★
说到 B+Tree,需要从索引聊起,索引就如同字典,我们可以使用目录快速定位到所要查找的内容,那么索引跟目录的作用类似,在数据库表记录中,利用索引,可以快速过滤查找到数据记录。
”
1. 索引结构分类
索引有很多分类,例如 B-tree 索引,哈希索引,全文索引等等,索引的实现是在存储引擎层,并不是在后端服务器层,所以不同的存储引擎支持的索引结构也不一定一样 1.1B-tree 索引 B-tree 索引普遍存在于存储引擎中,他使用 B-tree 数据结构来存储数据,如果对树形数据结构比较了解的话,就知道 B-tree 索引所带来的好处了,他的每个叶子节点都会包含下一个节点的指针,非常方便查询数据 B-tree 适用于全键值,键值范围,或者前缀查找,查询/插入/修改/删除的平均时间复杂度都是 O(lg(n)) 1.2 哈希索引 哈希索引基于哈希表实现,对于每一行数据,存储引擎会对所有的索引列计算一个哈希码,然后存储引擎会基于这个哈希码来查找数据,查询/插入/修改/删除的平均时间复杂度都是 O(1),适用于单行查询。 1.3 全文索引 全文索引在几种索引结构类型中比较特殊,他查找的是文本中关键词
2. 索引的正确使用
索引是建立在系统文件上的,会占用一定的内存空间,另外数据在更新的时候也会去维护索引,消耗内存,所以索引一定要正确的使用,索引并不是越多越好,要根据具体的查询业务来规划索引的建立。
2.1 建议不要使用索引的几种情况:
-
- 区分度不是很大的字段,例如 性别 sex
-
- 频繁更新的字段
-
- 字符串类型的字段 或者 文本类型的字段
-
- 不在 where 列中出现的索引
2.2 索引失效的几种情况:
-
- 查询列中有函数计算
-
- 查询列中有模糊查询,"%cloum",可以使用"cloum%" 代替,如果要使用"%column%",那么 select 列中是索引列
-
- 如果查询条件中有 or, 索引会失效,除非所有条件都加上索引
-
- 使用不等于(!= 或者 <>)
-
- is null 或者 is not null
-
- 字符串不加引号,会导致索引失效
-
- 最左原则,联合索引中会遵循最左原则,即如果要使用联合索引,那么前面的索引列一定要包含,举个例子, 有个联合索引(a,b,c) 那么查询条件中只能是 a=1 或者 a=1 and b=1 或者 a=1 and b=1 and c=1,不然索引就会失效
3.B+树详解
在讲 B+树之前必须先了解二叉查找树、平衡二叉树(AVLTree)和平衡多路查找树(B-Tree),B+树即由这些树逐步优化而来。
3.1 二叉查找树
二叉树具有以下性质:
- 左子树的键值小于根的键值
- 右子树的键值大于根的键值
