ICLR-2018
摘要
深度学习网络在计算机视觉工作(如图像分类和对象检测)方面取得了最先进的准确性。然而,高性能系统通常涉及具有许多参数的大型模型。一旦训练完成,这些表现最佳的模型的一个挑战性方面就是在资源受限的推理系统上进行部署 - 模型(通常是深度网络或宽网络或两者)都是计算和内存密集型的。使用低精度数值和基于知识蒸馏的模型压缩是降低这些部署模型的计算要求和内存占用的常用技术。在本文中,我们研究了这两种技术的结合,并表明使用知识蒸馏技术可以显着提高低精度网络的性能。我们的方法Apprentice使用三元精度和4位精度,在ImageNet数据集上使用ResNet架构的变体,实现了最先进的精度。我们提出了三种方案,使用这些方案可以将知识蒸馏技术应用于列车和部署管道的各个阶段。
1 INTRODUCTION
背景:今天用于计算机视觉应用的高性能深度神经网络(DNN)包括多层并涉及众多参数。这些网络具有O(Giga-FLOPS)计算要求,并生成存储中的O(兆字节)模型(Canziani等,2016)。此外,训练和推理期间的记忆和计算要求是完全不同的(Mishra等,2017)。对具有大批量大小的大数据集执行训练,其中激活的内存占用占据模型内存占用。另一方面,推理期间的批量大小通常较小,并且模型的内存占用量主导运行时内存需求。
由于计算,存储器和存储要求的复杂性,网络的训练阶段在分布式计算环境中的CPU和/或GPU集群上执行。一旦经过训练,一个具有挑战性的方面是在资源受限的推理系统(如便携式设备或传感器网络)上以及需要实时预测的应用中部署受过训练的模型。对边缘设备进行推理会对内存,计算和功耗造成严重限制。另外,基于集合的方法(可用于获得改进的准确度预测)在资源受限系统中变得过高。
使用低精度数值进行量化(Vanhoucke等,2011; Zhou等,2016; Lin等,2015; Miyashita等,2016; Gupta等,2015; Zhu等,2016; Rastegari等,2016; Courbariaux等,2015; Umuroglu等,2016; Mishra等,2017)和模型压缩(Bucilua等,2006; Hinton等,2015; Romero等, 2014)已成为资源受限部署方案的流行解决方案。通过量化,在设备上生成并部署低精度版本的网络模型。在较低精度模式下操作可降低计算以及数据移动和存储要求。然而,大多数现有的低精度DNN工作都牺牲了基准全精度网络的精度。通过模型压缩,可以训练较小的低内存占用网络,以模拟原始复杂网络的行为。在此培训期间,称为知识蒸馏的过程用于将知识从复杂网络“转移”到较小的网络。 Hinton等人的工作。 (2015)表明知识蒸馏方案可以产生与原始复杂模型相当或略微更好的精度的网络。然而,据我们所知,所有使用模型压缩技术的先前工作都以全精度对准压缩。
我们的方法:在本文中,我们研究了网络量化与模型压缩的结合,并表明使用知识蒸馏技术可以显着提高低精度网络的准确性。以前关于模型压缩的研究使用大型网络作为教师网络,使用小型网络作为学生网络。小型学生网络使用蒸馏过程从教师网络中学习。学生网络的网络架构通常不同于教师网络的网络架构 - 例如, Hinton等人。 (2015)调查与教师网络相比隐藏层中神经元数量较少的学生网络。在我们的工作中,学生网络具有与教师网络类似的拓扑结构,除了学生网络具有低精度神经元,而教师网络具有以全精度操作的神经元。
我们称之为Apprentice,并研究了三种使用知识蒸馏技术生成低精度网络的方案。这三种方案中的每一种都可以生成最先进的三元精度和4位精度模型。
