论文总结:Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
简介
本文主要是对《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》进行总结。
Dynamic Memory Network主要是使用input-question-answer三元组作为输入,主要可以被用来解决序列标注问题,分类问题,sequence-to-sequence 任务以及问答任务。
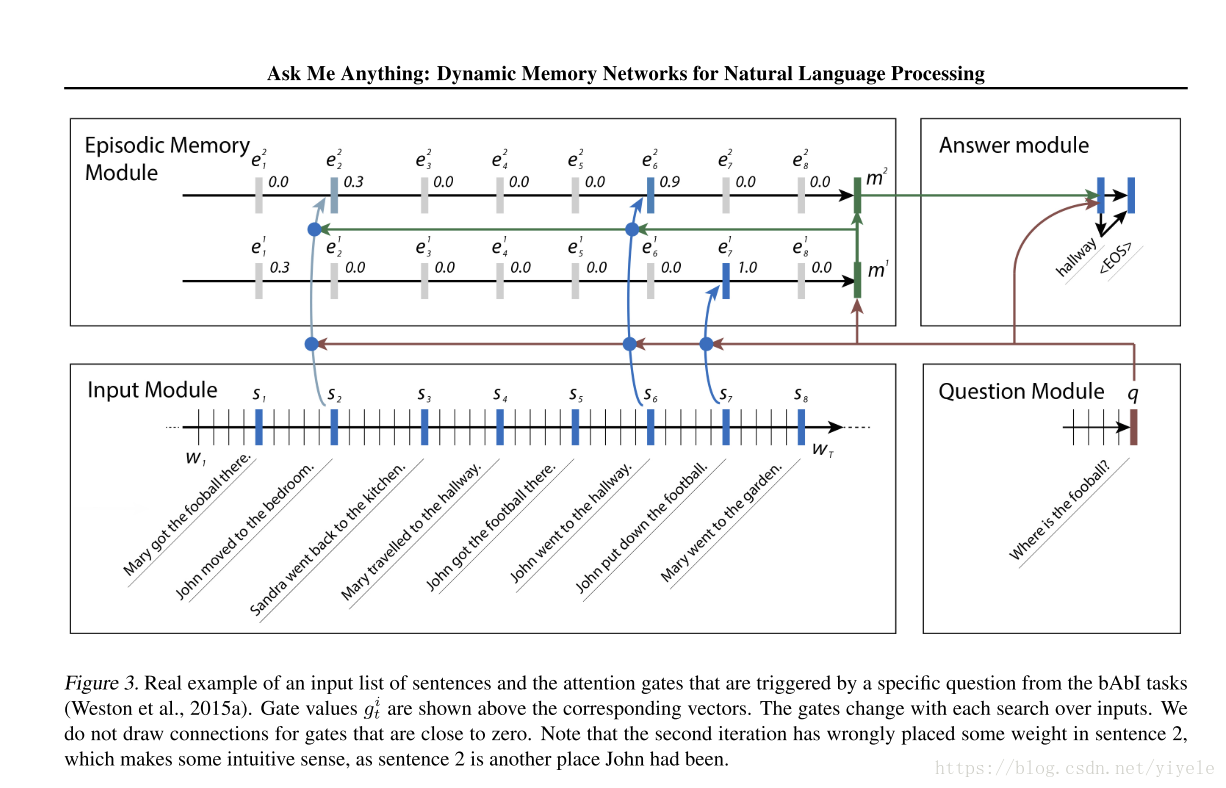
DMN首先计算所有input以及question的向量表示,然后question触发一个attention迭代的处理过程,主要是inputs中检索相关的facts。多次迭代过后,DMN memory module会提供一个表示所有相关的fact向量给answer module,然后由answer module生成答案。
DMN网络主要包括了四个模块,分别为Input Module,Question Module,Eposodic Memory Module以及Answer Module。
Input module主要是将raw text input转化为distributed vector representation。输入的文本可以是句子,长的故事,电影简介以及新的文章。
Question Module:与Input Module 类似,Question Module主要是将question encode成distributed vector representation。然后将输入作为Eposodic Memory Module的初始状态。
Episodic Memory Module:主要是通过attention决定输入的哪个部分需要关注,在每一次迭代中,会产生memory vector,主要是通过question以及previous memeory来跌迭代。每个迭代过程都能获取到新的信息。
Answer module:根据Memory module的生成的final memory vector来生成答案。
模型的主要结构如下图所示:
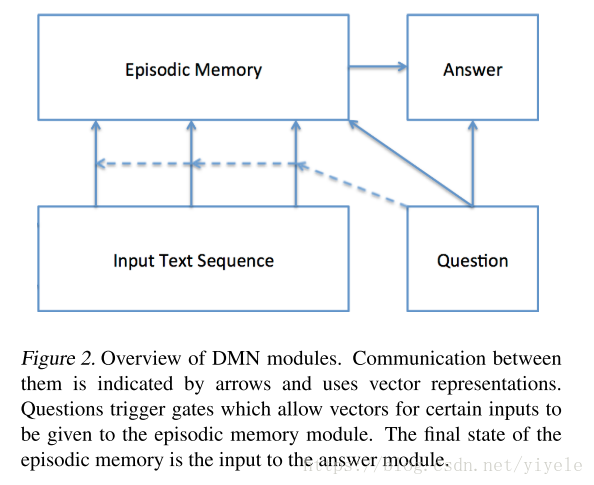
具体结构
Input Module
主要是使用GRU的网络结构,主要的计算过程如下图所示:

Question Module
questiion module中的q更新与Input module中的input更新一样,主要是使用GRU网络进行更新。
qt = GRU(L[wQt ], qt−1),L主要表示句子的向量表示,主要是通过将句子中的每个单词的embedding按照前后顺序进行连接。
Episodic Memory Module
这个模块主要包括了三个部分,分别为an internal memory,an attention mechansim和一个rnn(被用来更新memory)。
其中GRU的memory初始值为q,然后memory的更新过程为mi=GRU(ei,mi−1)。经过多次迭代后,最后的m被送到answer module。
这里需要注意的是,最后是进行多次的迭代,这样有利于信息的传递,或者说获取到更为完善的信息。
1)attention mechanism:
主要的公式如下:
其中z(c, m, q) 为:
其中,c表示Input Module的输入,m表示memory。q表示question module的输出。
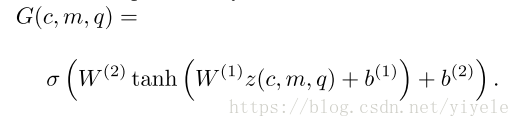
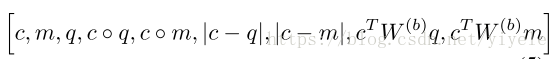
2)Memory Update Mechanism:
这个部分主要是为了计算episode。主要的计算过程如下:
3)总结,通过上面的介绍可以知道,Episode Memory Module的主要步骤为:首先将question module的GRU的最后一个Memory作为EMM的memory的初始值,首先根据input,memory,question计算attention,然后利用2)更新episode的值。最后将episode的值以及前一个memory的值作为GRU的输入,来更新memory。
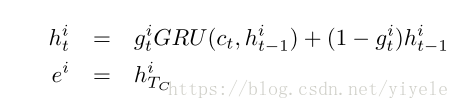
Answer Module
主要也是通过GRU网络进行更新。具体的公式如下所示:
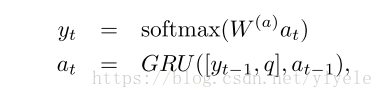
其中a初始化的值为episode memory module中最后memory的值。q为question。
主要的模型结构图如下所示:
具体的代码实现为:
def __init__(self, babi_train_raw, babi_test_raw, word2vec, word_vector_size,
dim, mode, answer_module, input_mask_mode, memory_hops, l2,
normalize_attention, **kwargs):
print "==> not used params in DMN class:", kwargs.keys()
self.vocab = {}
self.ivocab = {}
self.word2vec = word2vec
self.word_vector_size = word_vector_size
self.dim = dim
self.mode = mode
self.answer_module = answer_module
self.input_mask_mode = input_mask_mode
self.memory_hops = memory_hops
self.l2 = l2
self.normalize_attention = normalize_attention
