1、什么是RDD
RDD(分布式弹性数据集)是对分布式计算的抽象,代表要处理的数据,一个数据集,RDD是只读分区的集合。数据被分片,分成若干个数据分片,存储到不同的节点中,可以被并行的操作,所以叫分布式数据集。计算时优先考虑放于内存中,如果放不下把一部分放在磁盘上保存。
RDD(分布式弹性数据集)是整个Spark抽象的基石,是基于工作集的应用抽象。Spark的各个子框架,Spark SQL、Spark Streaming、SparkR、GraphX、ML等,其底层封装的都是RDD。(也就是说①RDD提供了通用的抽象;②开发者可用根据自己所在的领域进行建模,开发出相应的子框架)。
RDD本身会有一系列的数据分片,RDD在逻辑上抽象的代表了底层的一个输入文件,可能是一个文件夹,但是实际上是按分区partition分为多个分区,分区会放在Spark集群中不同的机器节点上,假设有1亿条数据,可能每台机器上放10万条,需要1000台机器,而且这1000台机器上的10万条数据是按照partition为单位去管理的。所谓partition就是特定规模的数据大小,就是数据集合。Spark中一切操作皆RDD。
2、工作集与数据集
基于工作集和基于数据集都提供一些特征如位置感知(具体数据在哪里,只不过是不同的实现),容错,负载均衡。
(1)基于数据集的工作方式:从物理存储加载数据,然后操作数据,然后写入物理存储设备。如Hadoop的MapReduce是基于数据集的。基于数据集的有几种场景不太适用:①不适合大量的迭代,如机器学习,算法比较复杂的时候②不适合交互式查询,每次的查询都需要从磁盘读取数据,然后再查询写会数据结果,每一次都这样。(重点是基于数据集的方式不能改复用曾的结果或计算中间结果)
(2)基于工作集的工作方式,具有基于数据集的工作方式的优点即自动容错、位置感知性调度和可伸缩性,同时够对基于工作集的计算任务也具有良好的描述能力,即支持中间结果的复用场景。
3、RDD的弹性表现在哪几个方面
Spark的RDD是基于工作集的,不仅具具有基于数据集的特点,而且RDD本身还有其特点:Resilient(弹性).
(1)自动进行内存和磁盘的数据存储的切换:RDD代表一系列数据分片在不同的节点中存储,默认优先考虑在内存中,如果放不下把一部分放在磁盘上保存,而这一切对用户来说是透明的,不用关心RDD的partition放在哪里,只要针对RDD计算处理就行了。所以说RDD本身会自动的进行磁盘和内存的切换;
(2)自动Lineage血统的高效容错:在运行阶段,会有一系列的RDD,以用于容错恢复,假设一个计算链条有900个步骤,假设第888步出错,由于有血统关系,可以从第887个步骤恢复,不需要从第一个步骤开始计算,这极大的提升了错误恢复的速度;
(3)task失败会自动进行特定次数的重试,默认4次:假设900个计算步骤的任务作为一个task,进行容错,恢复的时候从第800个步骤开始恢复,恢复好几次都没有成功这个task就失败了,调度器底层会自动进行容错。
(4)Stage(一个计算阶段)如果失败,会自动进行特定次数的重试,只计算失败的数据分片,默认3次:就是task底层尝试好几次都失败,这个时候整个阶段就会失败,整个阶段会有很多并行的数据分片,他们计算逻辑一样只是处理的数据分片不一样。是再次提交Stage的时候如果这个Stage中假设有100个数据分片只是3,5个失败,再次提交Stage的时候会看看其他成功的任务有没有输出,有的话就不会第二次提交的时候把这100个任务再次提交,只会提交失败的那几个。
(5)checkpoint和persist:checkpoint(每次对RDD的操作都会产生新的RDD,除了action触发job以外,有时处理链条比较长,计算比较笨重时,需要考虑将数据落地);persist:(内存、磁盘的复用[效率和容错的延伸])
(6)数据调度弹性:DAG TASK 和资源管理无关
(7)数据分片的高度弹性:repartition和coalesce①在数据计算时,会产生很多分片,这时如果partition非常小,每个分片每次都消耗一个线程进行处理,会降低处理效率,但是如果把把几个partition合并成一个比较大的partition,会提高效率②如果每个partition的block比较大可能内存不足,这时会考虑将其变成更小的分片,这时Spark会出现更多的处理批次,避险出现OOM
注意:repartition内部调用的是coalesce,传进的shuffle为true。coalesce默认shuffle为fasle。所以数据分片由多变为少的用coalesce不进行shuffle,如果数据分片由少到多不经过shuffle是不行的,使用repartition。


