在量化方面已经有很多工作了,其中一个是用每个FC层的浮点的聚类中心值来代替所有权重值,可以获得20X的压缩率,以及在top-上1%的精度损失;hash网则将所有权重放入哈希桶内,且所有共享哈希桶的权重共享一个单精度值。但它只考虑了几种浅层网络的FC层;还有人提出了将剪枝、量化和霍夫曼编码结合的方法;还有人使用16位精度的权重来代替32位精度的权重来训练网络;之后还有EBP,它在推断的前向传播过程中,将其随机地转化为±1的形式;BinaryConnect进一步拓展了这个做法:它有两套网络权重,浮点型的和binary型的。浮点型的作为权重二元化的参考;另外还有BNN、异或网、TWN、124网和QNN(它将权值分块后聚类)。
但还是有两个问题没有解决:降低的精度,和为了收敛而增加的训练迭代次数。
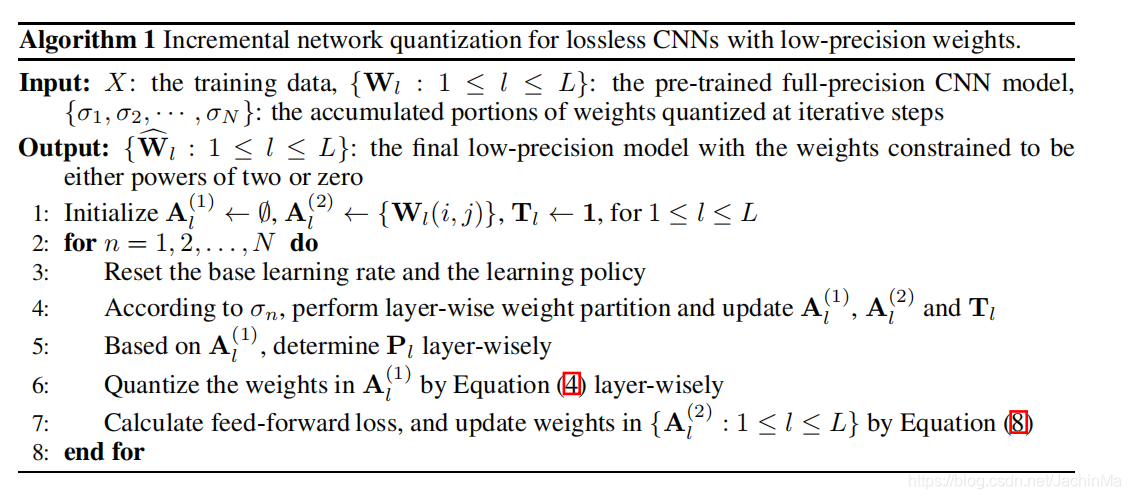
inq并不需要特殊的网络架构,它是一套训练方法,可以应用到任何一个预先训练好的CNN网络上。它总共分为三个部分:权重划分、逐组量化和重新训练。它将每一层的未量化的权重每次分为保持原样的和被量化的两部分,然后重新训练未被量化的权重,以弥补由量化导致的精度损失。如此重复,直到所有的权重都被量化完成。
量化后的权重值将从

中选取,其中n1和n2为整型数据,且n1≥n2。而n1和n2的设置为超参数,由于位宽b是确定的,所以我们只需要知道n1就可以了。一个被证明是有效的设置n1的公式是:

其中,floor函数为向下取整的函数
当Pl被确定下来后,就可以将权重转化为量化值了:
这里α和β是Pl里两个相邻的元素。
训练过程如下:
作者说他们的这一思想来源和剪枝的两篇文章里的思想有关(所以有时候了解一下其他领域的思想还是有必要的),那两篇文章的思想大概是去掉不重要的权重后再次训练,如此循环。
具体的训练三个步骤上面已经讲过了,其中权重划分的定义为:
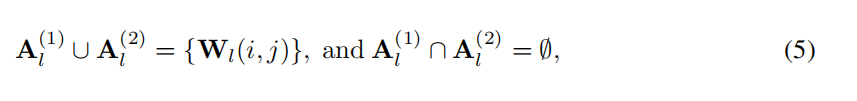
A1是要被量化的,A2是未被量化的,在下一步重训练中要被更新的。
损失函数如下
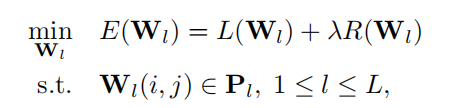
但因为我们将权重区分开,分别进行训练,所以实际上的损失函数如下:

这里应该是写错了,Tl(i,j)的值应该是1,表示需要被训练的,未被量化的权重。
随后作者使用了SGD来更新权重:
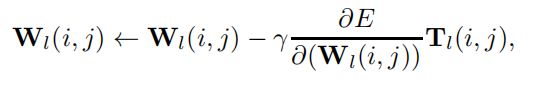
具体算法如下:

作者还介绍了他们权重划分的思想:他们认为,绝对值更大的权重是更重要的(但他没说是先量化重要的还是不重要的,我的理解是先重要的,因为此时浮点型权重是最多的,因此它可以尽可能地保持自己原有的精度)这个选择是有道理的,因为绝对值大的参数,往往对网络的影响更大,所以需要得到更好地量化以避免较大的精度损失。但这个选择或许并不正确,权重的出现频率应该也要考虑进去。考虑一个算法,能够综合地考虑权重绝对值的大小和出现的频率,应该是更好的划分方法。
作者接下来尝试了2、3、4比特的网络的结果以及各种权重的划分比例,发现inq都要比其它方法强(不强也不会写出来了)。
随后作者和各种压缩算法做了比较,结论就是完爆。
作者最后总结了他们工作的不足:只做了权重的量化,没有考虑激活层和梯度(去查了下,作者后来又用渐进式的方法发了两篇文章,但没有关于这方面的,也没有查到这方面的工作),还有想办法把inq部署到各种硬件平台上。