self.train_input, self.train_q, self.train_answer, self.train_input_mask = self._process_input(babi_train_raw)
self.test_input, self.test_q, self.test_answer, self.test_input_mask = self._process_input(babi_test_raw)
self.vocab_size = len(self.vocab)
self.input_var = T.matrix('input_var')
self.q_var = T.matrix('question_var')
self.answer_var = T.iscalar('answer_var')
self.input_mask_var = T.ivector('input_mask_var')
print "==> building input module"
self.W_inp_res_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.word_vector_size))
self.W_inp_res_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_inp_res = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_inp_upd_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.word_vector_size))
self.W_inp_upd_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_inp_upd = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_inp_hid_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.word_vector_size))
self.W_inp_hid_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_inp_hid = nn_utils.constant_param(value=0.0, shape=(self.dim,))
inp_c_history, _ = theano.scan(fn=self.input_gru_step,
sequences=self.input_var,
outputs_info=T.zeros_like(self.b_inp_hid))
self.inp_c = inp_c_history.take(self.input_mask_var, axis=0)
self.q_q, _ = theano.scan(fn=self.input_gru_step,
sequences=self.q_var,
outputs_info=T.zeros_like(self.b_inp_hid))
self.q_q = self.q_q[-1]
print "==> creating parameters for memory module"
self.W_mem_res_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.W_mem_res_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_mem_res = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_mem_upd_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.W_mem_upd_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_mem_upd = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_mem_hid_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.W_mem_hid_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_mem_hid = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_b = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.W_1 = nn_utils.normal_param(std=0.1, shape=(self.dim, 7 * self.dim + 2))
self.W_2 = nn_utils.normal_param(std=0.1, shape=(1, self.dim))
self.b_1 = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.b_2 = nn_utils.constant_param(value=0.0, shape=(1,))
print "==> building episodic memory module (fixed number of steps: %d)" % self.memory_hops
memory = [self.q_q.copy()]
for iter in range(1, self.memory_hops + 1):
current_episode = self.new_episode(memory[iter - 1])
memory.append(self.GRU_update(memory[iter - 1], current_episode,
