文章目录
- Density Estimation
- Problem Motivation
- Gaussian Distribution
- Algorithm
- Building an Anomaly Detection System
- Developing and Evaluating an Anomaly Detection System
- Anomaly Detection vs. Supervised Learning
- Choosing What Features to Use
- Multivariate Gaussian Distribution
- Predicting Movie Ratings
- Collaborative Filtering
- Low Rank Matrix Factorization
Density Estimation
Problem Motivation
异常检测:给定m个假定正常的数据集,对x的分布概率建模,建立概率模型之后,对于新的数据概率低于阈值就是异常的

异常检测的应用:
- 欺诈检测
- 产品的质量控制
- 数据中心的计算机监测

Gaussian Distribution
样本出现的概率符合下列公式就是高斯分布,其中 是标准差, 是均值

Algorithm
独立分布的概率,等于概率的乘积
在异常检测算法中,即使独立的假设不成立,该算法的效果也还可以

异常检测算法步骤:

Building an Anomaly Detection System
Developing and Evaluating an Anomaly Detection System
与监督学习一样,将样本分为三个部分训练集、交叉验证集、测试集,
不同之处在于训练集是无标签的,都是正常的数据,交叉验证集和测试集是有标签的正常的数据和异常的数据均包含

下图就是数据集的分割,第二种方法也可行但不推荐

由于数据样本的不均衡,所以要使用召回率和置信度进行评价算法

Anomaly Detection vs. Supervised Learning
异常检测和监督学习的对比
| Anomaly Detection | Supervised Learning |
|---|---|
| 数据具有倾斜性,正的数据较少, 负的数据较多 | 大量的正的和负的数据 |
| 很多不同种类的异常数据,任何算法都很难从假设的例子中了解异常是什么样子的,出现的异常可能并没有出现过 | 充足的正的数据可以让算法了解正的样本是什么样的,未来出现的正的样本很可能是训练集中的 |
异常检测和监督学习的应用对比
| Anomaly Detection | Supervised Learning |
|---|---|
| 欺诈检测 | 垃圾邮件分类 |
| 生产检测 | 天气预测 |
| 数据中心监测机器 | 癌症检测 |
Choosing What Features to Use
异常检测是使用高斯模型对特征向量建模,但有些特征不符合高斯分布,虽然算法可以正常运行,但如果对这些
特征进行处理使其符合高斯分布,算法表现会更加好,处理的方法有取对数、开方等
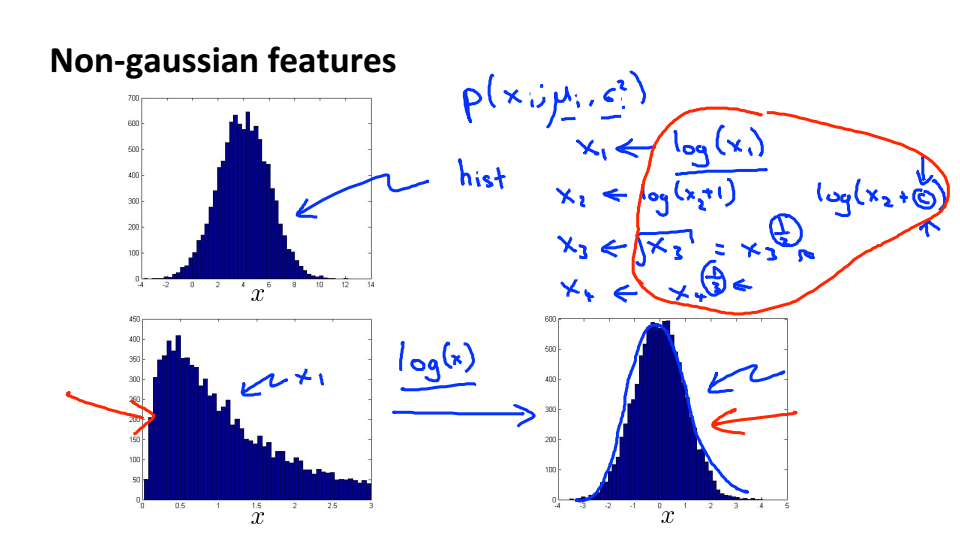
选择特征要选择异常情况下非常大或非常小的特征向量

