最近开始进行人脸检测,所以根据自己的理解和别人的博客总结一下自己对人脸检测的认识,如果错误希望能够指出。
人脸检测的模型其实也有很多,简单点可以基于MNIST的网络模型进行对自己的检测,采用同样的网络模型,不同的数据进行训练会产生不同的作用,但这种情况往往无法进行泛化。也可以基于detect_object中的ssd_mobilenet网络为基础在里面加入一些人脸的数据和标签进行检测。开始的时候我找到了一个基于ssd_mobilenet的网络进行的,并将pb文件集成了移动端但是发现对于复杂的场景及效率都不是很高。后来得出的结论是这些小众的网络只适合用来根据自己的兴趣进行测试(因为没有理论支撑)。不能用来进行标准的人脸检测。
MTCNN网络是目前使用比较广泛的网络,它包含了人脸检测和人脸对齐。其中人脸检测可以用来进行后续的人脸识别。人脸对齐帮我们找出了人脸的眼睛,嘴,鼻子的位置可以用来进行对应的3D处理。 我们可以在文献地址中对文献进行下载。
MTCNN网络是一个三层网络结构,第一层pnet的结果经过bounding box regression和NMS处理之后变为24x24的大小放入第二层进行处理,第二层rnet处理后的结果同样经过bounding box regression 和NMS处理之后变成48x48的大小放入第三层onet网络进行处理,结果同样经过bounding box regression 和 NMS处理变成人脸框和面部标签输出。具体网络结构如下:
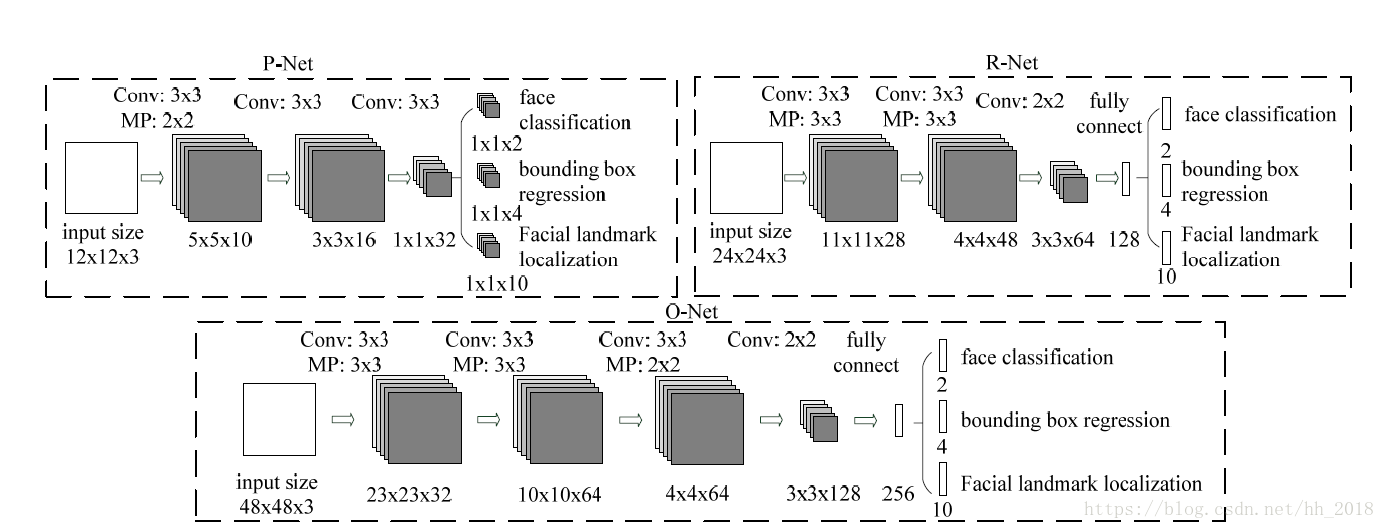
卷积计算使用的是步长为1,pading = "VALID"的方式,即:计算时划过每个点并且每个点都要取到,对于超过边界的点使用0表示。这样可以保证在计算过程中图片中的每个点都会被使用到。此时处理后的结果为R1-R2+1(R1为卷积计算前的大小,R2为卷积核的大小)。
池化采用的是步长为2,pading = "VALID"的方式,此时池化后的大小为1+x(x为R/2下取整数)。
对于MTCNN网络来说其输入的数据源是对应的图片金字塔。图片金字塔的意思就是我们根据不同的规模把图片分成不同的大小,这些图片就像金字塔一样将图片裁剪后堆起来。此时一张图片就相当于变成了多张,如下。然后对每一张图片分别放入到
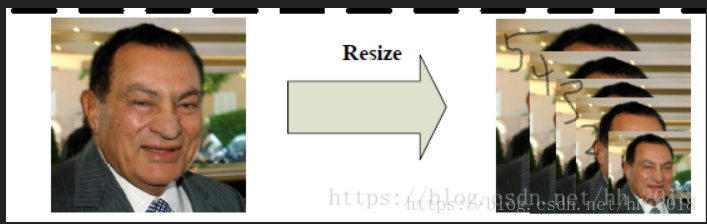
p网络中进行处理。并对处理后的结果进行NMS处理。由于一张图片被分成了很多张小的金字塔类型的图片。所以对处理后的图片整体进行一次NMS处理并最终生成对应的处理后的结果,然后对处理后的结果再进行R网络的处理,然后将结果进行NMS处理后再进行O网络的处理。生成最终的结果。
在卷积层计算之后采用的PRELU的激活函数,其激活函数的形式为:g(z) = max(0,z)+a * min(0,z)
在进行训练时采用了在线选取数据的方式,即对损失函数选取前70%的数据进行训练,因为后30%的数据对训练的影响会很小。
在数据选取方面采用IOU(选取的图片占真实人脸的比例)来进行。共分为4各部分:negative:IOU<0.3,Landmark face: IOU在0.3和0.4之间,part face:IOU在0.4到0.65之间,positve:IOU大于0.65。根据上述原则对数据进行划分并按照3:1:1:2的原则分配数据量。划分的主要目的是为了用来标记数据。