在第一种方案中,使用知识蒸馏方案从头开始联合训练低精度网络和全精度网络。在本文后面,我们描述了这种方法背后的基本原理。使用该方案,可以获得ImageNet数据集上ResNet-18,ResNet-34和ResNet-50的三元和4位精度的很好的精度。事实上,使用这种方案,全精度模型的精度也略有提高。然后,该方案作为我们调查的其他两个方案的新基线。
在第二种方案中,我们从一个全精度训练的网络开始,不断地从这个训练有素的网络传输知识,从头开始训练低精度网络。我们发现,当训练有素的复杂网络引导其训练时,低精度网络会收敛得更快(尽管与第一种方案的准确度相似)。
在第三种方案中,我们从训练有素的全精度大型网络和已经使用全精度权重初始化的学徒网络开始。学徒网络的精确度降低,并使用知识蒸馏技术进行微调。我们发现低精度网络的精度略有提高,超过了第一种方案所获得的精度。然后,该方案以三元4位精度为ResNet模型设置了新的最先进的精度。
总的来说,本文的贡献是使用知识蒸馏技术获得低精度DNN的技术。我们的每个方案都生成一个低精度模型,该模型超过了迄今为止发布的等效低精度模型的精度。我们的一个方案也有助于低精度模型更快地收敛。我们设想这些精确的低精度模型,以简化资源受限系统上的推理部署过程,甚至是基于云的部署系统。
2 低精度模型参数实验的动机
降低模型参数的精度:资源受限的推理系统对内存,计算和功率预算施加了显着的限制。关于存储,模型(或权重)参数和激活映射在DNN的推断阶段期间占用存储器。在此阶段期间,存储器被分配用于DNN中单个层所需的输入(IFM)和输出特征映射(OFM),并且这些动态存储器分配被重用于其他层。因此,推理期间的总内存分配是IFM的最大值和所有层所需的OFM内存的最大值加上所有权重张量的总和(Mishra等,2017)。当使用较小的批量大小执行DNN的推断阶段时,权重的内存占用量超过了激活映射的占用空间。对于4种不同的网络,这一方面如图1所示(AlexNet(Krizhevsky等,2012),Inception-Resnet-v2(Szegedy等,2016),ResNet-50和ResNet-101(He等。 ,2015))运行224x224图像补丁。因此,降低权重张量的精度有助于降低部署期间的存储器要求。降低内存占用量的另一个方面是工作负载的工作集大小开始适应芯片,并且通过减少对DRAM(片外)内存的访问,计算内核开始看到更好的性能和节能(DRAM访问费用昂贵)在延迟和能量方面)。
低精度计算的好处:低精度计算简化了硬件实现。 例如,当使用全精度权重和激活时,执行卷积运算(两个操作数的乘法)的计算单元包含一个浮点乘法器。 当使用二进制精度进行权重和激活时,浮点乘法器可以用更简单的电路(xnor和popcount逻辑元件)代替(Courbariaux&Bengio,2016; Rastegari等,2016; Courbariaux等。 ,2015)。 同样,当使用三重精度的称重和全精度的激活时,乘法器单元可以用符号比较器单元代替。 更简单的硬件还有助于降低推理延迟和能量预算。 因此,以较低精度模式运行会降低计算以及数据移动和存储要求。
然而,低精度模型的缺点是精度降低。我们稍后将在文章中讨论使用文献中提出的方法获得的网络精度。这些准确性是我们在工作中比较的出发点和基线。
3 相关工作
低精度网络:低精度DNN是一个活跃的研究领域。大多数低精度网络承认当今DNN架构的过度参数化方面和/或降低训练后神经元精度的方面通常不会影响最终性能。已经非常好地研究了降低有效推理管道的重量精度。像Binary connect(BC)(Courbariaux et al。,2015),三元权重网络(TWN)(Li&Liu,2016),细粒度三元量化(Mellempudi等,2017)和INQ(Zhou等人) 。,2017)目标精度降低网络权重。当权重量化显着低于8位精度时,精度几乎总是受到影响。对于ImageNet上的AlexNet,TWN失去了5%的Top-1准确度。像INQ这样的方案,在Sung等人工作。 (2015年)和Mellempudi等人。 (2017)进行微调以量化网络权重。
在XNOR-NET(Rastegari等人,2016),二元神经网络(Courbariaux&Bengio,2016),DoReFa(Zhou等人,2016)和训练三元量化(TTQ)(Zhu等人,2016)目标中工作培训管道。虽然TTQ的目标是权重量化,但大多数针对激活量化的工作表明,量化激活总是会影响精确度。当将权重和激活量化为1位(对于ImageNet上的AlexNet)时,XNOR-NET方法将Top-1精度降低12%,DoReFa降低8%。 Gupta等人的工作。 (2015)倡导用于培训的低精度定点数。它们显示16位足以用于CIFAR10数据集的训练。 Seide等人的工作。 (2014)量化分布式计算系统中的梯度。
知识蒸馏方法:基于蒸馏的方法的一般技术涉及使用师生策略,其中针对给定任务训练的大型深度网络教导较浅的学生网络执行相同的任务。知识蒸馏或转移技术背后的核心概念已经存在了一段时间。 Bucilua等人。 (2006)表明,可以将集合中的信息压缩到单个网络中。 Ba&Caurana(2013)通过模仿深度神经网络,将这种方法扩展到研究浅而宽的全连通拓扑。为了便于学习,作者介绍了学习logits而不是概率分布的概念。
Hinton等人。 (2015)提出了一个通过引入温度概念来传递知识的框架。关键思想是在执行Softmax功能之前将logits除以温度因子。通过使用更高的温度因子,可以提高不正确类别的激活。这样便于在反向传播操作期间向模型参数传递更多信息。 FitNets(Romero et al。,2014)通过使用中间隐藏层输出作为目标值来扩展这项工作,以培养更深,更薄的学生模型。 Net2Net(Chen et al。,2015a)也使用具有功能保留转换方法的师生网络系统来初始化学生网络的参数。 Net2Net方法的目标是加速对更大的学生网络的培训。 Zagoruyko和Komodakis(2016)将注意力作为将知识从一个网络转移到另一个网络的机制。在类似的主题中,Yim等人。 (2017)提出了一个信息度量标准,教师DNN可以使用该度量标准将提取的知识传递给其他学生DNN。在N2N学习工作中,Ashok等人。 (2017)提出了一种基于强化学习的方法,用于将教师网络压缩成同等能力的学生网络。它们在CIFAR数据集上为ResNet-34实现了10倍的压缩系数。
稀疏性和散列:很少有其他流行的模型压缩技术是修剪(LeCun等,1990; Han等,2015a; Wen等,2016; Han等,2015b),散列(Weinberger等, 2009)和权重分享(Chen等,2015b; Denil等,2013)。修剪导致完全从最终训练模型中移除神经元,使得模型成为稀疏结构。使用散列和权重共享方案,散列函数用于将几个权重参数混合到少量散列桶中,从而有效地降低了参数内存占用。为了在运行时期间实现稀疏性和散列方案的益处,需要有效的硬件支持(例如,支持不规则的存储器访问(Han等人,2016; Venkatesh等人,2016; Parashar等人,2017))。
4 知识蒸馏