4、RDD的lazy特性
由于RDD是只读分区的集合,那么每次的操作都会改变数据,会产生中间结果,这时就采用lazy的级别,对数据不进行计算。
RDD的核心之一就是他的lazy级别,因为不算,开始的时候只对数据处理做标记,包括textfile根本不从磁盘读数据,faltMap根本就没开始计算,他只不过是产生了一个操作的标记而已。

上图为flatMap的源码,flatMap产生了一个new MapPartitionRDD,但是看它的构造,第一个参数是this,this是当前对象,指父RDD,即生成的RDD所依赖的RDD。这样,Spark的RDD是只读的,且是lazy级别的,每次构建的新的RDD时,都是将其父RDD作为第一个参数传递进来生成新的RDD,这样就构成了一个链条结构
5、常规的容错方式
常规的容错方式:数据检查点和记录数据更新的方式。
5.1 数据检查点
分布式的计算数据检查点的基本工作方式就是:通过数据中心的网络连接,不同的机器每次操作的时候都要负责整个数据集,就相当于每次都有一个拷贝,这个是需要网络的,复制到其他机器上,而网络带宽就是分布式的瓶颈。每次拷贝对存储资源也是非常大的消耗。
5.2 记录数据更新
记录数据更新的工作方式:每次数据变化我们就记录一下,这个方式不需要重新拷贝一份数据,但是这种方式复杂,而且更新的话就变成数据可更新,那很多操作全局数据容易失控,原子性对分布式来说太可怕了第一复杂第二耗性能。
因为RDD是从后往前的链条依赖关系,所以容错的开销非常低
5.3 Spark的RDD的容错方式
Spark就是记录数据更新的方式,原因又2点:①、RDD是不可变的+lazy(因为不可变不存在全局修改的问题,控制难度就极大的下降,在这基础上有计算链条,假设901个步骤错了,从900个步骤开始恢复(这个前提是要持久化persit/checkpoint或者上一个Stage结束))。②RDD是粗粒度的操作,为了效率,每次操作的时候作用所有数据集合(所谓的粗粒度就是每次操作都作用于全部的数据集)。如果更新力度太细记录成本就会高效率就低了。对RDD的所有写或者修改都是粗粒度的,通过元数据记录数据更新是写操作,我们在这边说RDD是粗粒度的指的是RDD的写操作是粗粒度的,但是RDD的读操作即可是粗粒度的也可以是细粒度的(例如通过RDD读取数据库可以读取一条记录)。RDD的写操作是粗粒度的限制了他的使用场景,例如说网络爬虫就不适合,但是现实世界中,大多数的场景是粗粒度的
5.4 RDD中的几个核心方法及属性
(1)partitioner:分区器,类似MapReduce的的Partitioner接口,控制key到哪个reduce

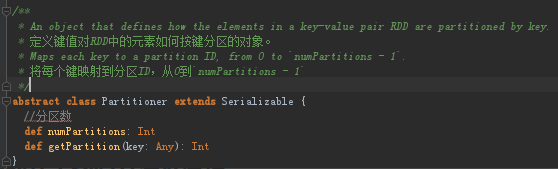
(2)compute:compute方法是针对RDD的每个Partition进行计算的

所有的RDD操作返回的都是一个迭代器,这个好处就是假设用spark sql提取出数据后产生新的RDD,机器学习访问这个RDD不用关心他是不是sparksql,因为是基于iterator,那就可以用hasNext看下有么有下个元素,用next读取下个元素,这就让所有框架无缝集成。
compute传进的第一个参数split是Partition类型的,Partition是RDD并行的划分单元,其在Spark中的抽象定义十分简单如下:

它定义了一个index唯一表示这个partition,它更像一个指针指向实体数据,Partition的具体实现有很多,包括HadoopPartition, JdbcPartition, ParallelCollectionPartition等。
(3)getPartition:getPartitions返回的是一系列partitions的集合,即一个Partition类型的数组。是在partitions方法中调用getPartition方法的。