Multivariate Gaussian Distribution
Multivariate Gaussian Distribution
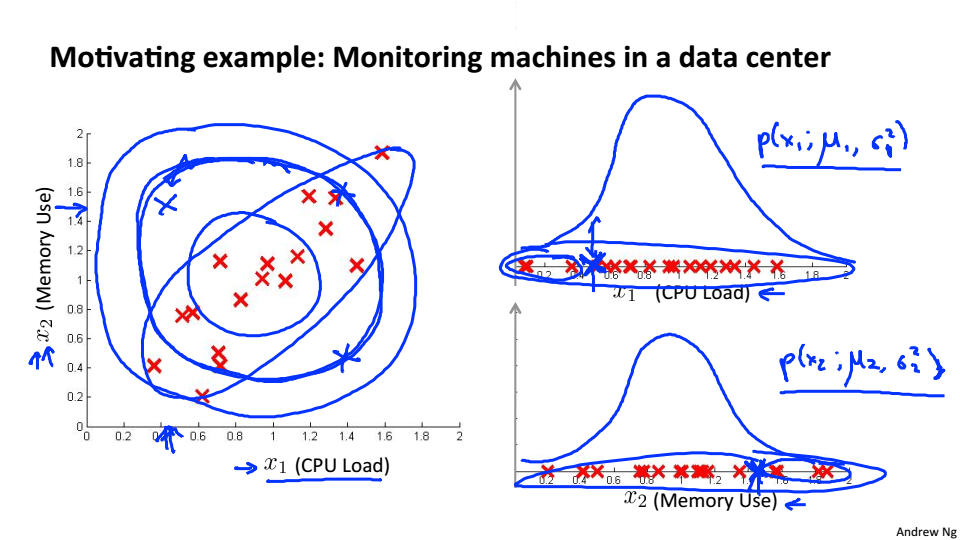
对于计算机监测的例子:当低CPU占用,高内存占用时,使用上述的异常检测可能将该情况作为正常情况,上述
的异常检测是圆形的,在同一个圆上认为是同一概率,所以要使用多元高斯分布
多元高斯分布不是将特征独立的建模

