集,一个任务交给一个线程执行,任务执行完成要将任务信息返回给TaskScheduler。
ShuffleMapTask返回MapStatus对象,而不是结果本身;ResultTask返回的结果参照如下所述。
获取执行结果
对于Executor返回的计算结果:
1)生成结果大小(∞, 1GB),结果直接被丢弃,通过spark.driver.maxResultSize设置。
2)生成结果大小[1GB, 128MB-200KB];生成大小等于128MB-200KB,将结果以taskId为编号存入BlockManager,然后将编号发送给Driver终端点。
3)生成结果大小(128MB-200KB, 0),直接通过Netty发送到Driver终端点。
划分调度阶段:

基于广度优先遍历各依赖的RDD
1)在SparkContext中提交运行时,DAGScheduler中的hadleJobSubmitted进行处理,该方法中找到最后一个RDD,并调用getParentStage方法。
2)getParentStage方法判断rddG的依赖树种是否存在shuffle操作。发现join操作是shuffle操作,获取该操作的RDD是rddB和rddF。
3)使用getAncesterShuffleDependencies方法从rddB向前遍历,发现该依赖分支上没有shuffle操作,即没有宽依赖。调用newOrUsedShuffleStage方法生成调度阶段ShuffleMapStage0。
4)使用getAncesterShuffleDependencies方法,从rddF向前遍历,发现该依赖分支存在宽依赖操作groupBy,以此划分rddD,rddC为ShuffleMapStage1,rddE,rddF为ShuffleMapStage2。
5)最后生成rddG的ResultStage3
提交调度阶段
在handleJobSubmitted方法中获取了该例子的最后一个调度阶段ReusltStage3,通过submitStage方法提交该调度阶段。
