文章目录
前言
在前面的博客《深入理解Spark》 深入探讨了Spark架构原理内容,该文提到Stage的划分,为什么要做Stage划分?是为了得到更小的Task计算单元,分发给Executor的线程运行,将规模庞大、多流程的计算任务划分为有序的小颗粒的计算单元,实现更高效的计算。那么Stage划分怎么实现?需依赖RDD(Resilient Distributed Datasets,弹性分布式数据集),可以说,RDD是Spark最为核心的概念。本文内容部分参考了《弹性式数据集RDDs》以及《Spark官方文档》
1、RDD简介
RDD 是分布式的、可容错的、只读的、分区记录的弹性数据集合(在开发角度来看,它是一种数据结构,并是绑定了多个方法和属性的一种object),支持并行操作,可以由外部数据集或其他 RDD 转换而来,细读Resilient Distributed Dataset这三个单词,更深层的含义如下:
- Resilient: 弹性的,RDD如何体现出弹性呢?通过使用RDD血缘关系图——DAG,在丢失节点上重新计算上,弹性容错。
- Distributed:分布式的,RDD的数据集驻留在多个节点的内存中或者磁盘上(一分多)。
- Dataset: 在物理文件存储的数据
更具体的说明:
-
一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数。
(这一特点体现出RDD的分布式,RDD的分区是在多个节点上指定的,注意不是指把master分区拷贝到其他节点上,spark强调的是”移动数据不如移动计算“,避免跨节点拷贝分区数据。做这样假设:RDD如果不设计为多个分区,那么一个RDD就是代表一个超大数据集,而且只能在单机行运行,这跟Pandas的DataFrame区别就不大了。) -
Spark一个计算程序,往往会产生多个RDD,这些RDD会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算。
(这个特点就体现了RDD可恢复性,) -
Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区)。
(其实很多中间件或者组件只要涉及到Partition,必然少不了使用Partitioner(分区器),例如kafka的partition,Producer可通过对消息key取余将消息写入到不同副本分区上,例如redis的key在slot上分配,也是通过对key取余。) -
一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
2、创建RDD
-
由一个已经存在的Scala 数组创建或者Python列表创建。
val rdd0 = sc.parallelize(Array(1,2,3,4,5,6,7,8)) # Scala
val rdd0 = sc.parallelize([1,2,3,4,5,6,7,8]) # Python -
由外部存储系统的文件创建。包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、HBase等,其他流式数据:Socket流等。
val rdd2 = sc.textFile(“hdfs://nn:9000/data_files”)
sc是spark-shell内置创建的sparkcontext -
已有的RDD经过算子转换生成新的RDD
val rdd1=rdd0.flatMap(_.split(" "))
val rdd2=rdd1.map((_, 1))
3、宽依赖和窄依赖
在《深入理解Spark》 的第6章节”理解Spark Stage的划分“内容,正是RDD 与它的父 RDD(s) 之间的依赖关系,才有Stage划分的基础,主要为以下两种不同的依赖关系:
- 窄依赖 (narrow dependency):父 RDDs 的一个分区最多被子 RDDs 一个分区所依赖,一对一关系。例如Map、Filter、Union等算子。(你可以这样形象理解Spark为什么要用narrow这个词:从下图中例如Map算子,一个父rdd到一个子rdd的依赖关系,一条线直连关系,用窄形容恰当)
- 宽依赖 (wide dependency):父 RDDs 的一个分区可以被子 RDD 的多个分区所依赖,一对多关系。例如 groupByKey、reduceByKey、sortByKey等操作会产生宽依赖,会产生shuffling。(你可以这样形象理解Spark为什么要用wide这个词:从下图中例如groupByKey算子,一个父RDD有多条线连接到不同子RDD,用宽形容恰当)
- Lineage(血统)
例如RDD0转换为下一个RDD1,RDD1转换为下一个RDD2,RDD2转换为下一个RDD3,…,这一系列的转换过程叫做血统,可以构成DAG图(执行计划)
有何作用?当RDD3丢失,只需要使用Lineage关系图和重新计算RDD2,即可恢复出RDD3数据集。而无需从头RDD0重新计算,省时省力。
对于下图,每一个方框表示一个 RDD,带有颜色的矩形表示分区:
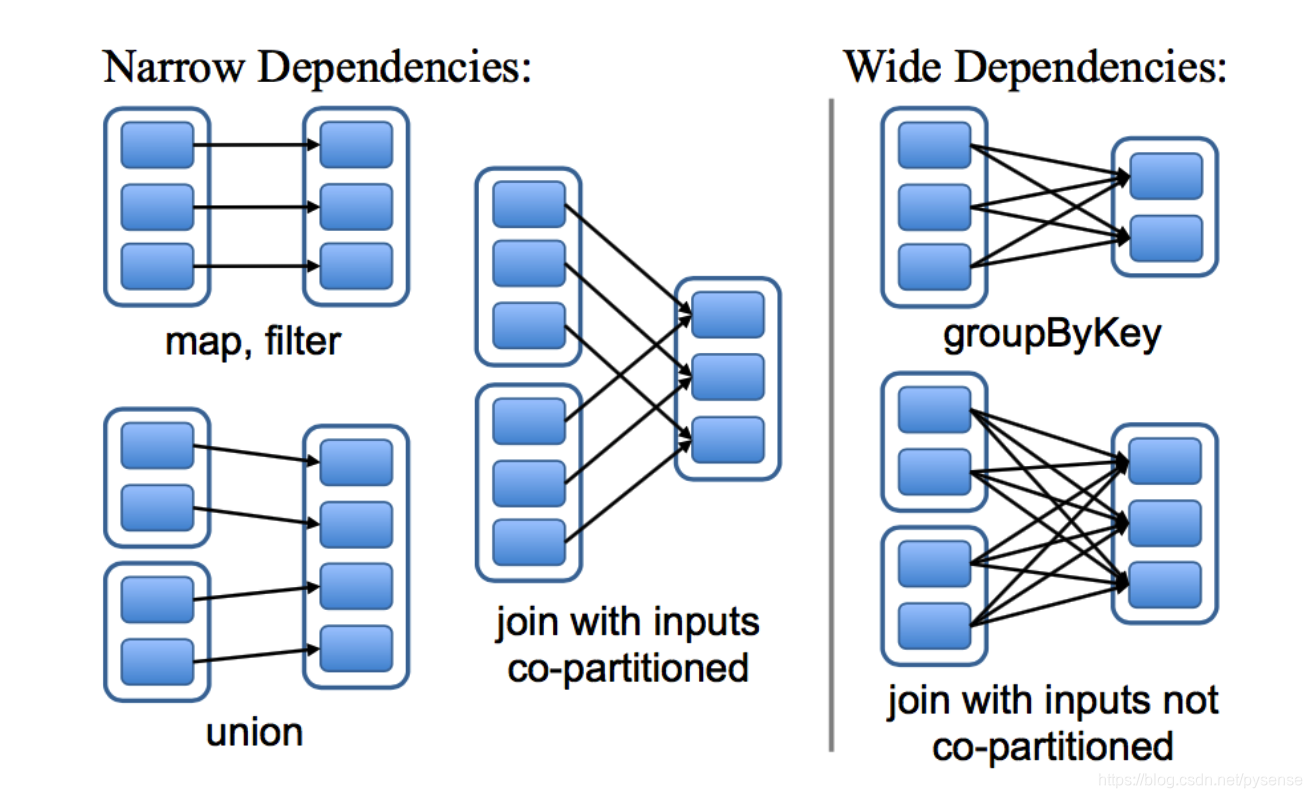 对于map、filter、union这些算子可以很直观看到它们所计算的rdd依赖关系是窄依赖
对于map、filter、union这些算子可以很直观看到它们所计算的rdd依赖关系是窄依赖
注意:对于join算子,如果是协同划分的话,两个父RDD之间, 父RDD与子RDD之间能形成一致的分区安排,即同一个Key保证被映射到同一个分区,这种join是窄依赖。(协同划分就是指定分区器以产生前后一致的分区安排)
如果不是协同划分,就会形成宽依赖。
这两种依赖关系除了可以把一个Job划分多个Stage,还有以下最为重要的两点作用:
第一:窄依赖可实现在当前节点上(数据无需夸节点传输)以流水线的方式(pipeline管道方式)对父分区数据进行流水线计算,例如先执行 Map算子,接着执行Filter算子,这两个操作一气呵成。而宽依赖则需要先计算好所有父分区的数据,接着将数据通过跨节点传递后执行shuffling(不跨节点,又怎么能把不同节点但key相同的项归并到同一分区上呢?所以宽依赖必然要进行磁盘IO和Socket跨节点传数据),这一过程与 MapReduce 类似。
第二:窄依赖能够更有效地进行数据恢复,根据上面”Lineage(血统)“所提的逻辑,只需重新对丢失子rdd的父rdd进行计算,且不同节点之间可以并行计算;而对于宽依赖而言,如果数据丢失,则需要对所有父分区数据重新计算并再次 shuffling,效率低而且耗时。
4、通过RDD的依赖关系构建DAG计算图
上面提到的多个RDD之间的两种依赖关系组成了 DAG,DAG 定义了这些 RDD之间的 Lineage链,通过血统关系(就像你手上拿了一张关系图谱),如果一个 RDD 的部分或者全部计算结果丢失了,也可以根据”这张关系图谱“重新进行计算出结果。Spark根据RDD依赖关系的不同将 DAG 划分为不同的执行阶段 (Stage):
- 对于窄依赖,由于分区的依赖关系是确定的,分区在当前节点上(数据无需夸节点传输)进行转换操作,也就是说可在同一个线程执行当前阶段计算任务,而且多个分区可以直接并行运行(因此分区数就决定并发计算的粒度,可用于Spark计算性能调优)。因此窄依赖的RDD可以划分到同一个执行阶段Stage;
- 对于宽依赖,由于 Shuffle 的存在,只能等多个父 RDD被 Shuffle 处理完成后(不同父分区的Shuffle导致数据需夸节点传输),才能开始对子RDD计算,因此遇到宽依赖就需要重新划分阶段。