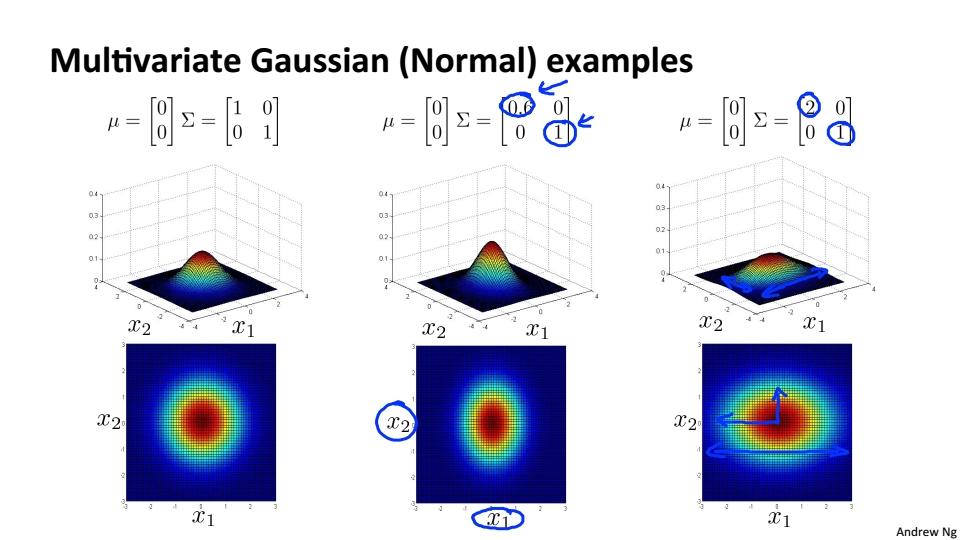
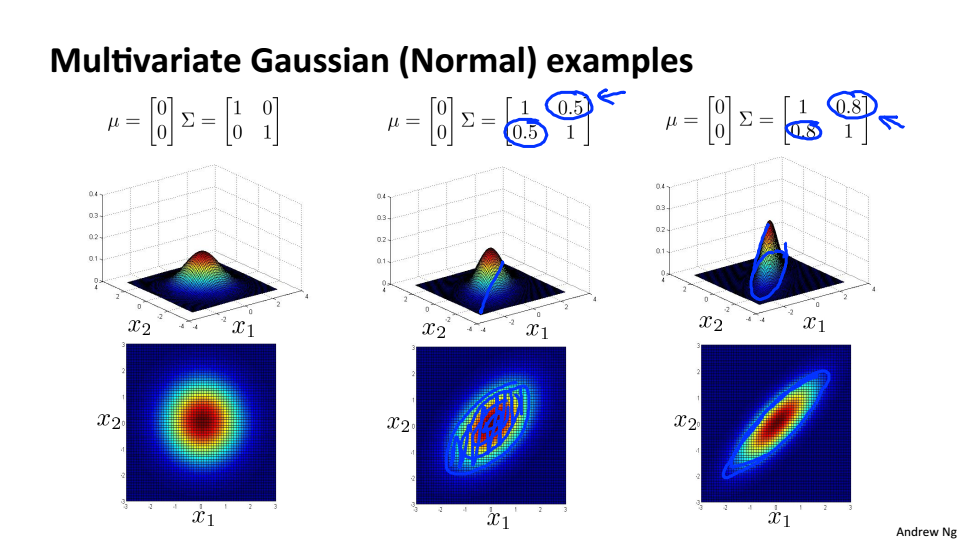
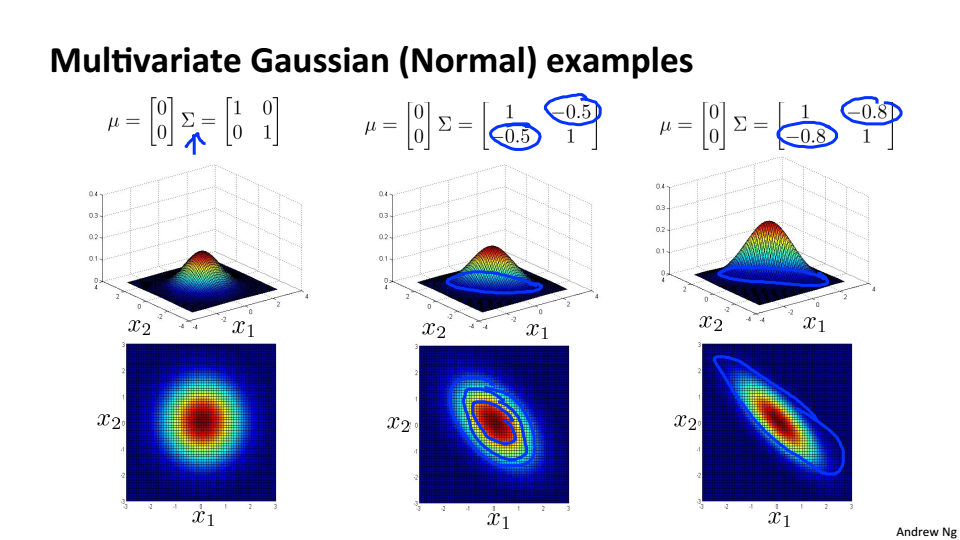
多元高斯分布的例子
协方差相同,相互独立,与普通高斯分布相同
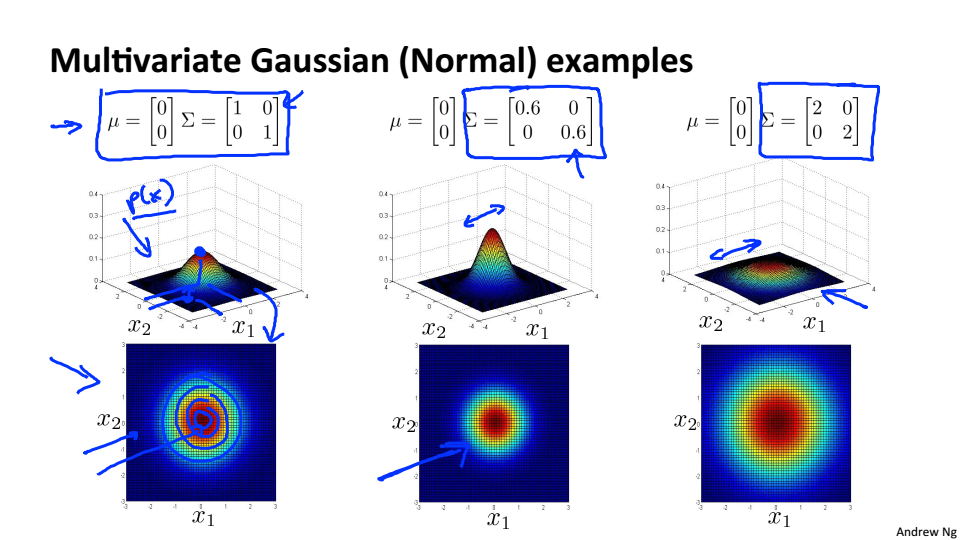
协方差不同,特征相关
正相关
负相关

Anomaly detection using the multivariate Gaussian Distribution
使用多元高斯模型建模

传统高斯模型和多元高斯分布模型的关系协方差矩阵对角线上的值其实就是方差

高斯分布和多元高斯分布对比
| Original model | Multivariate Gaussian |
|---|---|
| 当特征相关时需要手动的创建新特征去捕获这种情况 | 自动寻找特征间的相关性 |
| 所需的计算资源少 | 所需的计算资源多 |
| 训练集的数量可以很小 | 训练集的数量必须大于特征数 |

