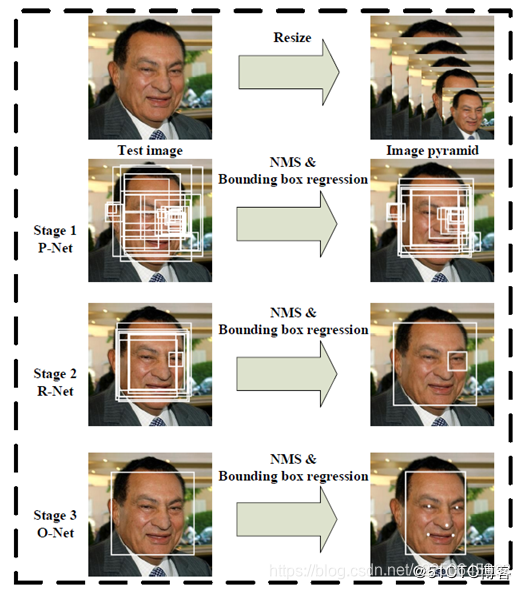
MTCNN是一个多任务学习的人脸检测和人脸对齐网络,整个模型分为三个阶段,第一阶段通过一个浅层的CNN网络快速产生一系列的候选窗口;第二阶段通过一个能力更强的CNN网络过滤掉绝大部分非人脸候选窗口;第三阶段通过一个能力更加强的网络找到人脸上面的五个标记点;完整的MTCNN模型级联如下:
MTCNN模型主要贡献在于:
1.提供一种基于CNN方式的级联检测方法,基于轻量级的CNN模型就实现了人脸检测与点位标定,而且性能实时。
2.实现了对难样本挖掘在线训练提升性能。
3.一次可以完成多个任务。
阶段方法详解
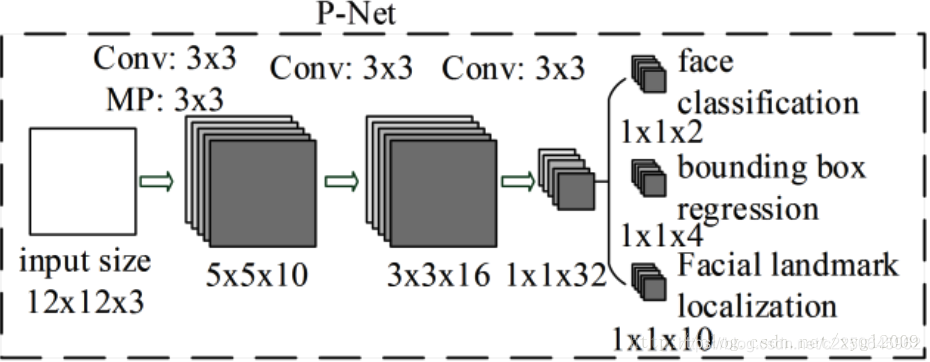
第一阶段 —Pnet
主要功能是获得脸部区域的窗口与边界Box回归,获得的脸部区域窗口会通过BB回归的结果进行校正,然后使用非最大压制(NMS)合并重叠窗口
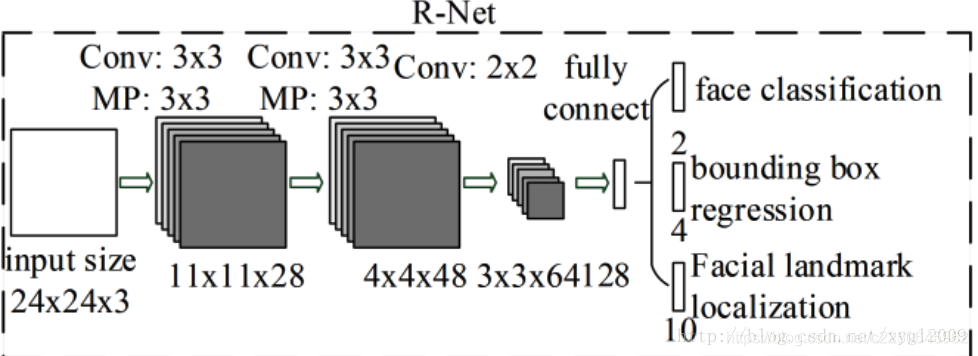
第二阶段—Rnet
细化处理阶段,过滤大量非人脸区域候选窗口,然后继续校正BB回归的结果,使用NMS进行合并。
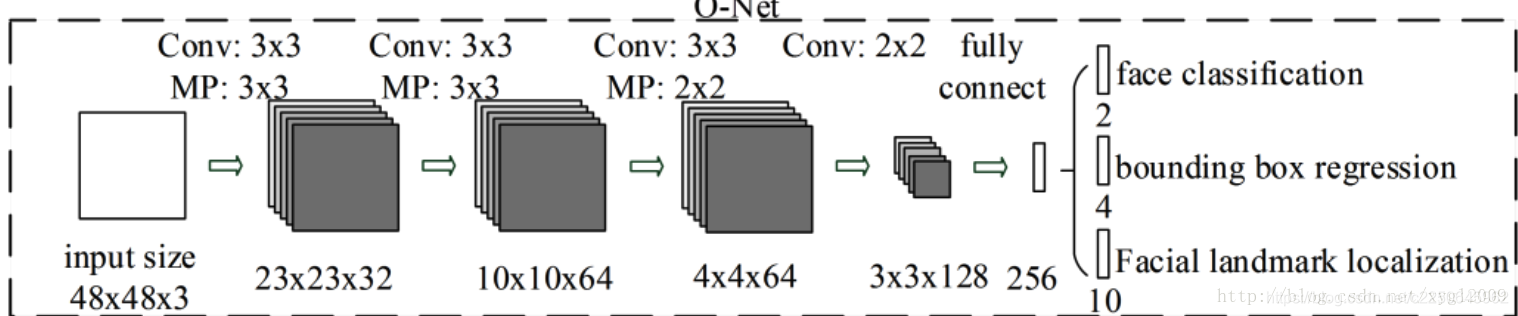
第三阶段—Onet
输入第二阶段数据进行更进一步的提取,最终输出人脸标定的5个点位置。
作者网络考量与设计
对于CNN网络架构,作者发现,影响网络性能额因素主要有两个:
- 样本的多样性,影响了网络的类别能力
- 人脸检测只是一个二分类任务(人脸 or 非人脸),所以人脸检测需要少量的滤波操作,需要更多对人脸的描述,也即每一层不需要太多filters(每层网络的feature maps个数不需要太多)。
基于上述两个因素,作者设计时每层的filter个数有限,但是它增加了整个网络的深度,这样做的好处是可以显著减少计算量,提升整个网络性能,同时全部改用3x3的filter更进一步降低计算量,在卷积层与全连接层使用PReLU作为非线性激活函数(输出层除外)。
网络训练
网络训练需要对三个目标完成收敛,
- 人脸二元分类
- 人脸BBOX回归
- 人脸五点特征位置回定位
人脸二元分类
对于每一个样本采用交叉熵损失:
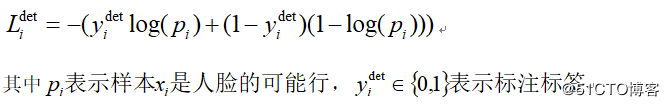
人脸BBOX回归
对每个候选窗口,计算它与标注框之间的offset,目标是进行位置回归,采用的是平方差损失:
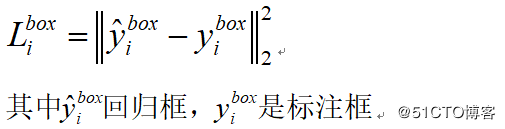
人脸五点特征位置回定位