在submitStage方法中,先创建作业实例,然后判断该调度阶段是否存在父调度阶段,由于ReusltStage3有两个父调度阶段ShuffleMapStage0和ShuffleMapStage2,所以不能立即提交调度阶段运行,把ReusltStage3放入到等待队列中等待waitingStages中。
递归调用submitStage方法可以知道ShuffleMapStage0不存在父调度阶段,而ShuffleMapStage2存在父调度阶段ShuffleMapStage1,这样ShuffleMapStage2加入到等待执行调度阶段列表waitingStages中,而ShuffleMapStage0和ShuffleMapStage1两个调度阶段作为第一次调度使用submitMissingTasks方法运行。
Executor任务执行完成时发送消息,DAGScheduler等调度器更新状态时,检查调度阶段运行情况,如果存在执行失败的任务,则重新提交调度阶段;如果所有任务完成,则继续提交调度阶段运行。由于ReusltStage3的父调度阶段没有全部完成,第二次调度阶段只提交ShuffleMapStage2运行。
当ShuffleMapStage2运行完毕之后,此时ResultStage3的父调度阶段全部完成,提交该调度运行完成。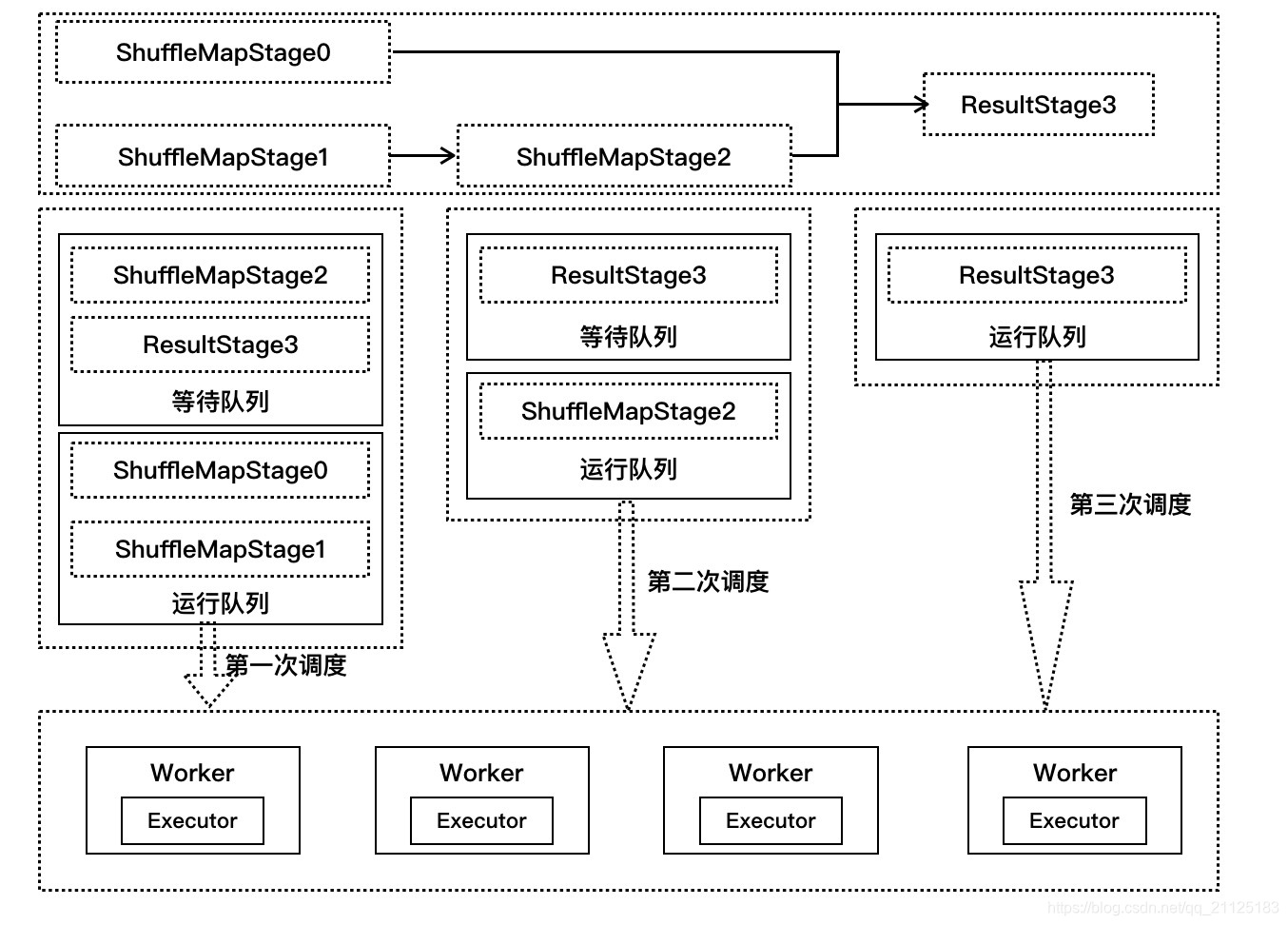
五 提交任务
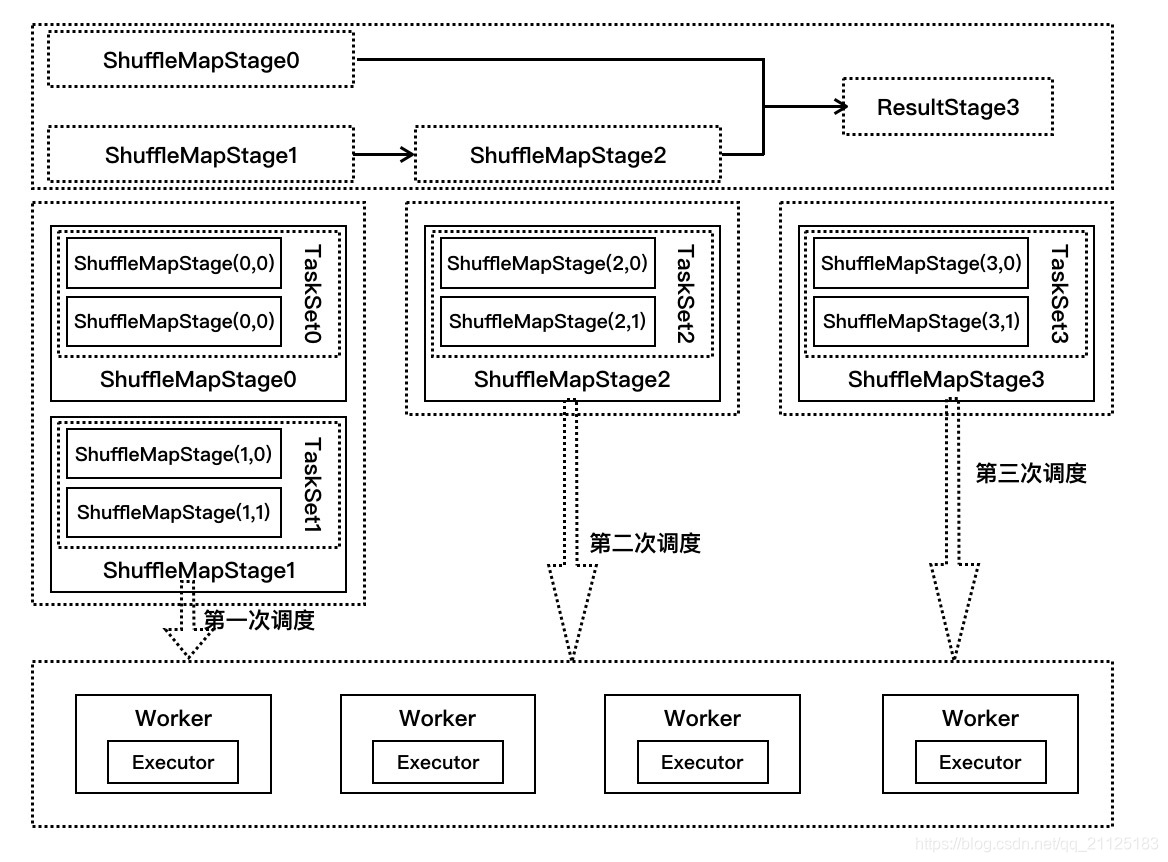
- 在提交stage中,第一次调用的是ShuffleMapStage0【ShuffleMapStage0会拆分成ShuffleMapStage(0,0), ShuffleMapStage(0,1),同理ShuffleMapStage1也会拆分出两个任务】和ShuffleMapStage1,假设每个stage都只有两个partition,ShuffleMapStage0是TaskSet0,ShuffleMapStage1是TaskSet1,每个TaskSet都有两个任务在执行。
