在之前的XGBoost原理理解中已经推导过XGBoost的决策树的分裂增益为
Lsplit=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ihi+λ(∑i∈Igi)2]−γ其中
λ是二阶正则化系数,
γ是一阶正则化系数。因为我们计算这个的目的只是想比较哪个作为分割点会比较好,因此只用关心相对数值,所以可以忽略常数的影响继而可以写为
Gain=HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2−γ
而在LightGBM的原始论文中,这个增益的定义3.1由体现,是通过分裂后的方差来度量的,和XGBoost还是有点差别,如下图
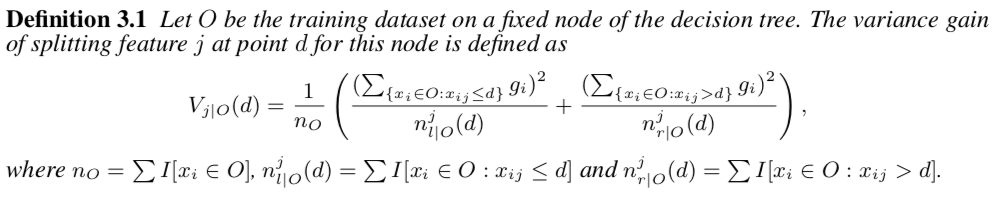 虽然和XGBoost大致意思差不多,分子都是一阶梯度的平方项,但是想看看究竟是不是一样的,要是不一样差别在哪里,所以这里分析了一下GitHub上LightGBM的源码LightGBM/src/treelearner/feature_histogram.hpp
虽然和XGBoost大致意思差不多,分子都是一阶梯度的平方项,但是想看看究竟是不是一样的,要是不一样差别在哪里,所以这里分析了一下GitHub上LightGBM的源码LightGBM/src/treelearner/feature_histogram.hpp
ThresholdL1:L1阈值(源码446行)
static double ThresholdL1(double s, double l1) {
const double reg_s = std::max(0.0, std::fabs(s) - l1);
return Common::Sign(s) * reg_s;
}
其中
s就是上述
G2,即一阶导数之和,因此输出为:
sign(s)∗max{0,∣s∣−l1}
CalculateSplittedLeafOutput:计算分裂节点的输出(源码451行)
static double CalculateSplittedLeafOutput(double sum_gradients, double sum_hessians, double l1, double l2, double max_delta_step) {
double ret = -ThresholdL1(sum_gradients, l1) / (sum_hessians + l2);
if (max_delta_step <= 0.0f || std::fabs(ret) <= max_delta_step) {
return ret;
}
else {
return Common::Sign(ret) * max_delta_step;
}
}
一般情况(小于等于叶子的最大输出或这个最大输出小于等于0时)则输出:
−sum_hessians+l2sign(sum_gradients)∗max{0,∣sum_gradients∣−l1}目前为止这些计算都还不是我们熟悉的格式,从下面开始就能得到叶子的增益就可以看出来和XGBoost的差别了。
GetLeafSplitGainGivenOutput:给定输出结果得到叶子当前的增益(源码503行)
static double GetLeafSplitGainGivenOutput(double sum_gradients, double sum_hessians, double l1, double l2, double output) {
const double sg_l1 = ThresholdL1(sum_gradients, l1);
return -(2.0 * sg_l1 * output + (sum_hessians + l2) * output * output);
}
这里的output就是上述计算出来的输出,因此带入可以得到:
−(2∗sg_l1∗(−sum_hessians+l2sg_l1)+(sum_hessians+l2)∗(−sum_hessians+l2sg_l1)2)=−(−2∗sum_hessians+l2sg_l12+sum_hessians+l2sg_l12)=sum_hessians+l2sg_l12=sum_hessians+l2(∣sum_gradients∣−l1)2
这个和XGBoost的
−H+λG2还是有些微差别的,我们接着看分裂之后的增益。
GetSplitGains:得到分裂后的增益(源码460行)
private:
static double GetSplitGains(double sum_left_gradients, double sum_left_hessians,
double sum_right_gradients, double sum_right_hessians,
double l1, double l2, double max_delta_step,
double min_constraint, double max_constraint, int8_t monotone_constraint) {
double left_output = CalculateSplittedLeafOutput(sum_left_gradients, sum_left_hessians, l1, l2, max_delta_step, min_constraint, max_constraint);
double right_output = CalculateSplittedLeafOutput(sum_right_gradients, sum_right_hessians, l1, l2, max_delta_step, min_constraint, max_constraint);
if (((monotone_constraint > 0) && (left_output > right_output)) ||
((monotone_constraint < 0) && (left_output < right_output))) {
return 0;
}
return GetLeafSplitGainGivenOutput(sum_left_gradients, sum_left_hessians, l1, l2, left_output)
+ GetLeafSplitGainGivenOutput(sum_right_gradients, sum_right_hessians, l1, l2, right_output);
}
可以看出来分裂后的增益就是左子树的增益加上右子树的增益,即
sum_left_hessians+l2(∣sum_left_gradients∣−l1)2+sum_right_hessians+l2(∣sum_right_gradients∣−l1)2
最后调用FindBestThresholdSequence函数找到增益最大的分裂bin
因为代码太长了这里就不放了,但是可以知道最后分裂之后的增益就是分裂前的和分裂后之差,即
sum_left_hessians+l2(∣sum_left_gradients∣−l1)2+sum_right_hessians+l2(∣sum_right_gradients∣−l1)2−sum_hessians+l2(∣sum_gradients∣−l1)2
与XGBoost的增益对比(
λ相当于
l2,
γ当于
l1)
Gain=HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2−γ虽然L1正则化系数的位置有所不同,但大体上这两种增益差不太多,L1和L2所起的效果也是同样的。
参考资料:
GitHub:LightGBM源码
LightGBM源码阅读+理论分析(处理特征类别,缺省值的实现细节)