self.W_mem_res_in, self.W_mem_res_hid, self.b_mem_res,
self.W_mem_upd_in, self.W_mem_upd_hid, self.b_mem_upd,
self.W_mem_hid_in, self.W_mem_hid_hid, self.b_mem_hid))
last_mem = memory[-1]
print "==> building answer module"
self.W_a = nn_utils.normal_param(std=0.1, shape=(self.vocab_size, self.dim))
if self.answer_module == 'feedforward':
self.prediction = nn_utils.softmax(T.dot(self.W_a, last_mem))
elif self.answer_module == 'recurrent':
self.W_ans_res_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim + self.vocab_size))
self.W_ans_res_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_ans_res = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_ans_upd_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim + self.vocab_size))
self.W_ans_upd_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_ans_upd = nn_utils.constant_param(value=0.0, shape=(self.dim,))
self.W_ans_hid_in = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim + self.vocab_size))
self.W_ans_hid_hid = nn_utils.normal_param(std=0.1, shape=(self.dim, self.dim))
self.b_ans_hid = nn_utils.constant_param(value=0.0, shape=(self.dim,))
def answer_step(prev_a, prev_y):
a = self.GRU_update(prev_a, T.concatenate([prev_y, self.q_q]),
self.W_ans_res_in, self.W_ans_res_hid, self.b_ans_res,
self.W_ans_upd_in, self.W_ans_upd_hid, self.b_ans_upd,
self.W_ans_hid_in, self.W_ans_hid_hid, self.b_ans_hid)
y = nn_utils.softmax(T.dot(self.W_a, a))
return [a, y]
# TODO: add conditional ending
dummy = theano.shared(np.zeros((self.vocab_size, ), dtype=floatX))
results, updates = theano.scan(fn=answer_step,
outputs_info=[last_mem, T.zeros_like(dummy)],
n_steps=1)
self.prediction = results[1][-1]
else:
raise Exception("invalid answer_module")
print "==> collecting all parameters"
self.params = [self.W_inp_res_in, self.W_inp_res_hid, self.b_inp_res,
self.W_inp_upd_in, self.W_inp_upd_hid, self.b_inp_upd,
self.W_inp_hid_in, self.W_inp_hid_hid, self.b_inp_hid,
self.W_mem_res_in, self.W_mem_res_hid, self.b_mem_res,
self.W_mem_upd_in, self.W_mem_upd_hid, self.b_mem_upd,
self.W_mem_hid_in, self.W_mem_hid_hid, self.b_mem_hid,
self.W_b, self.W_1, self.W_2, self.b_1, self.b_2, self.W_a]
if self.answer_module == 'recurrent':
self.params = self.params + [self.W_ans_res_in, self.W_ans_res_hid, self.b_ans_res,
self.W_ans_upd_in, self.W_ans_upd_hid, self.b_ans_upd,
self.W_ans_hid_in, self.W_ans_hid_hid, self.b_ans_hid]
print "==> building loss layer and computing updates"
self.loss_ce = T.nnet.categorical_crossentropy(self.prediction.dimshuffle('x', 0), T.stack([self.answer_var]))[0]
if self.l2 > 0:
self.loss_l2 = self.l2 * nn_utils.l2_reg(self.params)
