InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
叶子节点到底是存的数据还是 指向真实数据的指针??如果是数据 那数据里面保存了一份,主键索引有保存了一份??如果都加载到内存那不是很占内存空间??
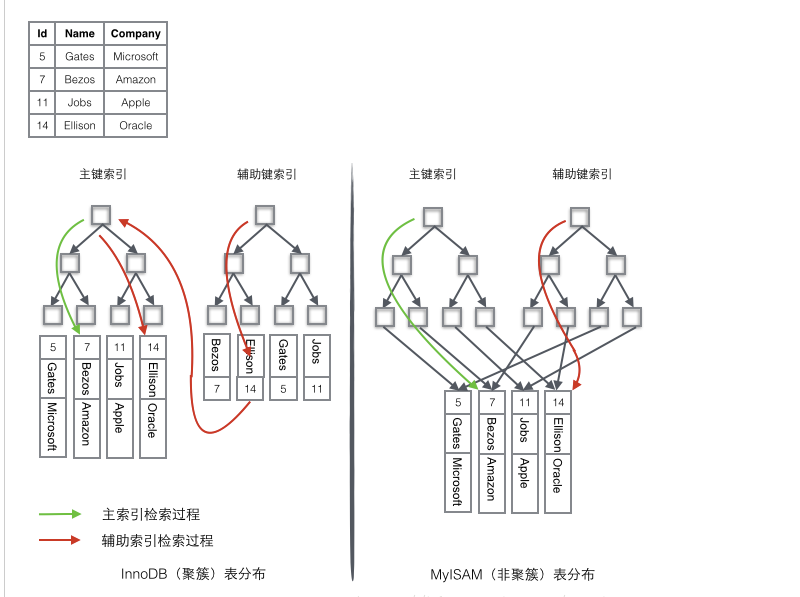
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。