本篇文章主要参考柯国霖大神在知乎上的回答,以及自己阅读LGBM的部分源码整理而来。
1、one-hot编码弊端
one-hot编码是处理类别特征的一个通用方法,然而在树模型中,这可能并不一定是一个好的方法,尤其当类别特征中类别个数很多的情况下。主要的问题是:
①可能无法在这个类别特征上进行切分(即浪费了这个特征)。使用one-hot编码的话,意味着在每一个决策节点上只能使用one vs rest(例如是不是狗,是不是猫等)的切分方式。当类别值很多时,每个类别上的数据可能会比较少,这时候切分会产生不平衡,这意味着切分增益也会很小(比较直观的理解是,不平衡的切分和不切分没有区别)。
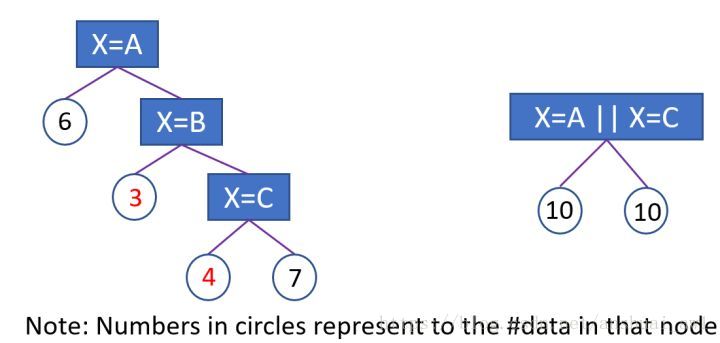
②会影响决策树的学习。因为就算可以在这个类别特征进行切分,也会把数据切分到很多零碎的小空间上,如图1左边所示。而决策树学习时利用的是统计信息,在这些数据量小的空间上,统计信息不准确,学习会变差。但如果使用如图1右边的分裂方式,数据会被切分到两个比较大的空间,进一步的学习也会更好。
图1右边叶子节点的含义是X=A或者X=C放到左孩子,其余放到右孩子。
2、LGBM处理分类特征
2.1 大致流程
为了解决one-hot编码处理类别特征的不足。LGBM采用了Many vs many的切分方式,实现了类别特征的最优切分。用Lightgbm可以直接输入类别特征,并产生如图1右边的效果。在1个k维的类别特征中寻找最优切分,朴素的枚举算法的复杂度是,而LGBM采用了如参考文献【1】的方法实现了
的算法。
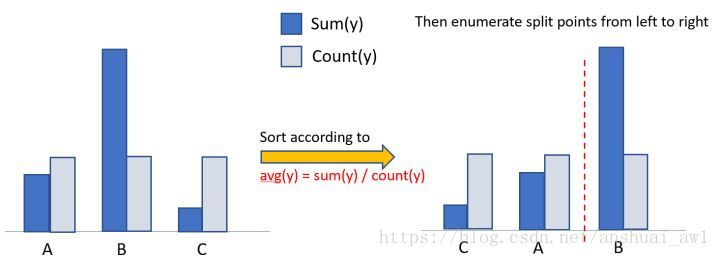
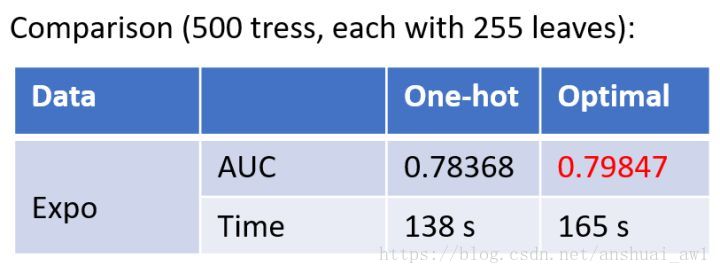
算法流程如图2所示:在枚举分割点之前,先把直方图按每个类别的均值进行排序;然后按照均值的结果依次枚举最优分割点。从图2可以看到,Sum(y)/Count(y)为类别的均值。当然,这个方法很容易过拟合,所以在LGBM中加入了很多对这个方法的约束和正则化。图3是一个简单的对比实验,可以看到该最优方法在AUC上提升了1.5个点,并且时间只多了20%。
2.2 详细流程
下面具体来讲下在代码中如何求解类别特征的最优切分的流程:
(feature_histogram.hpp文件中FindBestThresholdCategorical函数)
A. 离散特征建立直方图的过程:
统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器, 对于在bin容器内出现次数较少的特征值直接过滤掉,不建立bin容器。
B. 计算分裂阈值的过程:
B.1
先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
B.2
对于bin容器较多的情况, 先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 对每一个符合条件的bin容器进行公式计算(公式如下: 该bin容器下所有样本的一阶梯度之和 / 该bin容器下所有样本的二阶梯度之和 + 正则项(参数cat_smooth),这里为什么不是label的均值呢?其实上例中只是为了便于理解,只针对了学习一棵树且是回归问题的情况, 这时候一阶导数是Y, 二阶导数是1),得到一个值,根据该值对bin容器从小到大进行排序,然后分从左到右、从右到左进行搜索,得到最优分裂阈值。但是有一点,没有搜索所有的bin容器,而是设定了一个搜索bin容器数量的上限值,程序中设定是32,即参数max_num_cat。
LightGBM中对离散特征实行的是many vs many 策略,这32个bin中最优划分的阈值的左边或者右边所有的bin容器就是一个many集合,而其他的bin容器就是另一个many集合。
B.3
对于连续特征,划分阈值只有一个,对于离散值可能会有多个划分阈值,每一个划分阈值对应着一个bin容器编号,当使用离散特征进行分裂时,只要数据样本对应的bin容器编号在这些阈值对应的bin集合之中,这条数据就加入分裂后的左子树,否则加入分裂后的右子树。
参考文献:
【1】On grouping For maximum homogeneity
【2】https://www.zhihu.com/question/266195966