Predicting Movie Ratings
Problem Formulation
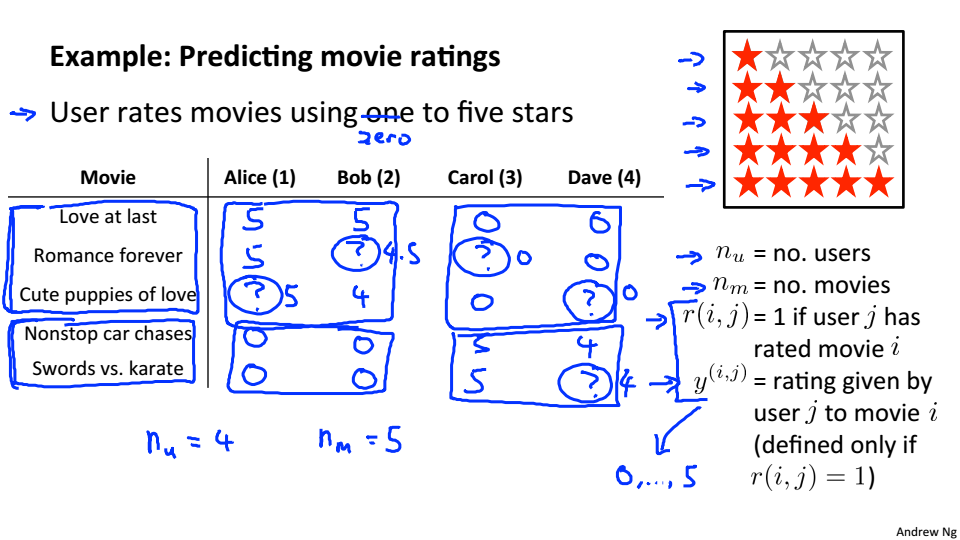
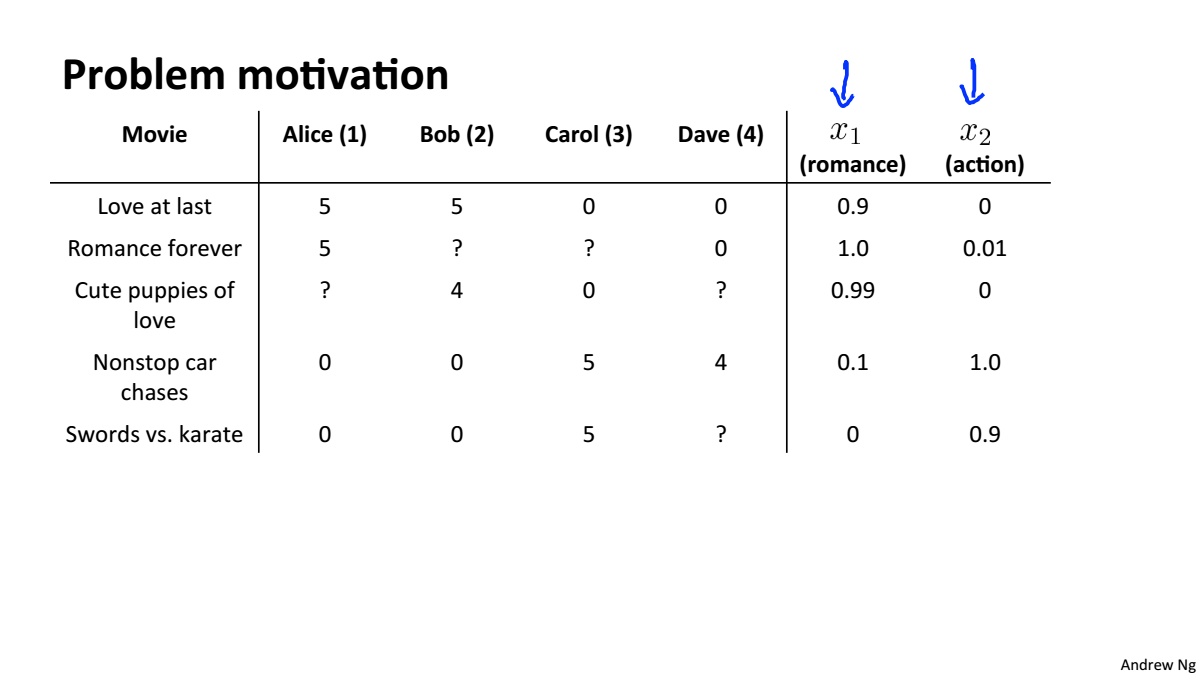
电影评分数据
Content Based Recommendations
符号说明

