mysql索引
索引类型:
mysql中的索引分为普通索引,唯一索引,全文索引,组合索引
普通索引:
仅加速查询 最基本的索引,没有任何限制,是我们大多数情况下使用到的索引。
CREATE INDEX index_name on user_info(name) ;
唯一索引:
与普通索引类型,不同的是:加速查询 + 列值唯一(可以有null)
CREATE UNIQUE INDEX mail on user_info(name) ;
全文索引:
全文索引(FULLTEXT)仅可以适用于MyISAM引擎的数据表;作用于CHAR、VARCHAR、TEXT数据类型的列。
组合索引:
将几个列作为一条索引进行检索,使用最左匹配原则。
b+tree
而在innodb中和myisa中都是使用b+tree来进行索引和数据的存储于关联。只是在细微的地方做了一些变种。
b+tree表示如下结构:
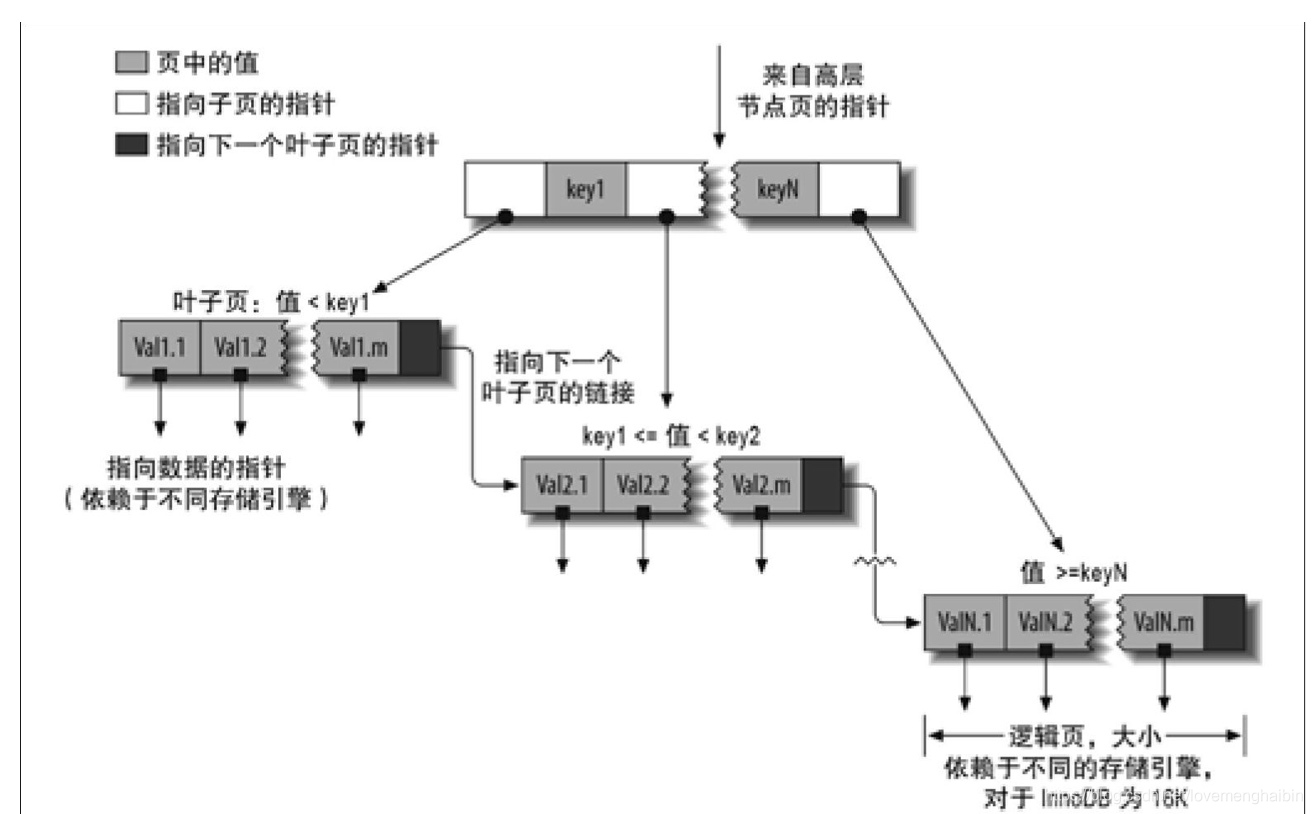
比如我们要查询value1.m,则先用二分法查询到key1下边的数据范围,然后继续在key1里从左向右找,就能找到val1.m了。除了叶子节点,其他的任意节点都有一个指向子节点从指针和指向兄弟节点的指针,这样我们就可以通过这两个指针快速的完成叶子节点和兄弟节点直接的查询,例如找val1.m,则是key1->value1.1->val1.2->…->val1.m,再比如范围查询,我们要查询val1.1到val2.1的值,我们只需要先找到val1.1和val2.1,然后理论链表把中间的取出来就行了。
innodb的b+tree
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AuXJNaKP-1579153211160)(media/15790565483539/15791391655418.jpg)]
如图,innodb的主键索引,除了叶子几点,其他的节点都是存储的索引的值,只有叶子节点保存了索引的值和完整的data,所以如果我们根据主键,不管是范围查询还是分组查询(group)或者order by的时候,都是非常快的,
当然除了主键索引,我们还有普通的索引
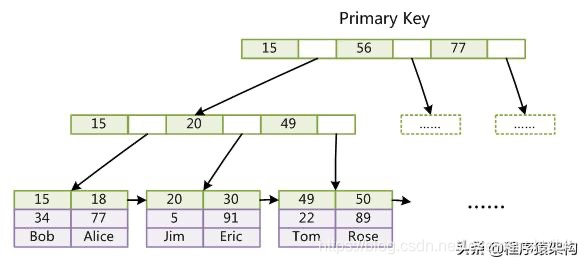
普通的索引非叶子节点都是一样的,只是叶子节点的不仅有索引值,还有主键的索引,但是没有data数据,所以根据非主键索引查询数据的时候,是需要查询两遍的,例如我们要查名字叫bob的人,实际上是先查询到bob,然后找到主键索引15的主键,之后再利用主键索引再查一遍,所以查询的时间实际是主键查询的两倍。
组合索引
组合索引就是几个数据列组合起来成一个索引,索引结构如下:
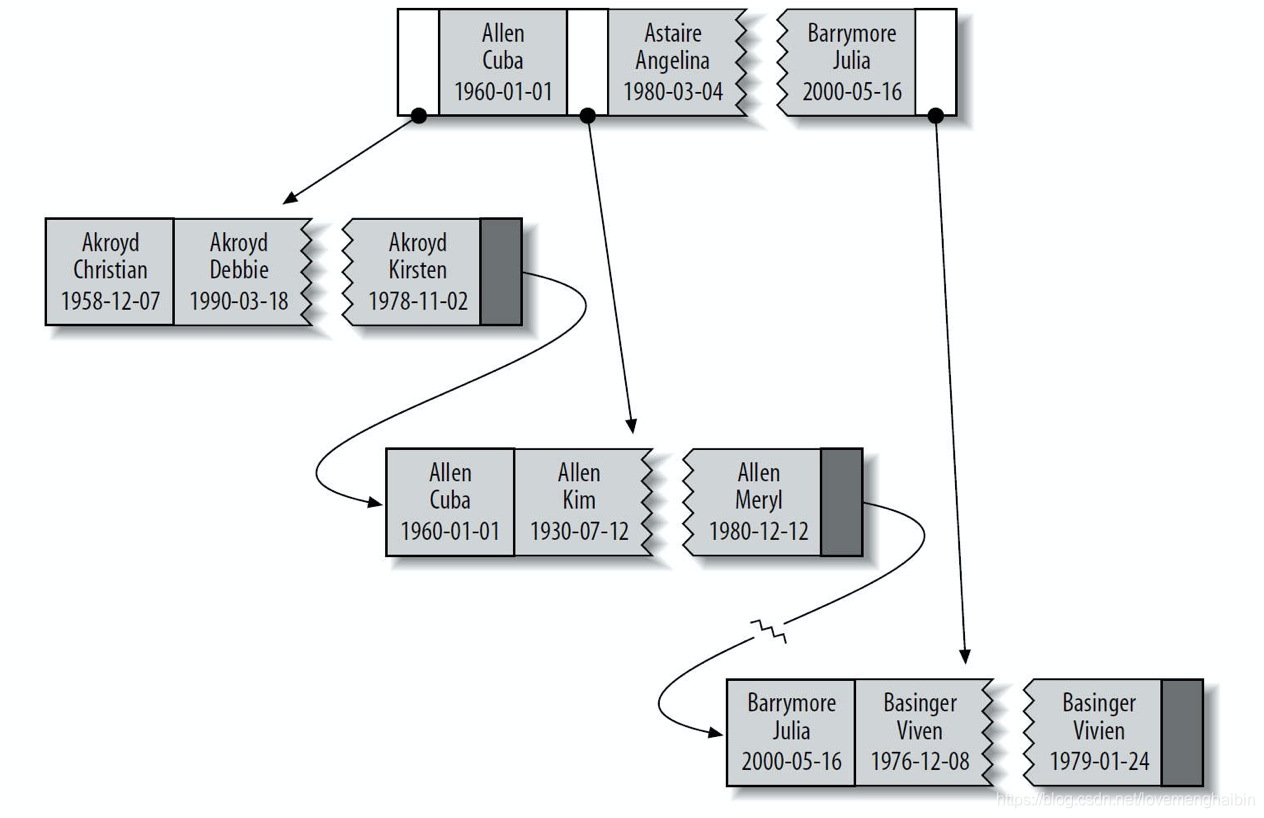
