今天介绍向量空间中的投影,以及投影矩阵。
假设空间中有两个向量
a,b,
b 在
a 上的投影为
p,我们要计算出
p 到底是多少,如下图所示:
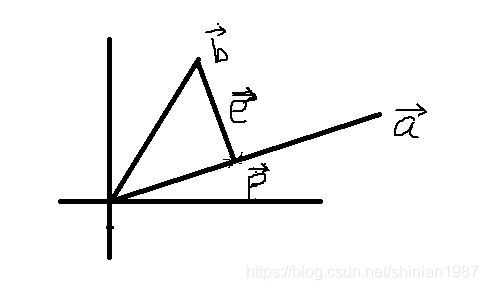
为了计算
p,我们可以先假设
p=xa,因为
p 是在
a 上,所以两者只差系数的关系,如上图所示,我们可以找到
b 和
p 的差:
e=b−p=b−xa,而我们又可以看出,
e 是和
a 垂直的,所以
e⋅a=aTe=0,我们可以进一步得到,
aT(b−xa)=0
所以:
aTb−xaTa=0
进而:
x=aTaaTb
所以:
p=xa=aTaaaTb
所以投影矩阵
P=aTaaaT
这是到直线的投影,如果是到矩阵的投影,我们也可以用类似的方法求得, 只是将上面的向量
a 换成矩阵
A ,假设向量
b 在矩阵
A 上的投影为
Ax,相当于向量
b 投影到了矩阵
A 的列空间上,而矩阵
A 的列空间与其 left-null 空间是互相垂直的,所以:
AT(b−Ax)=0
所以:
ATb−ATAx=0
进而:
x=(ATA)−1ATb
所以:
p=Ax=A(ATA)−1ATb
所以投影矩阵
P=A(ATA)−1AT
关于投影,最后多说几句,讲讲点到直线的距离,这个与机器学习中的 SVM 的最初的优化函数有关:
扫描二维码关注公众号,回复:
8630072 查看本文章

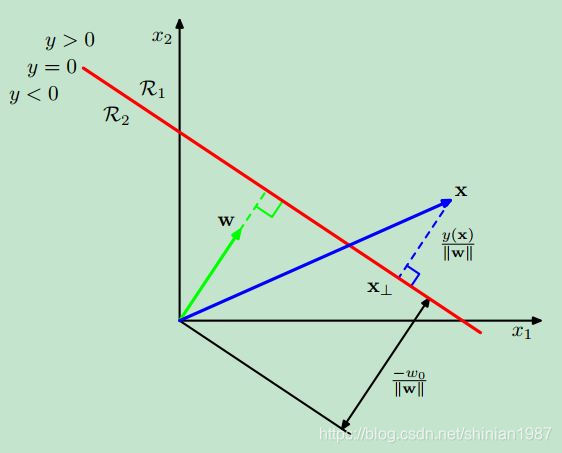
这个图是那本经典的机器学习教材 《Pattern Recognition and Machine Learning》里的,这个是想说明向量空间中,一个点到直线的距离。假设直线的表达式为
f(x)=wTx+w0,如果我们要求一个点
x 到该直线的距离,我们可以用上面说的投影来求这个距离, 假设点
x 到直线上的投影为
x⊥,如上图的
x⊥,而
x⊥ 到
x⊥ 的这个向量与
w 是平行的,所以我们可以得到如下的表达式:
x=x⊥+r∣∣w∣∣w
两边同时乘以
w 并且加上
w0, 可以得到:
wTx+w0=wTx⊥+w0+r∣∣w∣∣wTw
因为
x⊥ 在直线上,所以
wTx⊥+w0=0,进而,我们可以得到:
f(x)=r∣∣w∣∣⇒r=∣∣w∣∣f(x)
因为
∣∣w∣∣w 是单位向量,所以这个向量的幅值就是
r,所以点
x 到该直线的距离就是
r。这个距离的表达式,就是机器学习里 SVM 的基础,SVM 要优化的就是寻找这样一个
w 使得所有离该直线最近的点的距离最远,听起来好像有点绕哈~