人脸特征共计有五个点位坐标分别为左眼、右眼、鼻子、左嘴角、右嘴角,其损失与BBOX回归损失类似,计算的是候选坐标与真实坐标的最小化欧氏距离,每个点有两个坐标(x,y),所以人脸landmark是一个10维的特征向量。损失函数如下:

总损失函数
在网络训练中,上述的三个损失函数可能并不是全部都需要,所以整体的损失函数如下:
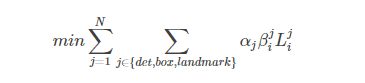
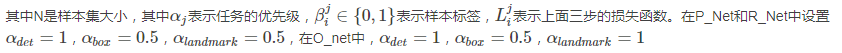
在P-Net中对人脸进行二元分类时候就可以在线进行难样本挖掘,在每个阶段网络前向传播时候对每个样本计算得到的损失进行排序(从高到低)然后选择70%进行反向传播,原因在于好的样本对网络的性能提升有限,只有那些难样本才能更加有效训练,进行反向传播之后才会更好的提升整个网络的人脸检测准确率。
训练阶段数据类型
- 负样本:并交比小于0.3
- 正样本:并交比大于0.65
- 部分脸:并交比在0.4~0.65之间
- Landmark脸:能够找到五个landmark位置的
其中正负样本用于训练人脸/非人脸,正样本和部分脸用于训练人脸BBOX的回归,Landmark脸用于训练人脸五个特征点位置的定位。
训练数据比例如下:
负样本:正样本:部分脸:Landmark脸 = 3:1:1:2
附摄像头实时监测程序:
capture = cv.VideoCapture(0)
height = capture.get(cv.CAP_PROP_FRAME_HEIGHT)
width = capture.get(cv.CAP_PROP_FRAME_WIDTH)
out = cv.VideoWriter("D:/mtcnn_demo.mp4", cv.VideoWriter_fourcc('D', 'I', 'V', 'X'), 15,
(np.int(width), np.int(height)), True)
while True:
ret, frame = capture.read()
if ret is True:
frame = cv.flip(frame, 1)
cv.imshow("frame", frame)
rgb = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
result = detection(rgb)
out.write(result)
c = cv.waitKey(10)
# 按下ESC键,退出
if c == 27:
break
else:
break
cv.destroyAllWindows()