例如上图表示,包含了first_name, last_name, birthday三个字段,那么索引也是按照这三个顺序创建的索引,所以才有和组合索引里要求的顺序问题:
全值匹配
全值匹配就是我们要查询的每一个字段都要精确匹配,例如我么要查询名称为Allen cuba, 1960-01-01出生的人,我就查询first_name为Allen, last_name=cuba,birthday=1960-01-01,便可以精确匹配,
匹配最左前缀
如果我们只是查询部分信息,例如first_name, last_name, birthday这三个字段,我们只需要其中的一个或者两个,则first_name是必须要有的,如果剩下的一个条件是last_name,拿索引同样有效,如果剩下的是生日,则生日的字段无法利用索引
匹配范围值
例如我们要查询first_name在allen到Baarymore名称的用户。
精确匹配第一列,范围匹配第二列
前面提到的索引也可用于查找所有姓为Allen,并且名字是字母K开头(比如Kim、Karl等)的人。即第一列first_name全匹配,第二列last_name范围匹配。
Myisam
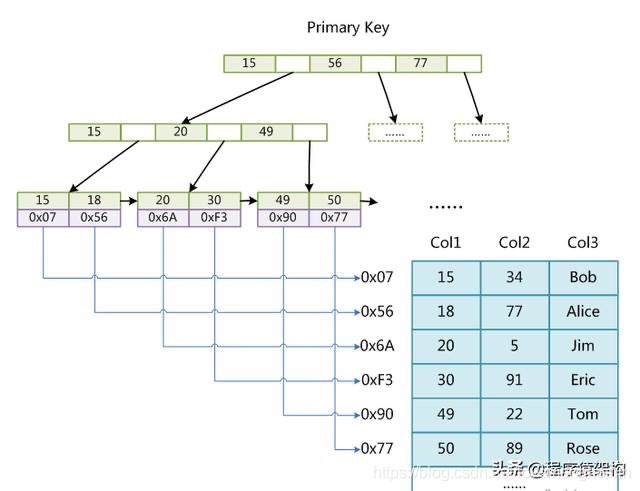
如图,myisam的主键索引和普通索引也都是b+tree,只不过他的叶子节点都保存的是data的地址。MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
除了innodb有聚集索引,其他的索引都没有聚集索引。而我们常说的聚集索引就是innodb表中的主键。
- 聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个
- 聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续
- 聚集索引:物理存储按照索引排序;聚集索引是一种索引组织形式,索引的键值逻辑顺序决定了表数据行的物理存储顺序
- 非聚集索引:物理存储不按照索引排序;非聚集索引则就是普通索引了,仅仅只是对数据列创建相应的索引,不影响整个表的物理存储顺序.
- 索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
覆盖索引
所谓的覆盖索引,其实说白了就是select后边的字段如果是索引字段,就不用查询第二遍了。
创建一张表:
CREATE TABLE `movie_tpp_cinema` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键id',
`cinema_id` bigint(20) NOT NULL COMMENT '淘票票的影院id',