线性回归
梯度下降

使用线性回归进行预测,需要收集电影的特征数据,这是非常困难的,所以下一节介绍协同过滤
Collaborative Filtering
Collaborative Filtering
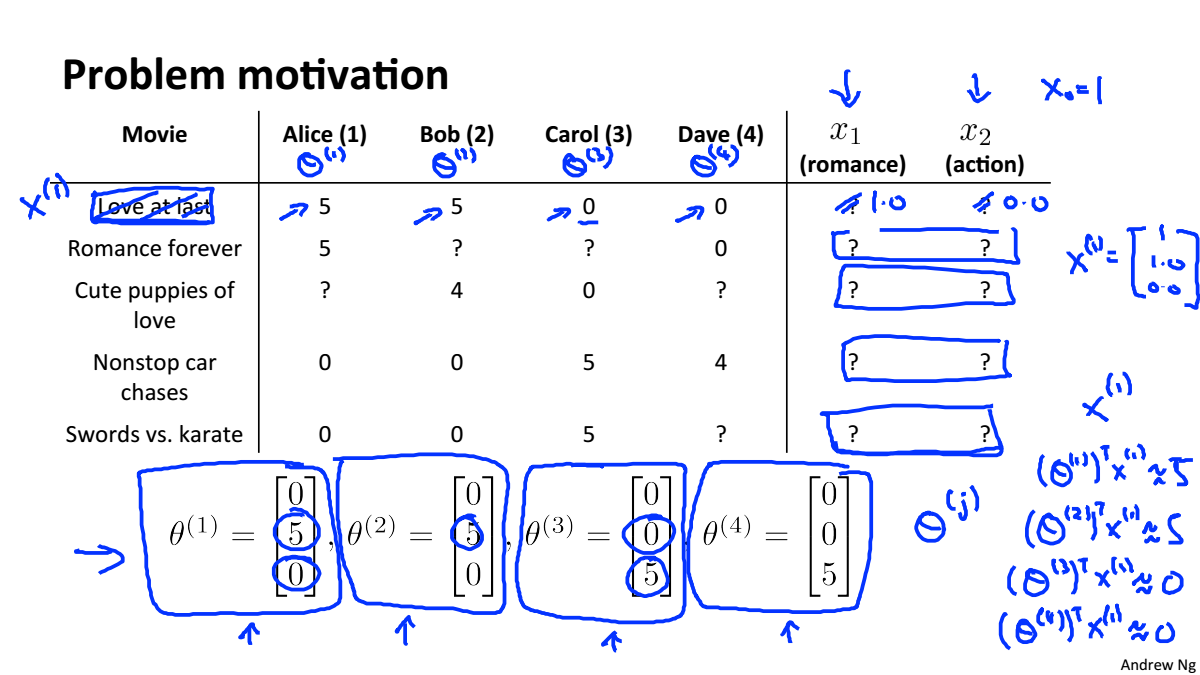
对于每个电影我们要知道该电影的动作指数是多少浪漫指数是多少,这件事是很难的,但我们可以很容易的知道
用户喜欢什么类型的电影
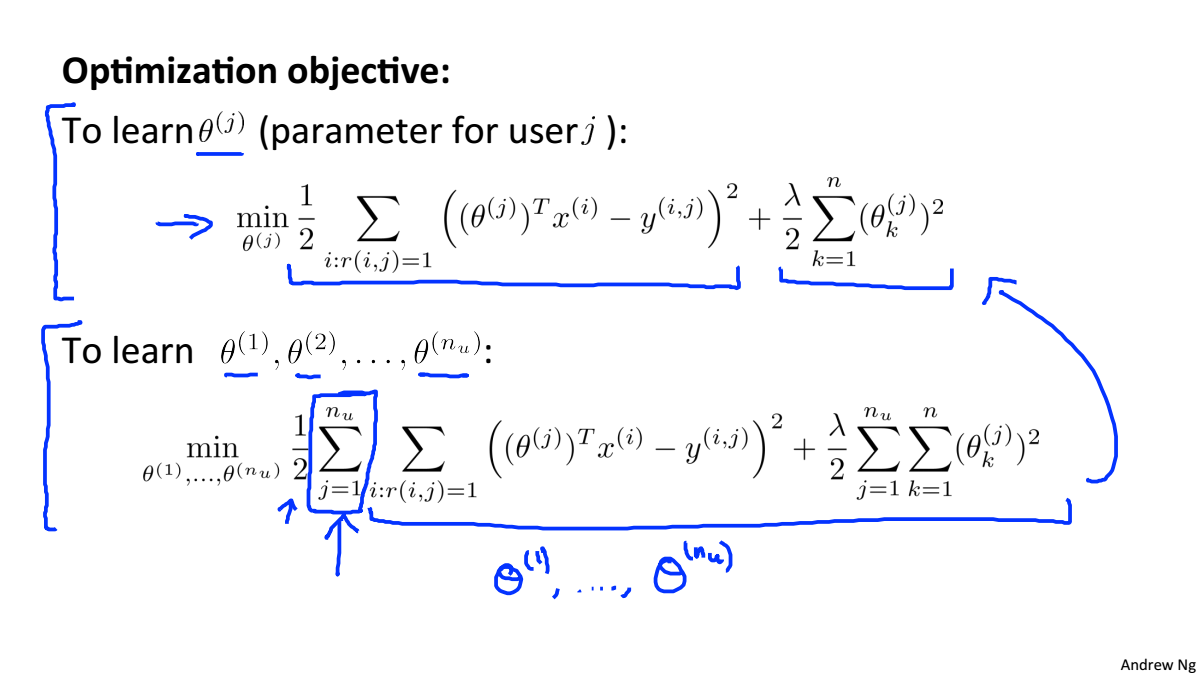
