《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》论文解读。
本文来自于中国科学院深圳先进技术研究院,目前发表在arXiv上,是2016年4月份的文章,算是比较新的文章。
论文地址:
概述
相比于R-CNN系列通用检测方法,本文更加针对人脸检测这一专门的任务,速度和精度都有足够的提升。R-CNN,Fast R-CNN,FasterR-CNN这一系列的方法不是一篇博客能讲清楚的,有兴趣可以找相关论文阅读。类似于TCDCN,本文提出了一种Multi-task的人脸检测框架,将人脸检测和人脸特征点检测同时进行。论文使用3个CNN级联的方式,和Viola-Jones类似,实现了coarse-to-fine的算法结构。
框架
算法流程
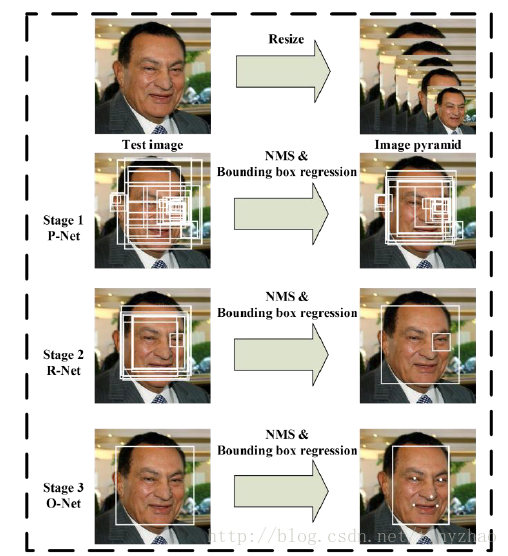
当给定一张照片的时候,将其缩放到不同尺度形成图像金字塔,以达到尺度不变。
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。全卷积网络和Faster R-CNN中的RPN一脉相承。
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置。
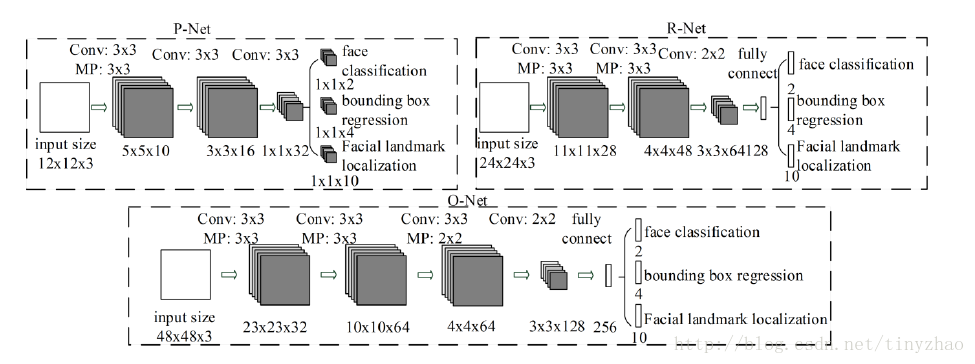
CNN结构
本文使用三个CNN,结构如图:
训练
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
(1)人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:
(2)Bounding box regression
这是一个回归问题,使用平方和损失函数:
(3)人脸特征点定位
这也是一个回归问题,目标是5个特征点与标定好的数据的平方和损失:
(4)多任务训练
不是每个sample都要使用这三种损失函数的,比如对于背景只需要计算
N是训练样本的数量。
(5)online hard sample mining
传统的难例处理方法是检测过一次以后,手动检测哪些困难的样本无法被分类,本文采用online hard sample mining的方法。具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
实验
本文主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
A、训练数据
本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
B、效果
本文的人脸检测和人脸特征点定位的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在Nvidia Titan达到99fps。
总结
本文使用一种级联的结构进行人脸检测和特征点检测,该方法速度快效果好,可以考虑在移动设备上使用。这种方法也是一种由粗到细的方法,和Viola-Jones的级联AdaBoost思路相似。
类似于Viola-Jones:1、如何选择待检测区域:图像金字塔+P-Net;2、如何提取目标特征:CNN;3、如何判断是不是指定目标:级联判断。
附录
在目标检测论文中,常出现的一些方法有Bounding box regression,IoU,NMS。这里具体介绍一下。
Bounding box regression
这边有个很好的答案了:
简单而言就是将预测的框移动到实际的框,输入特征是候选区域提取的特征,目标是两个框的变化值。
IoU
重叠度(IOU):
物体检测需要定位出物体的bounding box,就像下面的图片一样,我们不仅要定位出车辆的bounding box 我们还要识别出bounding box 里面的物体就是车辆。

对于bounding box的定位精度,有一个很重要的概念: 因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式:IOU。 它定义了两个bounding box的重叠度,如下图所示
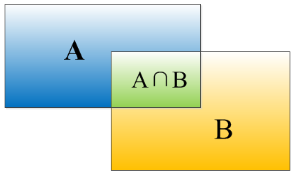
就是矩形框A、B的重叠面积占A、B并集的面积比例。
非极大值抑制(NMS):
RCNN会从一张图片中找出n个可能是物体的矩形框,然后为每个矩形框为做类别分类概率:

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二是邻域的大小。这里不讨论通用的NMS算法,而是用于在目标检测中用于提取分数最高的窗口的。例如在行人检测中,滑动窗口经提取特征,经分类器分类识别后,每个窗口都会得到一个分数。但是滑动窗口会导致很多窗口与其他窗口存在包含或者大部分交叉的情况。这时就需要用到NMS来选取那些邻域里分数最高(是行人的概率最大),并且抑制那些分数低的窗口。