1. 三大弹性数据集介绍
1)概念

2)优缺点对比


2. Spark RDD概述与创建方式
1)概述
在集群背后,有一个非常重要的分布式数据架构,即弹性分布式数据集(resilientdistributed dataset,RDD),它是逻辑集中的实体,在集群中的多台机器上进行了数据分区。RDD是Spark的核心数据结构,通过RDD的依赖关系形成Spark的调度顺序。 通过对RDD的操作形成整个Spark程序。
2)创建方式
a)创建方式一
scala> val data = Array(1, 2, 3, 4, 5) scala> val distData = sc.parallelize(data)
b)创建方式二
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at < console >:26
3. spark RDD 五大特性

4. spark RDD操作方式
1)RDD是一个懒执行,直到Action阶段才会真正执行。
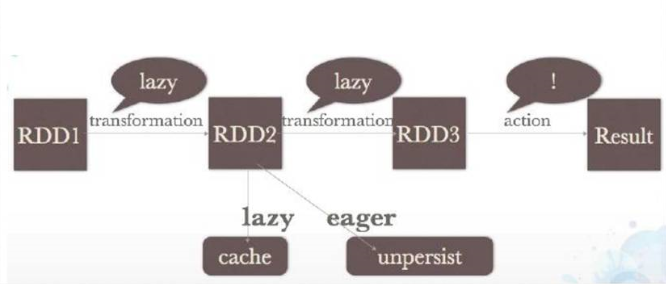
2)RDD三大操作
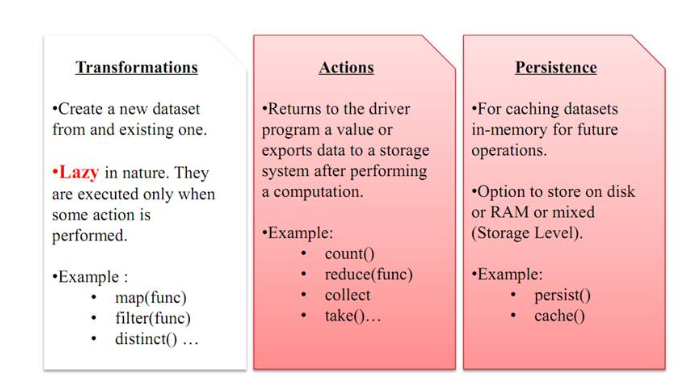
a)Transfamation 函数

b)Action函数

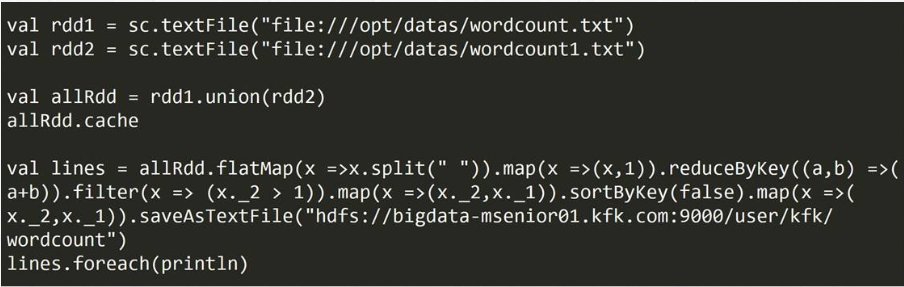
c)具体使用
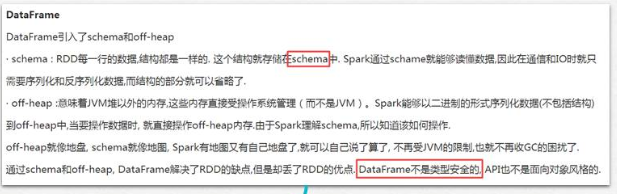
5. DataFrame创建方式与功能
1)什么是DataFrame

