在解决实际问题的过程中,我们会倾向于用复杂的模型来拟合复杂的数据,但是使用复杂模型会产生过拟合的风险,而正则化就是常用的减少过拟合风险的工具之一。
过拟合
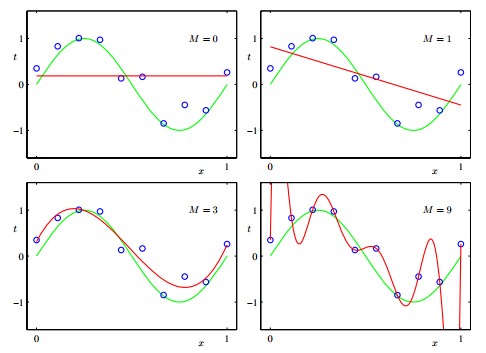
过拟合是指模型在训练集上误差很小,但是在测试集上表现很差(即泛化能力差),过拟合的原因一般是由于数据中存在噪声或者用了过于复杂的模型拟合数据。如下图所示,下图中的训练样本是三次多项式加了点噪声得到的,然后用不同的多次项拟合,M代表最高次项次数,下面四个图中M=0和M=1由于使用的过于简单的模型,没有能够很好地拟合训练数据,属于欠拟合。但是在M=3和M=4两个模型中,M=3有一点点的训练误差,但是在测试集上会取得不错的效果;而M=9则完全没有训练误差,但是训练出来的模型大大偏离了他的实际模型,这就是所谓的过拟合。
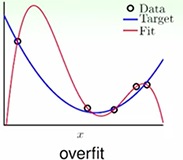
奥卡姆剃刀原理说,在所有能解释数据的模型中,越简单的越靠谱。但是为了拟合复杂的数据,不得不采用更复杂的模型,那么有没有一种办法,能以一种相对比较简单的模型来拟合复杂数据,答案是有,这就是正则化方法。
正则化假设
拿多项式回归举例,在多项式回归中,我们的目标是最优化的最小二乘误差(least square error ),但是通常在优化目标后面会看到一个w的平方项,或者w的绝对值的表达式,这个就是正则化项。其中,w的二次方回归叫做ridge regression,w的绝对值项叫做lasso regression。
这两个多项式目的都是用于减少过拟合的风险,但是也有细微差别。Ridge Regression得到的w长度比较小,而Lasso Regression得到的w是稀疏的,下面来看下对这两种方法为什么可以使得模型变简单并且减小过拟合的风险的分析。
正则化原理及推导
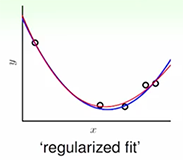
先来看下面两个图,第一个使用了最高十次项的多项式拟合,第一个图中可以看出红色的线很好的拟合了样本中的所有点,但是并不是理想的拟合,似乎泛化能力很弱。第二个图在第一个图的基础上加了L2正则项(Ridge Regression),得到了一个相对理想的模型。
这里先写下十次项多项式和target的二次项多项式的hypothesis
从上面两个式子中可以看出,H_10的假设集合是包含H_2的假设集合的,因为,如果在H_10中把w_3…w_10都设为0,得到的就是H_2的集合,所以可以理解为二次多项式就是十次多项式对w加上一些限制得到的。也就是说,我们的目标是从十次多项式中,找出w_3到w_10都为0的假设,就可以得到我们的目标二次多项式。如果条件放宽松点,把w的长度规定在C以内,即 wTw<CwTw<C ,则会有更大的可能找出w_3..w_10都为0的假设。这应该就是这个正则化名词的由来吧,就是说把w限制在一定的范围之内。
我们求解的问题就是
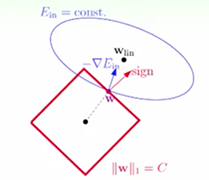
把上面两个带约束的假设化成图就是如下图所示(假设w是二维的),L2就是在一个w空间中加了一个球星区域的约束,所有在这个球形区域内找最优解,而L1就是在这个菱形区域找最优解。
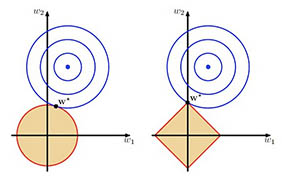
如果没有约束,对于凸函数,我们常用梯度下降法,每次往梯度方向走一小步,直到不能走为止,现在在这里加上了限制,先来看L2正则,想象一个球往山谷里滚下去,现在只能滚在这个圆形区域内,如果谷底在这个圆形区域内,那么没什么问题。如果谷底在圆形区域外,则小球最后肯定会落在圆形边界上,而且小球最后停着的点的梯度方向,和w的方向肯定是平行的(如果不平行,肯定会有一个垂直w的分量,把小球往另一侧拉,如下图的绿色箭头)。 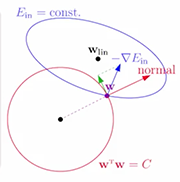
由于梯度和w平行,那么最后优化的结果是
上式中,因为梯度加后面一项等于0,那干脆把两项和看成梯度,那么原来带约束的优化目标可以写成:
上式就是,开头说的E_in后面加上了L2正则项的结果。
再来看L1正则,它的约束区域是正的菱形,同理,做梯度下降,最后小球落到的地方的梯度平行于w(概率很小,几乎不可能)或者小球滚到菱形的点上,菱形的点落在某条轴上方,而某条轴上的点只有一个维度上是非零,其余都是零,这就是为什么L1正则化最后的结果w是稀疏的。
总结
正则化的一般形式是误差加上一个正则项如
这里 λλ 可以理解为对约束区域的半径的倒数,即 λλ 越大则小球可以滚动的区域越小,越不容易发生过拟合,但是同时也可能会导致欠拟合,这个可以在实际使用中尝试不同参数,找出最好的 λλ 值。
另外,L1正则项是用于得到稀疏的w,L2正则项用于得到长度比较小的w,在实际使用过程中这两个可以结合着用,正则化理论在其机器学习领域有着很广泛的应用,是一个值得掌握的工具
转载 https://blog.csdn.net/jackie_zhu/article/details/52134592