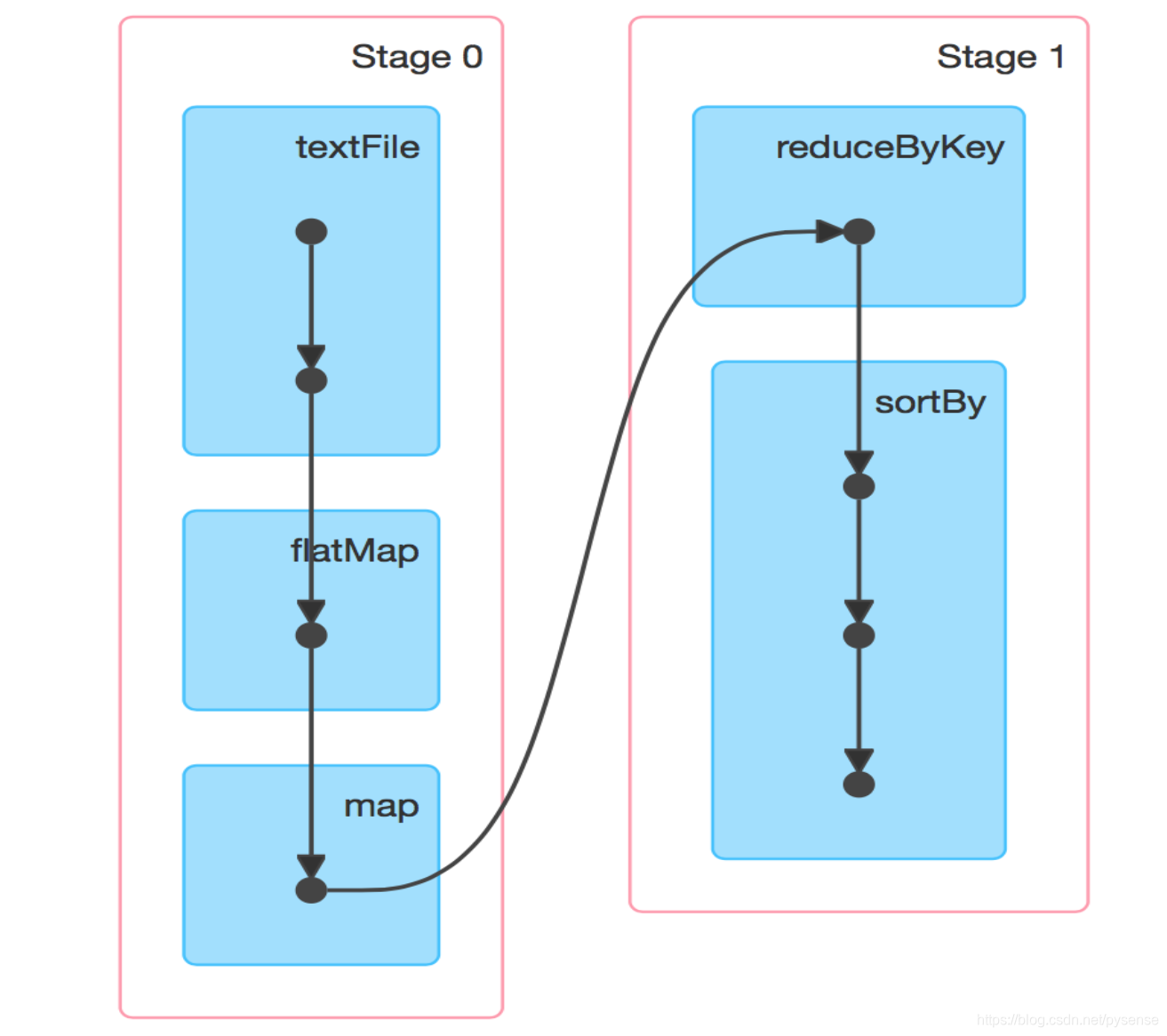
正是有了以上对Stage的划分设计,Spark在执行作业时, 生成一个完整的、最优的执行计划,从而比MapReduce”更加聪明地利用资源地“完成计算作业。
5、RDD 持久化
这一章节内容直接翻译spark:
RDD最重要的特点是可将数据集缓存在内存(或者磁盘上),这也是Spark之所以快的原因。使用RDD persist时,每个节点都会存储当前RDD计算的dataset,以便被其他RDD直接在内存加载使用,这种效果将使得之后的action算子至少提高10倍上计算速度。
通过调用persist()或者cache()方法即可触发RDD persist,而且持久化另外一个作用:Spark’s cache is fault-tolerant – if any partition of an RDD is lost, it will automatically be recomputed using the transformations that originally created it.(可根据已有的算子重新计算丢失的RDD)
Spark 在持久化 RDDs 的时候提供了 3 种storage level:存在内存中的非序列化的 java 对象、存在内存中的序列化的数据以及存储在磁盘中。第一种选择的性能是最好的,因为 JVM 可以很快的访问 RDD 的每一个元素。第二种选择是在内存有限的情况下,使的用户可以以很低的性能代价而选择的比 java 对象图更加高效的内存存储的方式。如果内存完全不够存储的下很大的 RDDs,而且计算这个 RDD 又很费时的,那么选择第三种方式。
The full set of storage levels is:
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they’re needed. This is the default level. |
| MEMORY_AND_DISK | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, store the partitions that don’t fit on disk, and read them from there when they’re needed. |
| MEMORY_ONLY_SER (Java and Scala) | Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
| MEMORY_AND_DISK_SER (Java and Scala) | Similar to MEMORY_ONLY_SER, but spill partitions that don’t fit in memory to disk instead of recomputing them on the fly each time they’re needed. |
| DISK_ONLY | Store the RDD partitions only on disk. |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | Same as the levels above, but replicate each partition on two cluster nodes. |
| OFF_HEAP (experimental) | Similar to MEMORY_ONLY_SER, but store the data in off-heap memory. This requires off-heap memory to be enabled. |