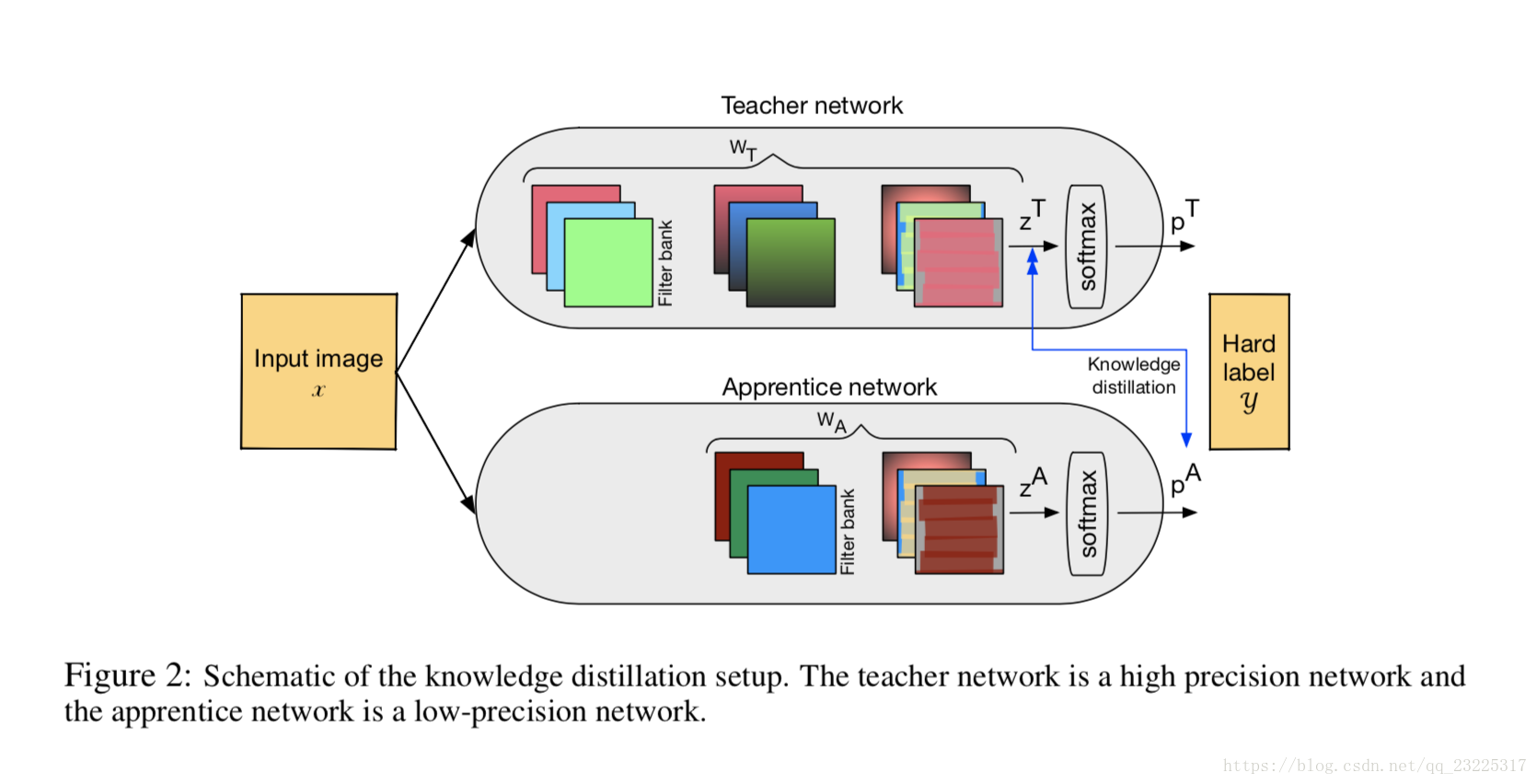
5 本文的方法 APPRENTICE NETWORK
我们结合这两种技术来提高网络准确性以及DNN的运行时效率。 使用上一节中描述的师生设置,我们研究了三种方案,使用这三种方案可以获得学生网络的低精度模型。 第一个方案(方案-A)联合培养网络 - 全精度教师和低精度学生网络。 第二种方案(方案-B)仅训练低精度学生网络,但在整个培训过程中从训练有素的全精度教师网络中提取知识。 第三种方案(方案-C)从训练有素的全精度教师和全精度学生网络开始,但在降低其精确度后对学生网络进行微调。 在我们深入了解每个方案的细节之前,我们将讨论使用文献中描述的低精度方案获得的精度数。 这些准确度数字作为比较分析的基准。
5.1 TOP-1错误以及低精度网络的先前提案
我们专注于用于推理部署的子8位精度,特别是三进制和4位精度。我们发现TTQ(Zhu et al。,2016)方案通过三元精度和激活的全精度(32位浮点)实现了最先进的精度。在Imagenet-1K(Rus- sakovsky等,2015)上,使用ResNet-18模型,TTQ实现了33.4%的Top-1错误率。我们为在Imagenet-1K上训练的ResNet-34和ResNet-50模型实施了TTQ方案,分别实现了28.3%和25.6%的Top-1错误率。该方案是2位权重和全精度激活的基线。对于2位权重和8位激活,我们找到了Mellempudi等人的工作。 (2017)达到文献报道的最佳准确度。对于ResNet-50,Mellempudi等人。 (2017)获得29.24%Top-1错误。我们认为这项工作是2位权重和8位激活模型的基线。
对于4位精度,我们发现WRPN方案(Mishra等,2017)报告最高精度。我们为4位权重和8位激活实现了这种方案。对于在Imagenet-1K上训练的ResNet-34和ResNet-50型号,我们分别实现了29.7%和28.4%的前1错误率。
5.2方案-A:教师 - 学生网络的联合培训
在我们调查的第一个方案中,全精度的教师网络与低精度的学生网络共同训练。图2显示了整体培训框架。我们将ResNet拓扑用于教师和学生网络。当为学生网络使用一定深度时,我们选择教师网络以具有相同或更大的深度。
在Bucilua等人。 (2006)和Hinton等。 (2015年),只有学生网络在从教师网络中提取知识的同时进行培训。在我们的案例中,我们联合训练的理由是,教师网络不仅要继续指导学生网络,而且还要经过最终训练的记录,还要指导教师在生成最终更高精度的记录时采取的路径。
我们在TensorFlow中实施ResNet的预激活版本(He et al。,2016)(Abadi等,2015)。培训过程严格遵循ResNet的Torch实现中提到的配方 - 我们使用256的批量大小,并且没有超出配方中提到的超参数。对于教师网络,我们尝试使用ResNet-34,ResNet-50和ResNet-101作为选项。对于学生网络,我们尝试使用ResNet-18,ResNet-34和ResNet-50的低精度变体。
对于低精度数值,当使用三元精度时,我们使用三元权重网络方案(Li&Liu,2016),其中权重张量被量化为{-1,0,1},其中每层缩放系数基于权重张量中的正项的平均值。我们使用WRPN方案(Mishra等,2017)将权重和激活量化为4位或8位。我们不会降低学徒网络中第一层和最后一层的精度。这是基于几乎所有先前工作中的观察结果,即降低这些层的精度会显着降低精度。在训练和微调期间,梯度仍然保持完全精确。