(4)getDependencies:获取所有依赖关系

(5)getPreferredLocations:输入参数是Partition类型的split分片,输出结果是一组优先的节点位置。

5.5 HadoopRDD
(1)getPartition实现
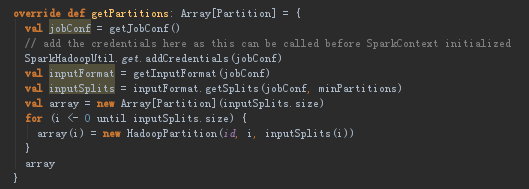
首先getJobConf():用来获取job Configuration,获取配置方式有clone和非clone方式,clone方式是线程不安全的,,非clone方式可以从cache中获取,如cache中没有那就创建一个新的,然后再放到cache中;然后获得InputFormat实例对象;调用getSplits方法来计算分片,然后把分片HadoopPartition包装到到array里面返回
(2)compute实现
![]()
输入值是一个Partition,返回是一个Iterator[(K, V)]类型的数,compute方法是通过分片来获得Iterator接口,以遍历分片的数据![]() 把Partition转成HadoopPartition
把Partition转成HadoopPartition

通过InputSplit创建一个RecordReader

重写Iterator的getNext方法,通过创建的reader调用next方法读取下一个值
(3)getPreferredLocations

调用InputSplit的getLocations方法获得所在的位置
6、RDD的生命周期
6.1 创建RDD
Spark程序中创建的第一个RDD代表了Spark应用程序输入数据的来源。通过Transformation来对RDD进行各种算子的转换,实现算法。
常见的创建初始RDD的方式①使用程序中的集合,②使用本地文件系统创建RDD,③使用HDFS创建RDD,④基于DB创建RDD,⑤基于NOSQL创建RDD,⑥基于S3创建RDD,⑦基于数据流创建RDD
6.2 构建执行计划
RDD 在调用Transformation算子和action 算子后构成一个RDD链条,即血缘,然后DAGScheduler 会根据 RDD 之间的依赖关系划分Stage ,最后终封装成 TaskSetManager 根据不同的调度模型加入不同的调度队列。
6.3 调度任务执行
由 TaskScheduler和TaskSetManager 对TaskSet进行进一步资源封装和最佳位置计算,然后进行调度到相应的Executor上去执行。
6.4 结果返回
将最终的执行结果返回给 Driver 或者输出到指定的位置。
7、RDD的操作类型
RDD本身有3种操作类型Transformation和Action和Controller。
Transformation进行数据状态的转换,根据已有的RDD创建一个新的RDD;Action触发具体的作业,主要是对RDD进行最后取结果的一种操作;Controller(是控制算子,包括cache,persist,checkpoint)对性能,效率还有容错方面的支持。
Transformation级别的RDD是lazy的,也就是说使用Transformation只是标记对我们的数据进行操作,不会真正的执行,这是算法的描述,当我们遇到Action或者checkpoint的时候他才会真正的操作。通过这种lazy特性,底层就可以对我们spark应用程序优化,因为一直是延迟执行,spark框架可以看见很多步骤,看见步骤越多优化的空间就越大。
8、常用的算子
81 map
map:使用自定义的函数f,对其中的每个元素进行处理,产生U类型的结果,传入的RDD的元素类型为T类型,生成的RDD元素类型为U类型

withScope{body} 是为了确保运行body代码块产生的所有RDDs都在同一个scope里面。首先调用了SparkContext的clean方法,实际上调用了ClosureCleaner的clean方法,这里一再清除闭包中的不能序列化的变量,防止RDD在网络传输过程中反序列化失败。(scala支持闭包(jvm上的闭包当然也是一个对像),闭包会把它对外的引用(闭包里面引用了闭包外面的对像)保存到自己内部, 这个闭包就可以被单独使用了,而不用担心它脱离了当前的作用域; 但是在spark这种分布式环境里,这种作法会带来问题,如果对外部的引用是不可serializable的,它就不能正确被发送到worker节点上去了; 还有一些引用,可能根本没有用到,这些没有使用到的引用是不需要被发到worker上的; ClosureCleaner.clean()就是用来完成这个事的; ClosureCleaner.clean()通过递归遍历闭包里面的引用,检查不能serializable的, 去除unused的引用; 这个方法在SparkContext中用得很多,对rpc方法,只要传入的是闭包,基本都会使用这个方法,它可以降低网络io,提高executor的内存效率)然后new了一个MapPartitionsRDD,还把清除闭包中的不能序列化的变量的匿名函数f传进去。MapPartitionsRDD源码如下

MapPartitionsRDD继承RDD[U](prev),他的源码如下。它把RDD复制给了deps,这个OneToOneDependency是一个窄依赖,子RDD直接依赖于父RDD。

MapPartitionsRDD重写了Partitioner,getPartitions,compute和clearDependencies,发现大量出现firstParent[T]源码如下,返回第一个父RDD

