信息熵:
信息熵的概念很简单,熵在信息论中代表随机变量不确定的度量。
- 熵越大,数据的不确定性越高。
- 熵越小,数据的不确定性越低。
信息熵的公式:
下面的公式就是香农提出的信息熵的公式:
解释一下:
- 假如一组数据有k类信息,那么每一个信息所占的比例就是 。比如鸢尾花数据包含三种鸢尾花的数据,那么每种鸢尾花所占的比例就是 ,那么 、 、 就分别为 。
- 因为 只可能是小于1的,所以 始终是负数。所以需要在公式最前面加负号,让整个熵的值大于0。
信息增益:
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差。
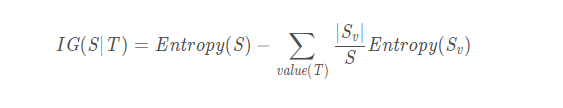

参考文档:https://www.devtalking.com/articles/machine-learning-15/