如下图所示就是一棵二叉查找树,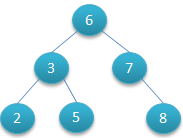
对该二叉树的节点进行查找发现深度为 1 的节点的查找次数为 1,深度为 2 的查找次数为 2,深度为 n 的节点的查找次数为 n,因此其平均查找次数为 (1+2+2+3+3+3) / 6 = 2.3 次
3.2 平衡二叉树(AVL Tree)
平衡二叉树(AVL 树)在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为 1。下面的两张图片,左边是 AVL 树,它的任何节点的两个子树的高度差<=1;右边的不是 AVL 树,其根节点的左子树高度为 3,而右子树高度为 1;
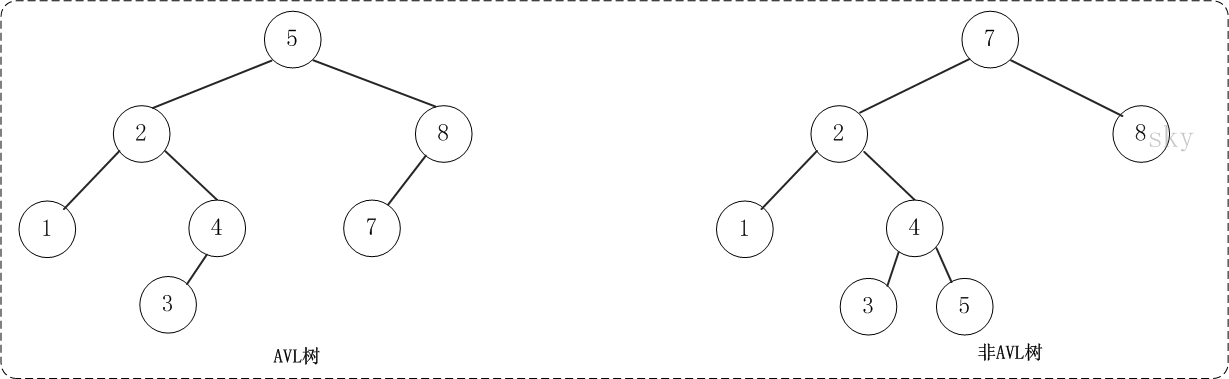 平衡二叉树
平衡二叉树
平衡二叉树中序遍历就是排序,看下图,中序遍历逻辑为:先访问左节点,再访问根节点,最后访问右节点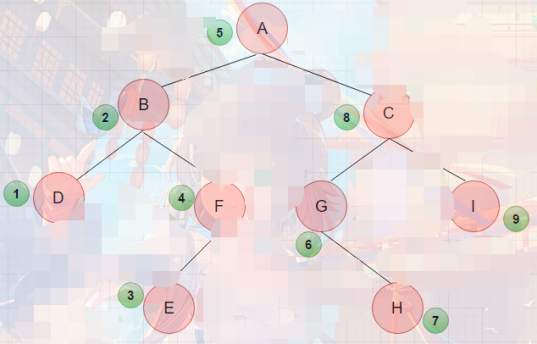
3.3 平衡多路查找树(B 树)
B-Tree 是为磁盘等外存储设备设计的一种平衡查找树。
一棵 m 阶的 B-Tree 有如下特性:
-
- 每个节点最多有 m 个孩子。
-
- 除了根节点和叶子节点外,其它每个节点至少有 Ceil(m/2)个孩子。
-
- 若根节点不是叶子节点,则至少有 2 个孩子
-
- 所有叶子节点都在同一层,且不包含其它关键字信息
-
- 每个非终端节点包含 n 个关键字信息(P0,P1,…Pn, k1,…kn)
-
- 关键字的个数 n 满足:ceil(m/2)-1 <= n <= m-1
-
- ki(i=1,…n)为关键字,且关键字升序排序。
-
- Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于 ki,但都大于 k(i-1)
B-Tree 中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个 3 阶的 B-Tree:
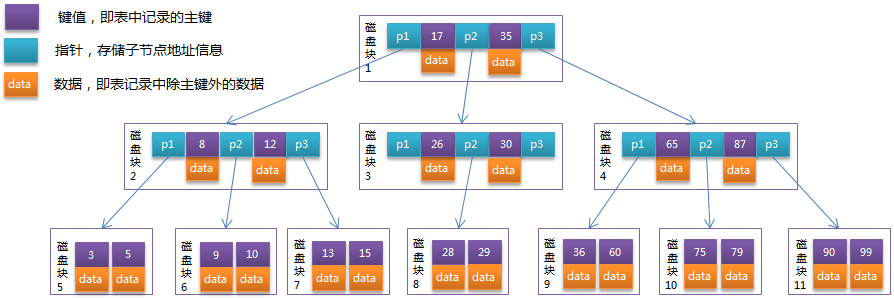 3阶的B-Tree
3阶的B-Tree
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。 两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为 17 和 35,P1 指针指向的子树的数据范围为小于 17,P2 指针指向的子树的数据范围为 17~35,P3 指针指向的子树的数据范围为大于 35。
B 树被作为实现索引的数据结构被创造出来,是因为它能够完美的利用“局部性原理”。
什么是局部性原理?
