目录
MapReduce VS RDD:
传统的MapReduce虽然具有自动容错、平衡负载和可拓展性强的优点,但最大的缺点是采用非循环式的数据流模型,使得在迭代计算时要进行大量的磁盘I/O操作。
RDD是Spark提供的最重要的抽象概念,可以将RDD理解成一个分布式存储在集群中的大型数据集合,不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提供了数据处理的速度和性能。
RDD简介
一、RDD的定义
RDD(Resilient Distributted Dataset,弹性分布式数据集),是一个容错的、并行的数据结构,可以让用户显式的将数据存储到磁盘和内存中,并且含能够控制数据的分区。对于迭代式计算和交互式数据挖掘,RDD可以将中间计算的数据结果保存在内存中,需要计算时,则可以直接从内存中读取,从而极大地提高计算速度。
二、RDD的5大特征
1.分区列表:每个RDD被分为多个分区,这些分区运行在集群中的不同节点,每个分区都会被一个计算任务处理,分区数决定了并行计算的数量,创建RDD时可以指定RDD分区的个数。
2.每个分区都有一个计算函数:Spark的RDD计算函数是以分片为基本单位的,每个RDD都会实现compute函数,对具体的分片进行计算。
3.依赖于其他RDD:RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过对这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4.(Key,Value)数据类型的RDD分区器:当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于(Key,Value)的RDD,才会有Partitioner(分区),非(Key,Value)的RDD的Partitioner(分区)的值为None。
5.每个分区都有一个优先位置列表:优先位置列表会存储每个Partitioner的优先位置,对于一个HDFS文件来说,就是每个Partitioner块的位置。按照”移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到要处理数据块的存储位置。
RDD的创建方式
Spark提供2种创建RDD的方式,分别是从文件系统(本地和HDFS)中加载数据创建RDD和通过并行集合创建RDD。
一、 从文件系统加载数据创建RDD
Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。
通过Spark中的SparkContext对象调用textFile()方法加载数据从创建RDD。
①从Linux本地文件系统加载数据创建RDD
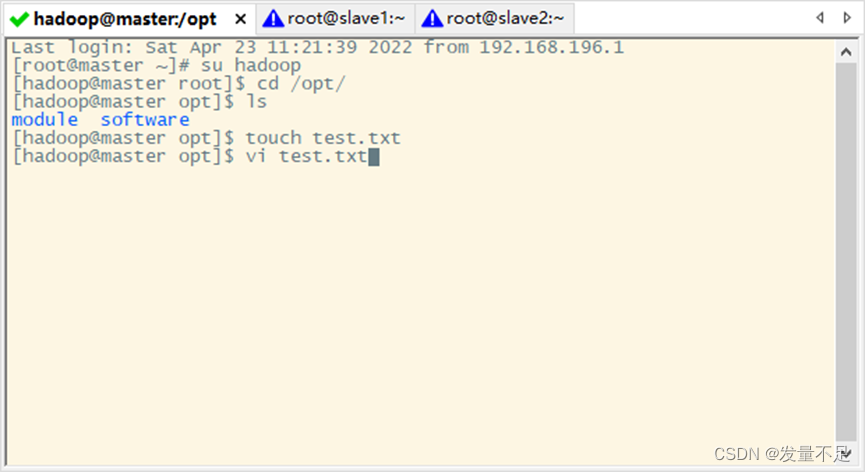
- 在Liunx本地系统创建一个test.txt文件
创建test.txt文件:touch test.txt
并对test.txt写入数据:vi test.txt
- 对test.txt写入如下内容
1 hadoop spark
2 itcast heima
3 scala spark
4 spark itcast
5 itcast hadoop注:中间用空格分隔!!!
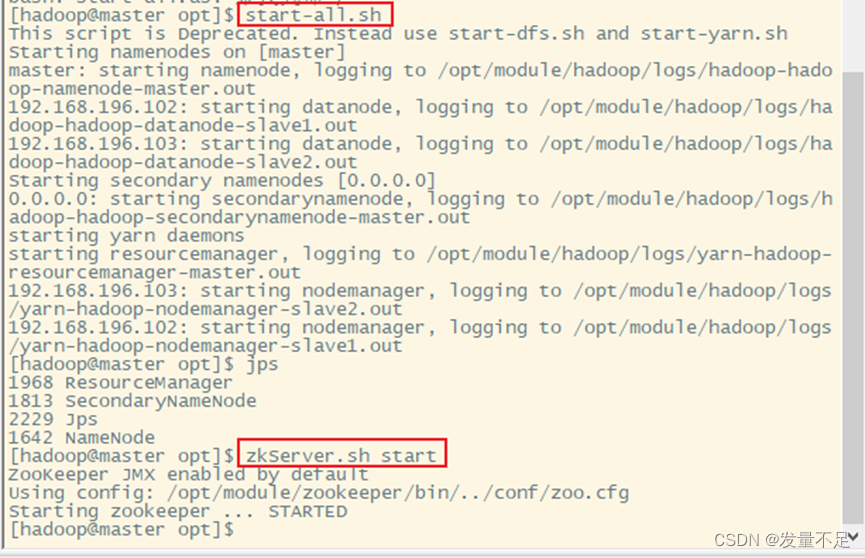
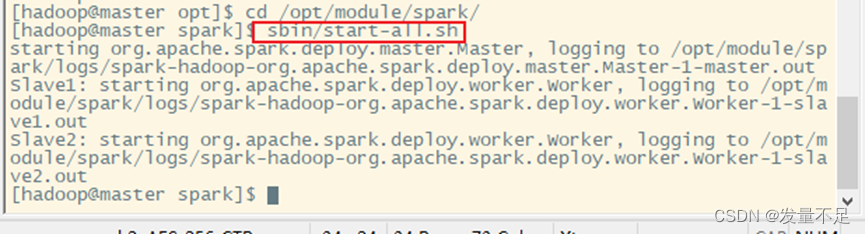
- 启动spark集群服务
启动所有服务:start-all.sh
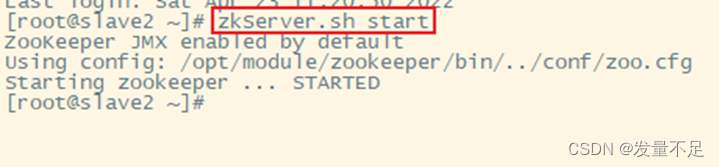
启动zookeeper服务,slave1和slave2也需要启动
zkServer.sh start