Note: In Python, stored objects will always be serialized with the Pickle library, so it does not matter whether you choose a serialized level. The available storage levels in Python include MEMORY_ONLY, MEMORY_ONLY_2, MEMORY_AND_DISK, MEMORY_AND_DISK_2, DISK_ONLY, and DISK_ONLY_2.
注意对使用Python来开发spark的话,它存储的对象都是由Pickle库实现序列化,因此对于python,除了OFF_HEAP这个level,其他level都适用。
Spark also automatically persists some intermediate data in shuffle operations (e.g. reduceByKey), even without users calling persist. This is done to avoid recomputing the entire input if a node fails during the shuffle. We still recommend users call persist on the resulting RDD if they plan to reuse it.
此外Spark在shuffle操作例如reduceByKey这类操作时会自动对RDD做持久化,以防止某些节点再做shuffle过程中挂了导致需要重新计算父RDD。Spark建议使用者在RDD需要重新使用的场景下可先持久化RDD。
6、RDD的checkpointing机制
前面提到对于要恢复某些丢失的RDD,可根据父 RDDs 的血缘关系recomputed,但是如果这个血缘关系链很长的话(例如业务逻辑里面有10来个transmissions以及有多个actions),则recomputed需要耗费很长时间,因此在这种场景下,将一些 RDDs 的数据持久化到稳定存储系统中是有必要的。
checkpointing 对具有很长的血缘关系链且包含了宽依赖的 RDDs 是非常有用的,比如spark给出的PageRank 例子,在这些场景下,集群中的某个节点的失败会导致每一个父亲 RDD 的一些数据的丢失,最惨的是这些父RDD都是宽依赖以及很长的窄依赖链关系,显然需要重新所有的计算。
对于普通的窄依赖的 RDDs(spark给出例子中线性回归例子中的 points 和 PageRank 中的 link 列表数据),checkpointing 可能一点用都没有。如果一个节点失败了,spark照应可以很快在其他的节点中并行的重新计算出丢失了数据的分区,这个成本只是备份整个 RDD 的成本的一点点而已。
Spark 目前提供了一个 checkpointing 的 api(persist 中的标识为 REPLICATE,还有 checkpoint()),用户自行选择在一些最佳的 RDDs 来进行 checkpointing,以达到最小化恢复时间。(这就像你玩过关类游戏,总共20关,这个游戏本身没有自动保存检查点,必须用户自己触发,在第19关是最难的关卡耗费一周时间拿下,而你确忘记存档,能不崩溃吗)
7、Spark分区与RDD分区(待更新)
这部分内容难度较大,但确实能真正理解Spark和RDD并行计算的底层逻辑,相关知识点需回顾hadoop文件分区。这部分内容待更新