- TaskScheduler收到发送过来的任务集TaskSet0和TaskSet1,在submitTasks方法中分别构建TaskSetManager0和TaskSetManager1,并把它们两放到系统的调度池,根据系统设置的调度算法进行调度(FIFO或者FAIR)
- 在TaskSchedulerImpl的resourceOffers方法中按照就近原则进行资源分配,每个任务均分配运行代码,数据分片,处理资源。使用CoarseGrainedSchedulerBackend的launchTasks方法把任务发送到Worker节点上的CoarseGrainedExecutorBackend调用其Executor来执行任务
- ShuffleMapStage0,ShuffleMapStage1执行完毕,ShuffleMapStage2,ResultStage3会执行1-3步骤,但是ReduceStage3生成的是ResultTask
六 执行任务
当CoarseGrainedExecutorBackend接收到LaunchTask消息时,会调用Executor的launchTask方法进行处理。在Executor的launchTask方法中,初始化一个TaskRunner来封装任务,它用于管理任务运行时的细节,再把TaskRunner对象放入到ThreadPool中去执行。
对于ShuffleMapTask, 它的计算结果会写到BlockManager之中,最终返回给DAGScheduler的是一个MapStatus。该对象管理了ShuffleMapTask的运算结果存储到BlockManager里的相关存储信息,而不是计算结果本身,这些存储信息将会成为下一阶段的任务需要获得的输入数据时的依据。