所以partitioner和它的第一个parent RDD的partitioner保持一致(如果需要保留partitioner的话),它的partitions就是它的firstParent的partitions。它的compute函数只是调用了flatMap实例化它时输入的函数,compute函数是在父RDD遍历每一行数据时只是调用了flatMap实例化它时输入的函数。
看compute实际传递的函数和调用它的代码,iter:Iterator[T]是一个Partition上的元素迭代器,用来遍历RDD[T]的第pid个partition上的所有元素。 firstParent[T].iterator(split, context) 就是返回parentRDD的对应partition的迭代器iter:Iterator[T]: 如果已经保存了就直接读取,否则重新计算(可以跳转看它的实现)。有了这个迭代器iter之后,然后用 iter.flatMap(cleanF) 来产生新的迭代器,返回类型是Iterator[U],这个就是最终返回的RDD: RDD[U]的partition的迭代器。
compute函数作用:在没有依赖的条件下,根据分片的信息生成遍历数据的Iterable接口;在有前置依赖的条件下,在父RDD的Iterable接口上给遍历每个元素的时候再套上一个方法

8.2 flatMap
flatMap:使用自定义的函数f,对其中的每个元素进行处理,将产生的结果合并成一个大的集合。
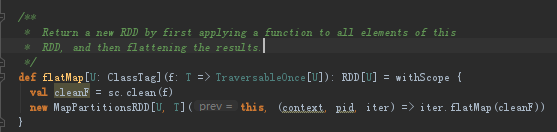

flatMap和map函数区别主要在于:map调用的是迭代器的map方法,flatMap调用的是迭代器的flatMap方法是针对RDD的每个元素利用函数f生成多个元素,然后把这些结果全部串联起来
8.3 reduceByKey
reduceByKey这个方法不是在RDD中的,而是在PairRDDFunctions里面,因为在RDD的伴生对象里面已经导入了,RDD内部会发生隐式转换,转换为PairRDDFunctions,然后再调用这个方法。

reduceByKey内部调用的是combineByKey

底层是基于combineByKeyWithClassTag的,combineByKey是combineByKeyWithClassTag的简写的版本


require方法首先判断mergeCombiners(定义两个C类型数据的组合函数)是否定义,没有则抛异常
![]()
然后keyClass.isArray判断如果key是Array类型,是不支持在map端合并的(mapSideCombine默认为true即进行本地预聚合),也不支持HashPartitioner(要想进行Map段合并和Hash分区,那么Key就必须可以通过比较内容是否相同来确定Key是否相等以及通过内容计算hash值,进而进行合并和分区,然而数组判断相等和计算hash值并不是根据它里面的内容,而是根据数组在堆栈中的信息来实现的。);
然后 Aggregator创建一个聚合器,用于对数据进行聚合,对参数函数执行clean方法保证是可以被序列化的。Aggregator是核心,聚合全是交给它来完成的

Aggregator的三个泛型,第一个K,这个是你进行combineByKey也就是聚合的条件Key,可以是任意类型。后面的V,C两个泛型是需要聚合的值的类型,和聚合后的值的类型,两个类型是可以一样,也可以不一样,例如,Spark中用的多的reduceByKey这个方法,若聚合前的值为long,那么聚合后仍为long。再比如groupByKey,若聚合前为String,那么聚合后为Iterable<String>。再看三个自定义方法:①createCombiner:这个方法会在每个分区上都执行的,而且只要在分区里碰到在本分区里没有处理过的Key,就会执行该方法。执行的结果就是在本分区里得到指定Key的聚合类型C(可以是数组,也可以是一个值,具体还是得看方法的定义了。) ② mergeValue:这方法也会在每个分区上都执行的,和createCombiner不同,它主要是在分区里碰到在本分区内已经处理过的Key才执行该方法,执行的结果就是将目前碰到的Key的值聚合到已有的聚合类型C中。其实方法1和2放在一起看,就是一个if判断条件,进来一个Key,就去判断一下若以前没出现过就执行方法1,否则执行方法2. ③mergeCombiner:前两个方法是实现分区内部的相同Key值的数据合并,而这个方法主要用于分区间的相同Key值的数据合并,形成最终的结果。
然后看下他的三个方法:①combineValuesByKey:实现的就是分区内部的数据合并②combineCombinersByKey:主要是实现分区间的数据合并,也就是合并combineValuesByKey的结果③updateMetrics:刷磁盘有关,就是记录下,当前是否刷了磁盘,刷了多少
回到combineByKeyWithClassTag方法中, 实例化Aggregator后,接着就是判断,是否需要重新分区(shuffle)。然后self.partitioner == Some(partitioner)判断分区器是否相同如果分区器相同,self.partitioner是指A这个RDD的partitioner,它指明了A这个RDD中的每个key在哪个partition中。而等号右边的partitioner,指明了B这个RDD的每个key在哪个partition中。当二者==时,就会用self.mapPartitions生成MapPartitionsRDD, 这和map这种transformation生成的RDD是一样的,此时reduceByKey不会引发shuffle。
①当self.partitioner == Some(partitioner)时,也就是分区实例是同一个的时候,就不需要分区了,因此只需要对先用的分区进行combineValuesByKey操作就好了,没有分区间的合并了,也不需要shuffle了。②两个分区器不一样,需要对现在分区的零散数据按Key重新分区,目的就是在于将相同的Key汇集到同一个分区上,由于数据分布的不确定性,因此有可能现在的每个分区的数据是由重新分区后的所有分区的部分数据构成的(宽依赖),因此需要shuffle,则构建ShuffledRDD
combineByKey的关键在于分区器partitioner,它是针对分区的一个操作,分区器的选择就决定了执行combineByKey后的结果,如果所给的分区器不能保证相同的Key值被分区到同一个分区,那么最终的合并的结果可能存在多个分区里有相同的Key。Shuffle的目的就是将零散于所有分区的数据按Key分区并集中。
8.4 join
join就是sql中的inner join。join也是PairRDDFunctions中的方法,sparkcore中支持的连接有:笛卡尔积、内连接join,外连接(左leftOuterJoin、右rightOuterJoin、全fullOuterJoin)