优化目标
Collaborative Filtering Algorithm
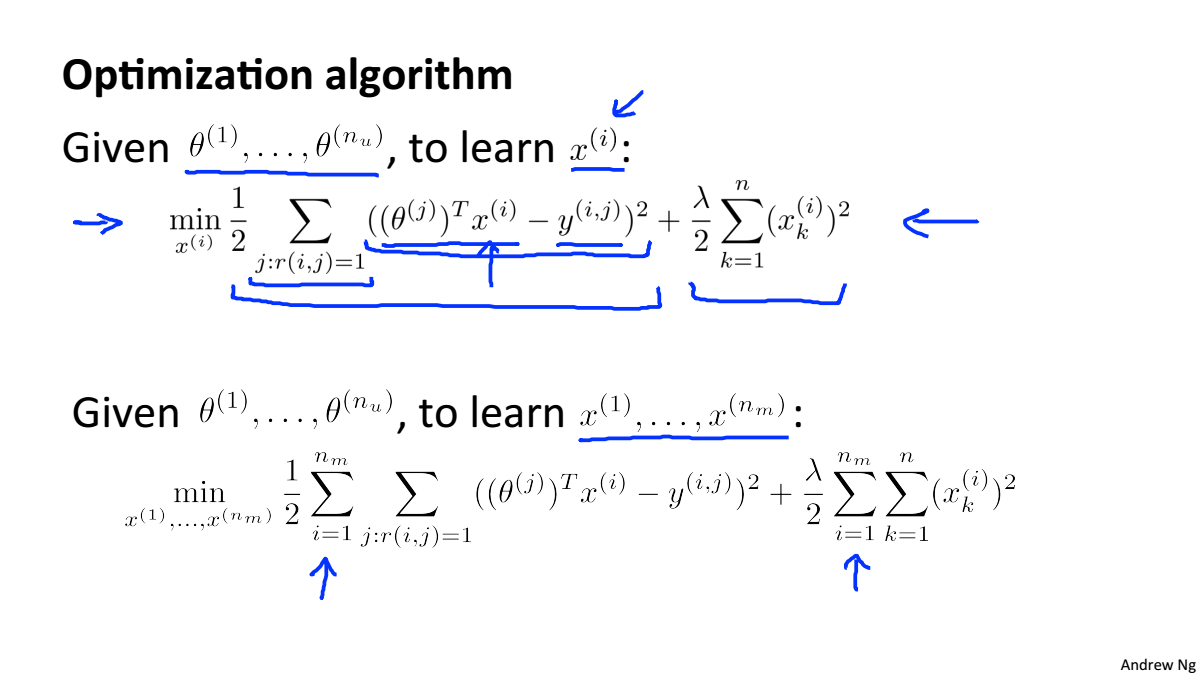
如果给你几个特征去表示电影,我们可以使用这些特征去获取用户的参数数据
如果给你用户的参数数据,你可以使用这些资料去获得电影的特征
将两者合一就是协同过滤算法
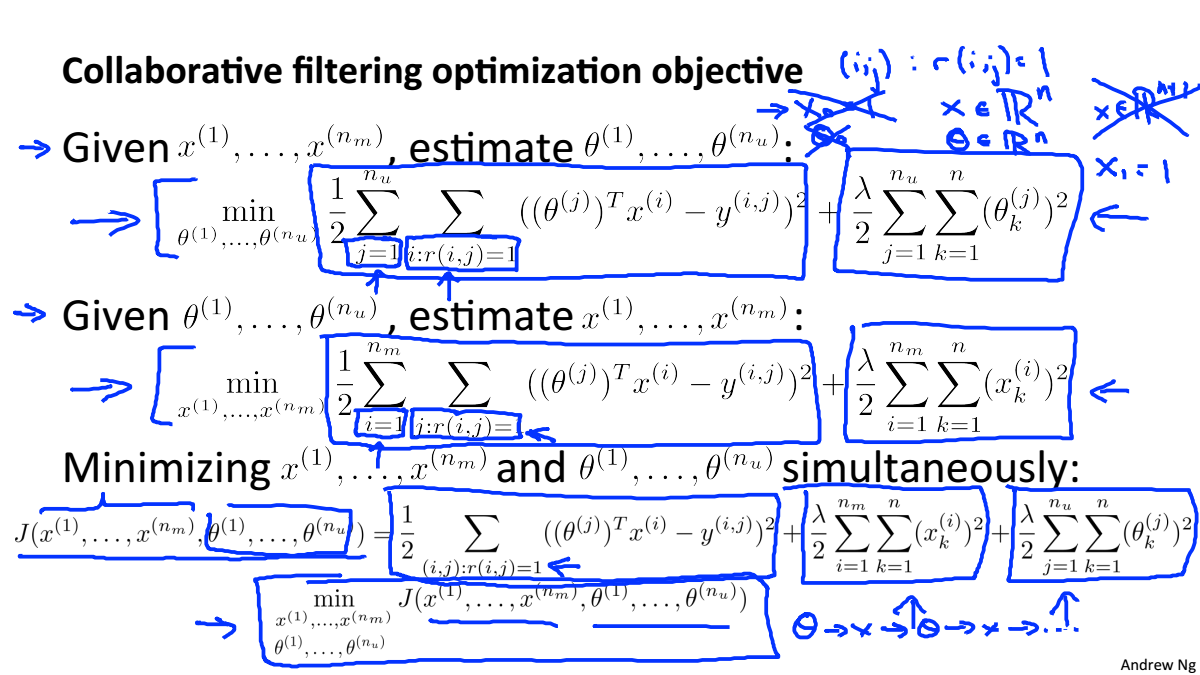
同时进行梯度下降