else:
self.loss_l2 = 0
self.loss = self.loss_ce + self.loss_l2
updates = lasagne.updates.adadelta(self.loss, self.params)
if self.mode == 'train':
print "==> compiling train_fn"
self.train_fn = theano.function(inputs=[self.input_var, self.q_var, self.answer_var, self.input_mask_var],
outputs=[self.prediction, self.loss],
updates=updates)
print "==> compiling test_fn"
self.test_fn = theano.function(inputs=[self.input_var, self.q_var, self.answer_var, self.input_mask_var],
outputs=[self.prediction, self.loss, self.inp_c, self.q_q, last_mem])
if self.mode == 'train':
print "==> computing gradients (for debugging)"
gradient = T.grad(self.loss, self.params)
self.get_gradient_fn = theano.function(inputs=[self.input_var, self.q_var,
self.answer_var, self.input_mask_var], outputs=gradient)
def input_gru_step(self, x, prev_h):
return self.GRU_update(prev_h, x, self.W_inp_res_in, self.W_inp_res_hid, self.b_inp_res,
self.W_inp_upd_in, self.W_inp_upd_hid, self.b_inp_upd,
self.W_inp_hid_in, self.W_inp_hid_hid, self.b_inp_hid)
def GRU_update(self, h, x, W_res_in, W_res_hid, b_res,
W_upd_in, W_upd_hid, b_upd,
W_hid_in, W_hid_hid, b_hid):
""" mapping of our variables to symbols in DMN paper:
W_res_in = W^r
W_res_hid = U^r
b_res = b^r
W_upd_in = W^z
W_upd_hid = U^z
b_upd = b^z
W_hid_in = W
W_hid_hid = U
b_hid = b^h
"""
z = T.nnet.sigmoid(T.dot(W_upd_in, x) + T.dot(W_upd_hid, h) + b_upd)
r = T.nnet.sigmoid(T.dot(W_res_in, x) + T.dot(W_res_hid, h) + b_res)
_h = T.tanh(T.dot(W_hid_in, x) + r * T.dot(W_hid_hid, h) + b_hid)
return z * h + (1 - z) * _h
def new_episode(self, mem):
g, g_updates = theano.scan(fn=self.new_attention_step,
sequences=self.inp_c,
non_sequences=[mem, self.q_q],
outputs_info=T.zeros_like(self.inp_c[0][0]))
if (self.normalize_attention):
g = nn_utils.softmax(g)
e, e_updates = theano.scan(fn=self.new_episode_step,
sequences=[self.inp_c, g],
outputs_info=T.zeros_like(self.inp_c[0]))
return e[-1]
# attention的实现
def new_attention_step(self, ct, prev_g, mem, q_q):
cWq = T.stack([T.dot(T.dot(ct, self.W_b), q_q)])
cWm = T.stack([T.dot(T.dot(ct, self.W_b), mem)])
z = T.concatenate([ct, mem, q_q, ct * q_q, ct * mem, T.abs_(ct - q_q), T.abs_(ct - mem), cWq, cWm])
l_1 = T.dot(self.W_1, z) + self.b_1
l_1 = T.tanh(l_1)
l_2 = T.dot(self.W_2, l_1) + self.b_2
G = T.nnet.sigmoid(l_2)[0]
return G
def new_episode_step(self, ct, g, prev_h):
gru = self.GRU_update(prev_h, ct,
self.W_mem_res_in, self.W_mem_res_hid, self.b_mem_res,
self.W_mem_upd_in, self.W_mem_upd_hid, self.b_mem_upd,
self.W_mem_hid_in, self.W_mem_hid_hid, self.b_mem_hid)
h = g * gru + (1 - g) * prev_h
return h