`cinema_name` varchar(200) NOT NULL COMMENT '影院名称',
`city_id` int(11) NOT NULL COMMENT '城市id',
`city_name` varchar(50) DEFAULT NULL COMMENT '城市名称',
`latitude` varchar(20) NOT NULL COMMENT '经度',
`longitude` varchar(20) NOT NULL COMMENT '维度',
`phone` varchar(200) DEFAULT NULL COMMENT '联系电话',
`region_name` varchar(50) DEFAULT NULL COMMENT '区域名称',
`schedule_close_time` int(11) DEFAULT NULL COMMENT '影院场次提前关闭时间,单位分钟',
`standard_id` varchar(30) DEFAULT NULL COMMENT '广电总局发放给影院的8位标准影院编码',
`support_third_party_refund` tinyint(4) DEFAULT NULL COMMENT '是否支持第三方退款',
`address` varchar(255) DEFAULT NULL COMMENT '地址',
`status` tinyint(4) DEFAULT '0' COMMENT '0:有效,1:失效',
`created_date` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `movie_tpp_cinema_cinema_id_index` (`cinema_id`),
KEY `movie_tpp_cinema_city_id_index` (`city_id`)
) ENGINE=InnoDB AUTO_INCREMENT=328376 DEFAULT CHARSET=utf8 COMMENT='影院信息'
电影院表现在有30万的数据。现在我查询北京有多少家影院信息,例如根据城市查询影院的信息
select cinema_id from movie_tpp_cinema where city_id =110100 and status = 0;
explain我们可以看到,其实是用了索引的,但是在extra中是using where,
接下来我们执行
create index movie_tpp_cinema_cinema_id_city_id_index
on movie_tpp_cinema (cinema_id, city_id);
然后再查询,可以看到extra里有using index.