- (1)内存读写块,磁盘读写慢,而且慢很多;
- (2)磁盘预读:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,如果未来要读取的数据就在这一页中,可以避免未来的磁盘 IO,提高效率;
- (3)局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘 IO;
3.4B+Tree
B+Tree 是在 B-Tree 基础上的一种优化,使其更适合实现外存储索引结构,InnoDB 存储引擎就是用 B+Tree 实现其索引结构。
B+树,仍是 m 叉搜索树,在 B 树的基础上,做了一些改进:
- (1)非叶子节点不再存储数据,数据只存储在同一层的叶子节点上;
★
B+树中根到每一个节点的路径长度一样,而 B 树不是这样。
”
- (2)叶子之间,增加了链表,获取所有节点,不再需要中序遍历;
这些改进让 B+树比 B 树有更优的特性:
-
范围查找,定位 min 与 max 之后,中间叶子节点,就是结果集,不用中序回溯;
★
范围查询在 SQL 中用得很多,这是 B+树比 B 树最大的优势。
”
-
叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的 PK,用于查询加速,适合内存存储;
-
非叶子节点,不存储实际记录,而只存储记录的 KEY 的话,那么在相同内存的情况下,B+树能够存储更多索引;
将上一节中的 B-Tree 优化,由于 B+Tree 的非叶子节点只存储键值信息,假设每个磁盘块能存储 4 个键值及指针信息,则变成 B+Tree 后其结构如下图所示: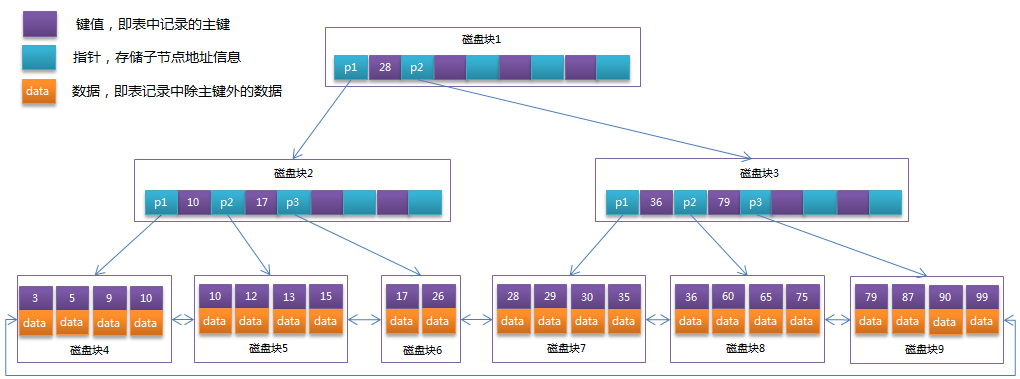
通常在 B+Tree 上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。 因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。 可能上面例子中只有 22 条数据记录,看不出 B+Tree 的优点,
量化说下,为什么 m 叉的 B+树比二叉搜索树的高度大大大大降低?
InnoDB 存储引擎中页的大小为 16KB,一般表的主键类型为 INT(占用 4 个字节)或 BIGINT(占用 8 个字节),指针类型也一般为 4 或 8 个字节,也就是说一个页(B+Tree 中的一个节点)中大概存储 16KB/(8B+8B)=1K 个键值(因为是估值,为方便计算,这里的 K 取值为 10^3。也就是说一个深度为 3 的 B+Tree 索引可以维护 10^3 _ 10^3 _ 10^3 = 10 亿条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree 的高度一般都在 2~4 层。MySQL 的 InnoDB 存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要 1~3 次磁盘 I/O 操作。
4.总结
- 数据库索引用于加速查询
- 虽然哈希索引是 O(1),树索引是 O(log(n)),但 SQL 有很多“有序”需求,故数据库使用树型索引
- InnoDB 不支持哈希索引
- 数据预读的思路是:磁盘读写并不是按需读取,而是按页预读,一次会读一页的数据,每次加载更多的数据,以便未来减少磁盘 IO
- 局部性原理:软件设计要尽量遵循“数据读取集中”与“使用到一个数据,大概率会使用其附近的数据”,这样磁盘预读能充分提高磁盘 IO
- 数据库的索引最常用 B+树: - (1)很适合磁盘存储,能够充分利用局部性原理,磁盘预读; - (2)很低的树高度,能够存储大量数据; - (3)索引本身占用的内存很小; - (4)能够很好的支持单点查询,范围查询,有序性查询;