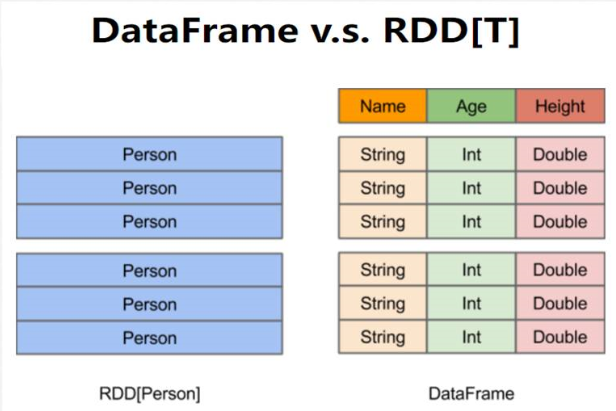
2)DataFrame与RDD对比
3)DataFrame与DataSet对比

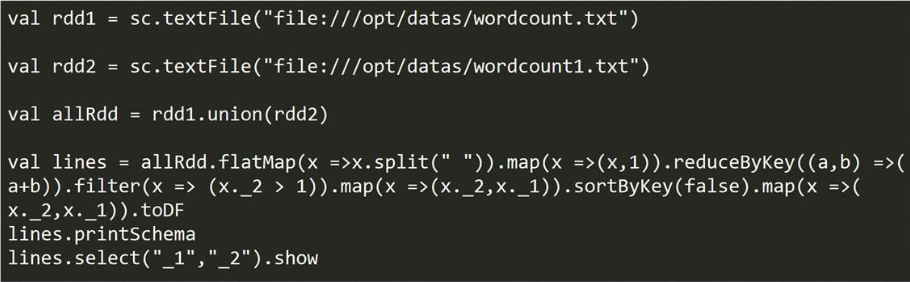
4)创建方式一:RDD转换DataFrame
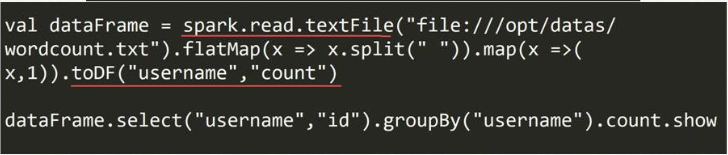
5)创建方式一:DataSet转换DataFrame
6. DataSet创建方式及功能
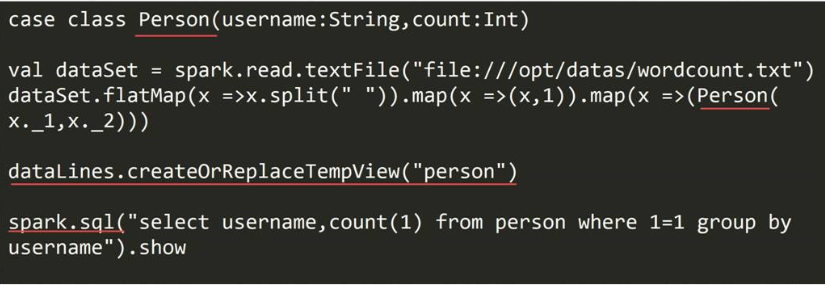
DataSet创建方式
7. Spark2.X源码分析
下载Spark2.2-src源码包,解压之后导出idea工具即可。
8. 数据集之间的对比和转换
