BTree索引
BTree是平衡搜索多叉树,设树的度为d(d>1),高度为h,那么BTree要满足以一下条件:
- 每个叶子结点的高度一样,等于h;
- 每个非叶子结点由n-1个key和n个指针point组成,其中d<=n<=2d,key和point相互间隔,结点两端一定是key;
- 叶子结点指针都为null;
- 非叶子结点的key都是[key,data]二元组,其中key表示作为索引的键,data为键值所在行的数据;
BTree的结构如下:

在BTree的机构下,就可以使用二分查找的查找方式,查找复杂度为h*log(n),一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构。
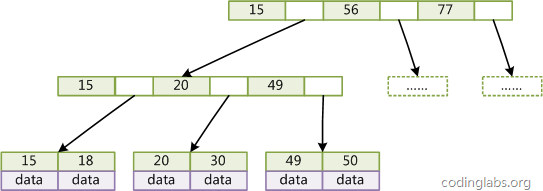
B+Tree索引
B+Tree是BTree的一个变种,设d为树的度数,h为树的高度,B+Tree和BTree的不同主要在于:
- B+Tree中的非叶子结点不存储数据,只存储键值;
- B+Tree的叶子结点没有指针,所有键值都会出现在叶子结点上,且key存储的键值对应的数据的物理地址;
B+Tree的结构如下:
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的一个扇区是整数倍的page(页),页是存储中的一个单位,通常默认为4K,因此索引结构的节点被设计为一个页的大小,然后利用外存的“预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,已知内存的读取速度是外存读取I/O速度的几百倍,那么提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
带顺序索引的B+TREE
很多存储引擎在B+Tree的基础上进行了优化,添加了指向相邻叶节点的指针,形成了带有顺序访问指针的B+Tree,这样做是为了提高区间查找的效率,只要找到第一个值那么就可以顺序的查找后面的值。
B+Tree的结构如下:
