前言
本文提出了一种叫做imprinting的方法,尝试将卷积网络分类器的最佳属性与embedding结合起来,处理小样本学习问题。作者认为,嵌入向量(embedding vector)可以与卷积网络分类器最后一个线性层的权值相当。imprinting方法就是,根据一个训练样本计算一个新类的embedding,然后将这些embedding进行合适的缩放,作为最后一层的权值,也就是作为该新类的权值,其它类的权值保持不变。这种方法也可以扩展到有多个训练样本的情况下,那么就是使用多个训练样本的embedding的平均值作为新类的权值。
现有的小样本学习的方法无法在一些资源有限的环境中使用,比如移动设备和机器人。比如,用SGD训练一个深度卷积网络分类器需要一个额外的微调过程,该过程不仅把先前的训练数据重新过了一遍,还要处理来自其它类的样本,整个过程就很复杂。虽然语义嵌入(semantic embedding)模型可以迅速根据新的样本来进行识别,并且不需要使用原先的训练数据重新训练,但语义嵌入训练起来真的是太难了hhh,不仅在hard-negative mining这一步计算量巨大,并且在测试时需要存储所有的嵌入向量(embedding vector)以进行最近邻操作或分类,总之就是训练成本很高。
本文提出了imprinting方法,也就是imprinted weights,可以在小样本的情况下通过一个单一样本进行即时的学习。而且,由于imprinting之后的模型的参数形式和之前的卷积网络是一样的,因此可以在有更多可用训练样本的时候再通过向反向传播进行微调。实验证明,imprinting方法与随机初始化相比,为网络提供了一个更好的初始化,并且在小样本问题上也能得到更好的分类结果。
度量学习和softmax分类之间的关系
最近的一些工作已经模糊了基于triplet的embedding training和softmax分类之间的区别,比如在Neighborhood Components Analysis中,使用类似softmax的损失来学习了一个距离度量:
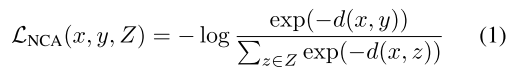
上式通过使用平方欧氏距离
,使得拥有相同标签的点
,
比标签不同的点
离得更近。
Movshovitz-Attias根据类标签将代理
分配给训练样本,重新定义了式(1)的损失:
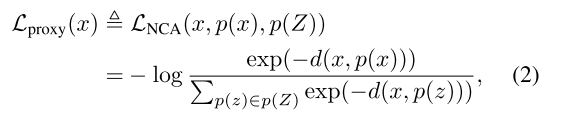
其中
是负代理的集合。上式允许为每个mini-batch采样anchor点
,而不再是triplet,从而使得模型能够更快速的收敛。
上面说的是度量学习中基于代理的embedding training,那么度量学习和softmax分类之间有什么关系呢?
考虑这样一种情况,每个类都有一个确切的代理,而且这个代理由这个数据点的标签决定。设 为类标签的集合, 是代理的集合,那么每个点 的代理就是 ,其中 是点 的类标签。作者认为代理 可以相当于softmax分类中的权值 。
为了说明这一点,假设点向量和代理向量被归一化为同样的长度,那么最小化点
和它的代理
之间的平方欧氏距离,就相当于最大化内积,或者等效于余弦相似度,如下式:
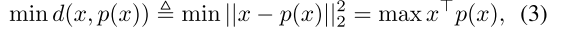
将式(2)中的平方欧氏距离替换为内积,损失函数变为:
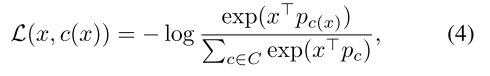
式(4)就可以相当于训练分类器时使用的softmax交叉熵损失,如下式:
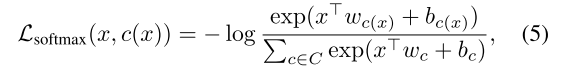
对所有的
,偏差项
模型结构
本文的模型包括两部分:
- embedding提取器 ,它由CNN进行参数化,将一个输入图像 映射到一个 维的embedding向量 ,并且在embedding提取器的最后要添加一个 归一化层,使得输出的embedding都是单位长度,即 ;
- 一个softmax分类器
