Dropout是一个非常好用的优化方法,然而它仅仅适用于全连接层,因为卷积层中的元素是空间相关的。当它应用到卷积层上时,即使消除了某些元素的部分权重和偏置,但这些元素在其它地方的权重和偏置也会将它的信息传递下去。为了解决这个方法,dropblock被提出了:它类似dropout,但它不止去除某一个元素,而是去除一个区域的元素,这样它就能在卷积层中发挥作用了。实验表明,它能够较好地提高模型准确度。
自从dropout被提出后,各种神经网络的归一化方法出现了。这些方法的思想是向神经网络中塞入各种各样的噪音,以防止它对训练数据过拟合。Dropblock的思想起源于cutout,它将输入图像的部分置零以让神经网络关注更多的特征来防止过拟合。而dropblock更进一步,它在每个特征图中都应用了cutout。
Dropblock的思路和dropout很像,其主要区别在于它不是丢弃独立的随机单元,而是丢弃特征途中连续的区域。其伪代码如下:

它的两个超参数为block_size和γ。前者决定了丢弃的块的大小,后者决定了丢弃多少激活的单元。经过实验,在每层使用不同的dropblock掩膜效果更好。
在实验中,我们往往在不同的特征图中都使用相同的block_size,然后使用下图公式计算γ:
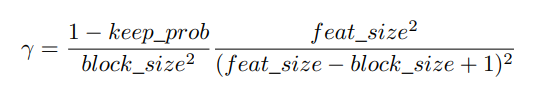
其中keep_prob即是dropout保留元素的概率,feat_size是整个图的大小。
怎么得到上述那个计算伽马的方程呢?作者首先令dropblock drop掉的元素数和传统dropout drop的元素数相同。而dropout drop掉的元素个数是(1-keep_prob)(feat_sizefeat_size)。而在dropblock中,首先我们要保证drop的元素都在图像范围内,也就是上图绿色范围,其面积为(feat_size-block_size+1)*feat_size-block_size+1)所以可能的中心点的个数就是(feat_size-block_size+1)*feat_size-block_size+1)*γ。而没drop一个中心点,其周围block_size大小的元素也要一并drop掉,我们假设这些drop掉的区域不互相重叠,那么总共drop掉的元素数即为(feat_size-block_size+1)feat_size-block_size+1)γblock_sizeblock_size。令其与dropout drop掉的元素数相同,即得到上式。
后面就是一些具体的实验超参数设置及效果对比。