Low Rank Matrix Factorization
Vectorization: Low Rank Matrix Factorization
协同过滤的向量实现
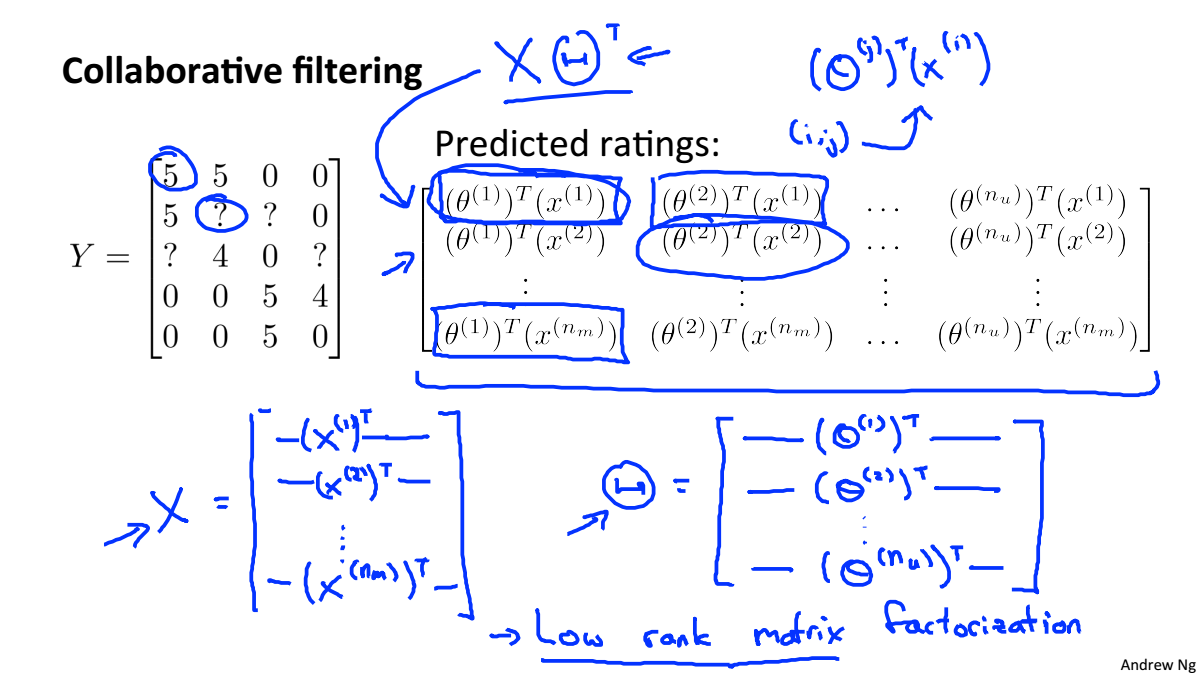
对于每个电影已经得到了特征,就可以寻找相关的电影