,将embadding映射到没有被归一化的logit分数,然后通过softmax激活层为所有类别生成一个概率分布:
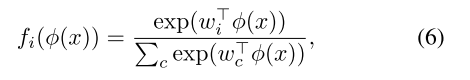
其中 是归一化之后的权值矩阵的第 列,没有偏差项。
本文将权值矩阵的每一列
视为相应类别的一个模板,在前向传播过程中,模型的最后一层计算输入图像的embedding
和所有模板
之间的内积,由于embedding和
都已经被归一化为单位长度,因此预测结果就相当于在embedding空间中使用平方欧氏距离找到离得最近的那个
:
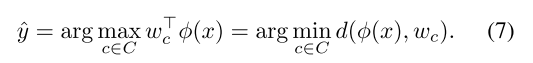
与其它非参数化最近邻模型相比,本文的模型中每个类只有一个模板,而不是存储了大量的参考数据点。
1. 归一化
在本文的模型中,将embedding和最后一层的权值矩阵中的每一列,即 ,归一化为单位长度是非常重要的。在现有的深度神经网络中,没有考虑神经单元激活值和权值之间的比例的不同,而是直接强制调整到零均值和单位方差。在本文的模型中,由于对embedding和 进行了归一化,它们比例的不同并不会影响到预测结果,因为归一化之后的向量的角度是相同的。
2. 缩放因子
当通过softmax激活层时,余弦相似度 可以避免正确类的归一化概率太过接近于1。比如,对于输入 来说,正确的类别内积输出为1,错误的类别内积输出为-1,假设总共有100个类,即 ,那么归一化概率就为: ,而这样的话,就不能为gt标签生成一个接近one-hot编码的分布,因此交叉熵损失的下限就变得很低。尤其当类别数量增加的时候,这个问题会更严重。
为了缓解这个问题,本文在模型中采用了缩放因子,通过添加一个在类间共享的缩放因子
来对内积进行缩放,式(6)可变为:
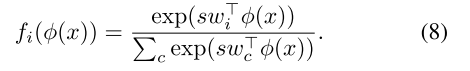
总结下来,本文的模型虽然与标准的CNN分类器很相似,但还是有以下两个不同:
- 归一化的embedding和 引入了一种系统关系,使得它们之间是可以互换的;
- 在最后一层添加的缩放因子,对内积进行缩放,使得可以像标准CNN分类器那样用交叉熵损失来训练模型。
imprinting方法介绍
所谓imprinting就是,利用归一化的embedding和权值向量
之间的对称性,将一个新样本的embedding作为网络最后一层的权值。考虑一个来自新类的单一样本
,imprinting方法就是先计算embedding
,然后用这个embedding为权值矩阵添加的新的一列,作为新类的权值向量
,下图说明了这个过程:
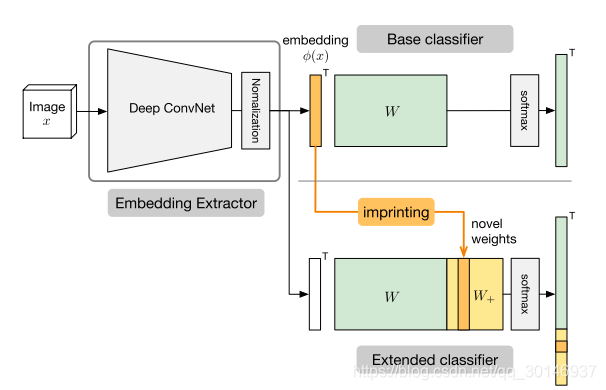
直观上来说,可以将imprinting看作是将新样本的semantic embedding作为新类的模板。下图说明了在添加权值矩阵中的新列
之后,决策边界发生了怎样的改变。这里做出的一个假设是,在测试时来自新类的样本,与训练时使用的新类的样本是非常接近的,即使只有少量样本很类似,但也比embedding空间中的其它类要接近。
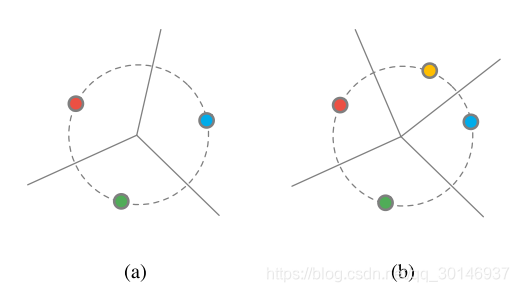
图(a)是在imprinting之前,决策边界由权值决定;图(b)是在imprinting之后,黄点是一个新类的样本,可以看到它定义了一个新的区域。
如果新样本的数量大于1时要怎么办? 如果新类中有多个可用的样本,即 ,那么就计算归一化的embedding的平均作为新的权值 ,然后再将这个权值归一化为单位长度 。实际上,也可以对原始样本进行随机增强后提取embedding,然后对这些embedding进行平均操作。
关于微调。由于本文的模型与原始的CNN分类器具有相同的可微形式,因此可以在imprinting之后再进行微调。对embedding的平均操作假设了每个新类的样本在embedding空间中都呈单峰分布,但并不是每个新类都是这样的,因为学到的embedding空间可能是有偏差的。通过微调(使用反向传播来进一步优化网络的权值)可以使得所有的新类在embedding空间中都为单峰分布。