不指定分区函数时默认使用HashPartitioner;提供numPartitions参数时,其内部的分区函数是HashPartitioner(numPartitions)

我们发现join的内部其实是调用cogroup。即rdd1.join(rdd2) => rdd1.cogroup(rdd2,partitioner) => flatMapValues(遍历两个value的迭代器)。
返回值的是(key,(v1,v2))这种形式的元组
8.5 cogroup

首先先判断一下如果使用HashPartitioner分区,并且key是数组的话抛异常。然后构造一个CoGroupedRDD其键值对中的value要求是Iterable[V]和Iterable[W]类型。

重写的RDD的getDependencies: 如果rdd和给定分区函数相同就是窄依赖,否则就是宽依赖

这里返回一个带有Partitioner.numPartitions个分区类型为CoGroupPartition的数组
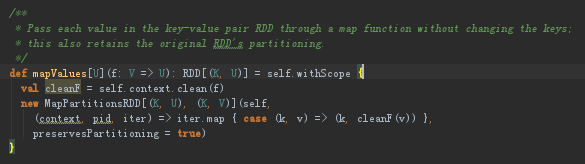
总结:cogroup算子,根据rdd1,rdd2创建了一个CoGroupedRDD;分析了CoGroupedRDD的依赖关系,看到如果两个rdd的分区函数相同,那么生成的rdd分区数不变,它们之间是一对一依赖,也就是窄依赖,从而可以减少依次shuffle;CoGroupedRDD的分区函数就是将两个rdd的相同分区索引的分区合成一个新的分区,并且通过NarrowCoGroupSplitDep这个类实现了序列化。
join返回的类型是 RDD[(K, (V, W))],CoGroup返回的是RDD[(K, (Iterable[V], Iterable[W]))]
8.6 reduce
reduce函数:对RDD中的所有元素进行聚合操作,将最终的结果返回给Driver。同时元素之间还要符合结合律和交换律[原因:在进行reduce的操作时,并不知道那个数据先过来,所有要符合交换律,在交换律的基础上,满足结合律才能进行reduce]

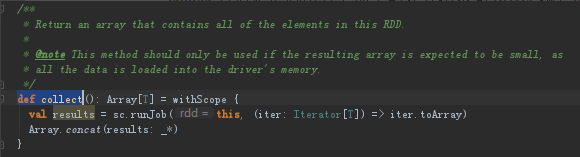
8.7 collect
collect方法是汇总所有节点中的计算结果到Driver端,collect后得到的是数组,Array中就是一个元素,只不过这个元素是一个Tuple,Array即为元组数组。返回的是一个数组,包含了所有程序运行结果的数组,其中使用concat(results: _*)方法将各个节点的数据加入到数组中。
8.8 saveAsTextFile
该函数将数据输出,以文本文件的形式写入本地文件系统或者HDFS等。Spark将对每个元素调用toString方法,将数据元素转换为文本文件中的一行记录。若将文件保存到本地文件系统,那么只会保存在executor所在机器的本地目录