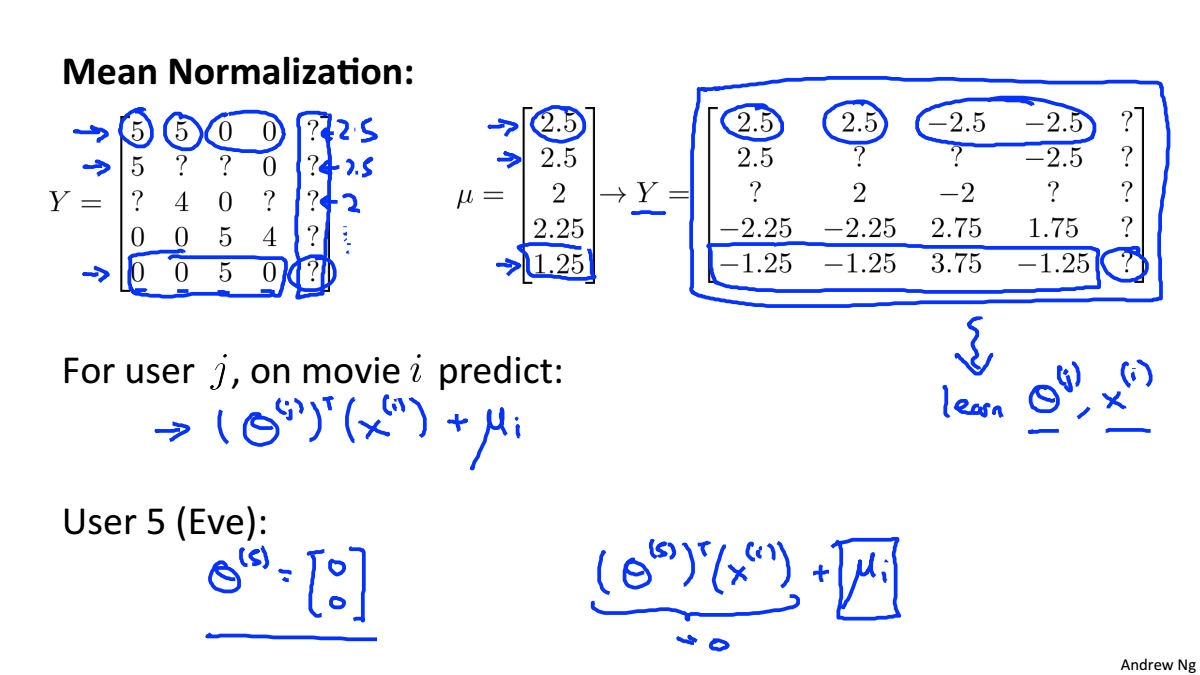
Implementational Detail: Mean Normalization
当用户没有给任何电影评分时,所以r(i,j)=0,对参数影响的只有正则化项,为了最小化代价函数,所以最后参数均
为0,所以预测结果均为0,这对于推荐是没有任何意义的
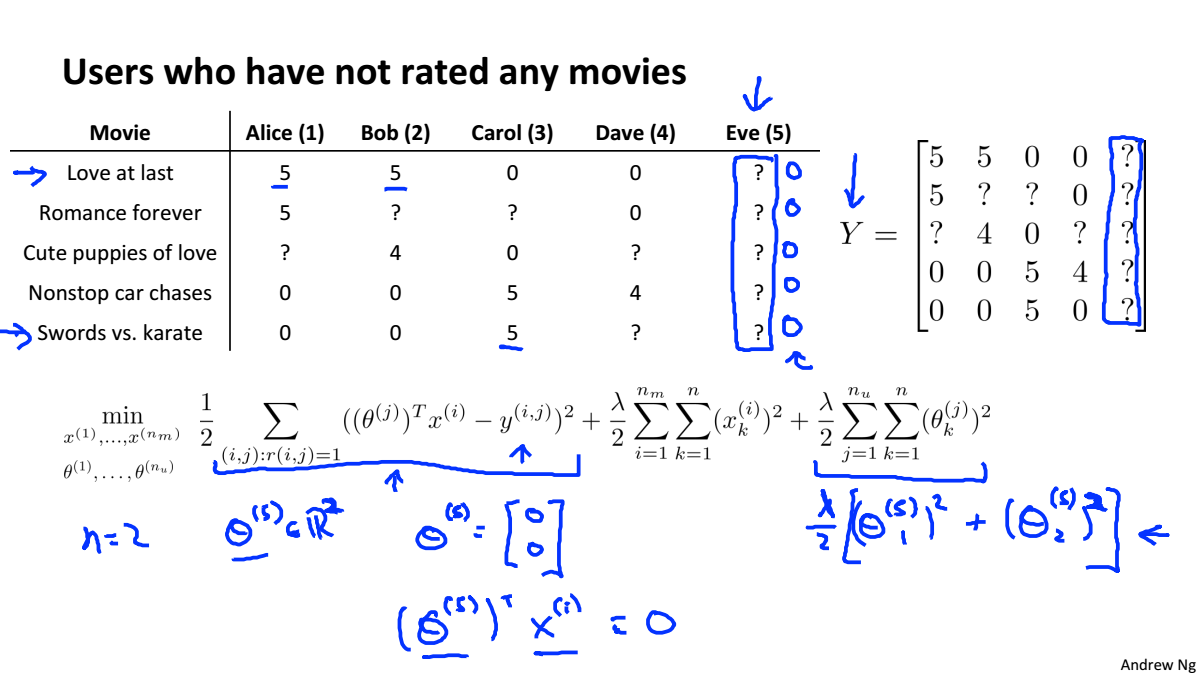
均值归一化就是为了解决上述问题,计算每个电影的平均分,将每个评分减去平均分
如果电影没有评分对列进行均值归一化