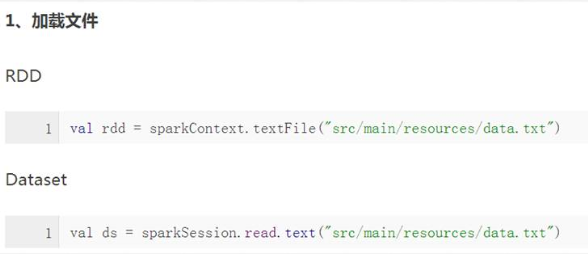
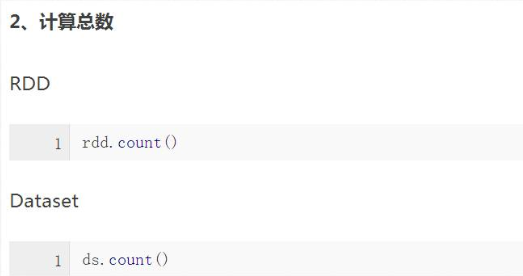
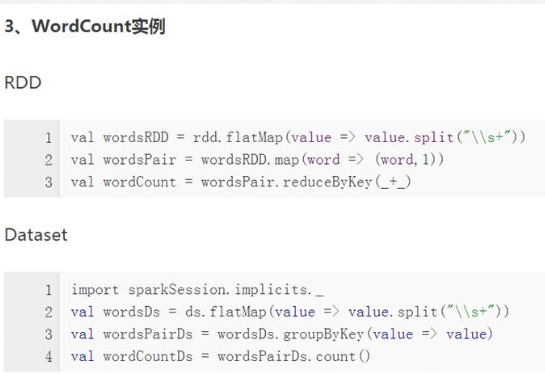
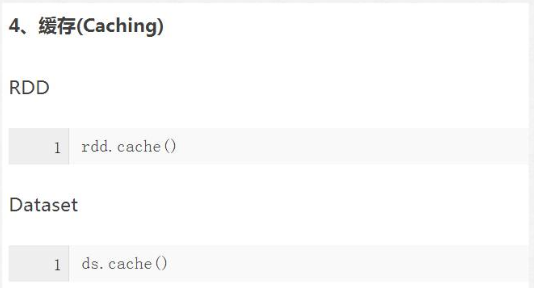
1)RDD与DataSet数据操作方式
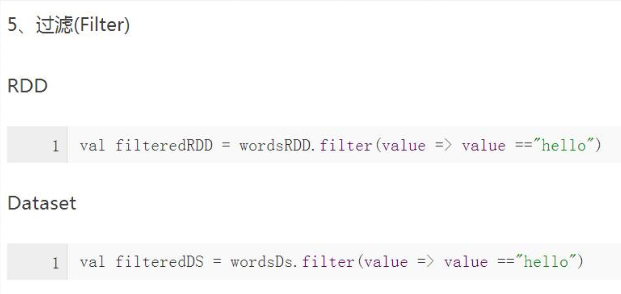
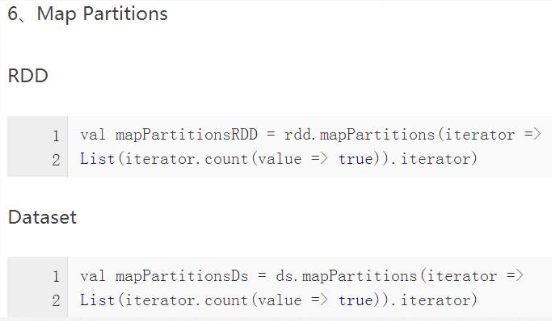
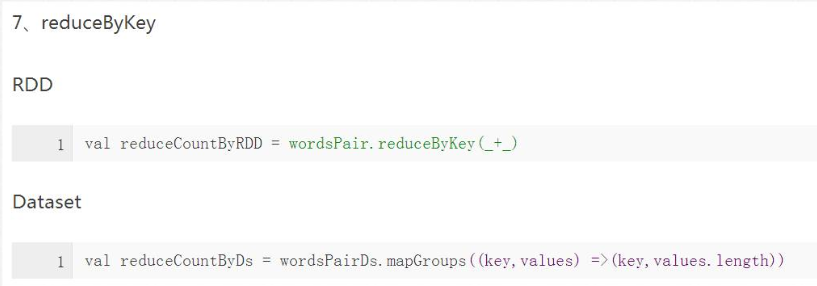

2)转换操作
DataFrame/DataSet转RDD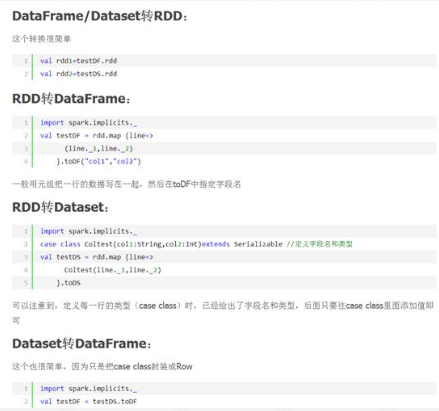
分组排序