启动Spark集群服务(进入到spark目录下启动)
cd /opt/module/spark/
sbin/start-all.sh
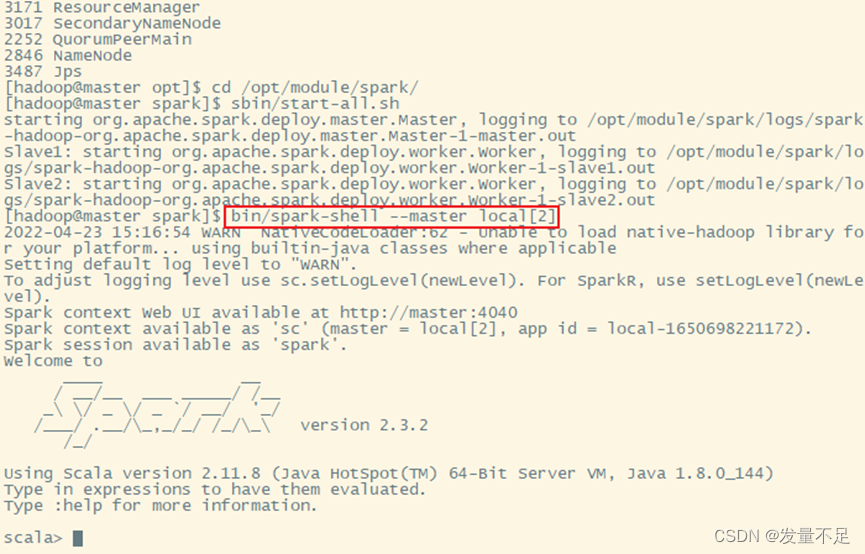
- 启动Spark-Shell交互页面
bin/spark-shell --master local[2] #local[2]:在本地开启2个工作线程
- 在linux本地系统读取test.txt文件数据创建RDD
val test = sc.textFile(“file:///opt/test.txt”)
注:此处的路径为test.txt创建的路径

二、从HDFS中加载数据创建RDD
新建一个master窗口如下

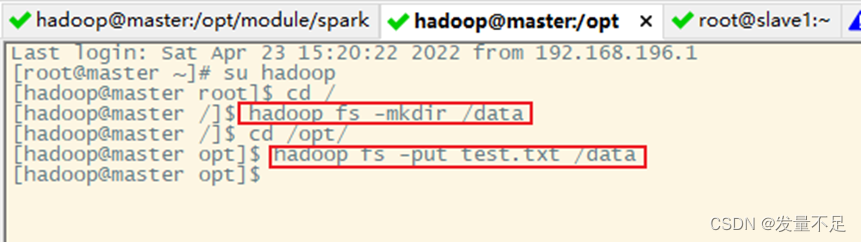
在HDFS上创建/data目录,并将test.txt文件上传至/data目录下
切换到hadoop用户:su hadoop
创建/data目录:hadoop fs -mkdir /data
切换到test.txt目录/opt下进行上传:hadoop fs -put test.txt /data
回到Spark-Shell交互界面下:bin/spark-shell --master local[2]
加载HDFS中的数据创建RDD:val testRDD = sc.textFile(‘/data/test.txt’)
注:testFile()中的参数,路径没有指定file时,则默认为HDFS路径

三、通过并行集合创建RDD
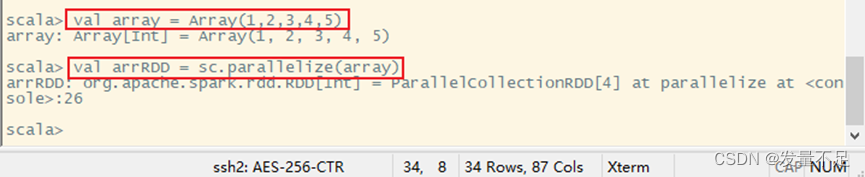
要创建RDD,需要先创建一个数组:val array = Array(1,2,3,4,5)
执行parallelize()方法实现:val arrRDD = sc.parallelize(array)