GoogLeNet-v1:Going deeper with convolutions Christian
简述:
GoogLeNet-v1获得了ILSVRC14的冠军,该体系结构的特点是对网络内部计算资源的改进利用,允许增加网络的深度和宽度,同时保持计算预算不变,深度22层,参数却比AlexNet、VGGNet少得多,建立了一种叫作‘Inception’的神经网络架构,且分类性能优于当时的技术水平。
问题or相关工作:
对于较大的数据集,如ImageNet,提升网络性能的最直接的办法就是增加网络的宽度和深度,但存在下面两个缺点:
- 较大的尺寸通常意味着更多的参数,这使得扩大后的网络更容易发生过拟合,特别是在训练集数量有限的情况下(创建高质量的训练集很棘手且代价大。)
- 网络规模的增长使得竞争资源的使用显著增加,例如如果两个卷积是链式的,它们的滤波器数量的任何均匀增加都会导致计算量的二次增长。
解决这两个问题的基本方法是从完全连接的架构 转移到 稀疏连接的架构,甚至在卷积内部也是如此。本文借鉴NIN网络使用全局平均池化层(卷积后在连接1×1的卷积和ReLU激活函数)来取代全连接层(准确率提高0.6%),且搭建了稀疏性、高计算性能的网络结构。
模型:
Inception架构的主要思想是找出卷积视觉网络中最优的局部稀疏结构是如何被现成的密集组件逼近和覆盖的。

原始的Inception基本结构由1×1(提取细节信息)、3×3、5×5(覆盖大部分的输入)和3×3的池化操作堆加在一起(降低过拟合),它们的输出过滤器库连接成一个输出向量。然而原始的结构,尽管可能覆盖最优的稀疏结构,但它的效率非常低,因为即使数量不多的5×5卷积,在具有大量过滤器的卷积层上,计算量太大。为避免这种情况,GoogLeNet团队提出了v1的结构,如下图:
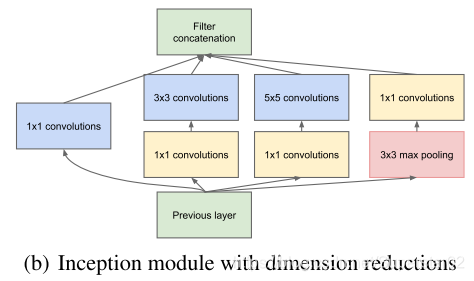
该结构在高代价的3×3、5×5卷积之前,用1×1个卷积来计算约简,并使用了非线性,即大多数地方保持稀疏的表示,在最后通过一个聚合操作合并(在输出通道数这个维度上聚合)。
Inception网络是由上述类型的模块组成的网络,这些模块相互堆叠,偶尔使用带有步长为2的最大池层来将网格的分辨率减半。这种体系结构的一个主要好处是,它允许在每个阶段显著增加单元的数量,而不会在计算复杂度上失控地膨胀。
GoogLeNet的网络结构细节图如下:
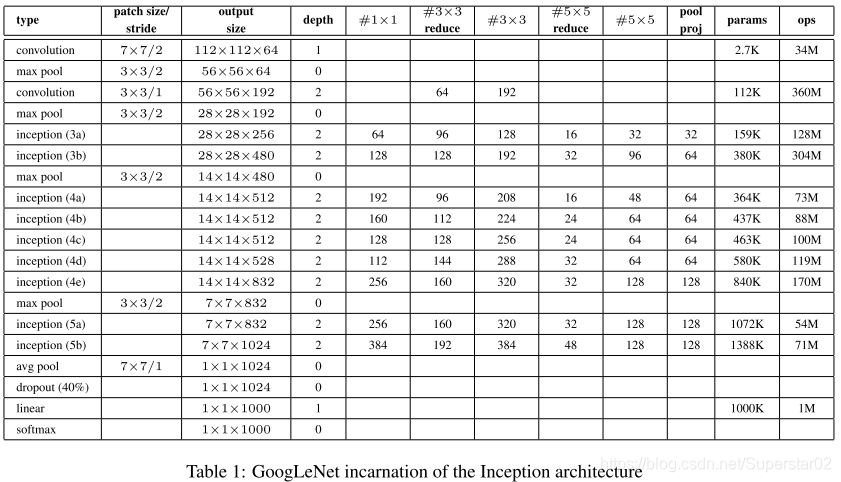
注:#3×3reduce和#5×5reduce代表在进行3×3和5×5个卷积之前使用的约
简层中的1×1个过滤器的数量。
GoogLeNet的网络架构如下:
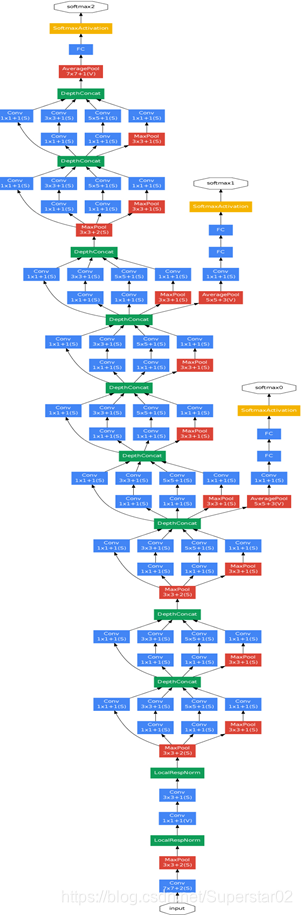
其中:
- 虽然移除了全连接,但网络中依然使用了Dropout.
- 考虑到网络的深度相对较大,以有效的方式将梯度传播回所有层的能力是一个问题,即梯度消失。作者发现网络中间各层所产生的特性具有很强的辨别力,通过添加中间层的辅助分类器,增强返回的梯度信号,并提供额外的正则化,这些分类器以较小的卷积网络的形式放在Inception (4a)和(4d)模块的输出之上,并按较小的0.3的权重加到最终分类的结果中。
- 以Inception 3a层为例分析(参考上表):
分为四个分支,
(1)64个1x1的卷积核,然后RuLU,输出28x28x64
(2)96个1x1的卷积核,作为3x3卷积核之前的降维,变成28x28x96,然后进行ReLU计算,再进行128个3x3的卷积(padding为1),输出28x28x128
(3)16个1x1的卷积核,作为5x5卷积核之前的降维,变成28x28x16,进行ReLU计算后,再进行32个5x5的卷积(padding为2),输出28x28x32
(4)pool层,使用3x3的核(padding为1),输出28x28x192,然后进行32个1x1的卷积,输出28x28x32。
将四个结果进行连接,对这四部分输出结果的第三维并联,即64+128+32+32=256,最终输出28x28x256
实验结果:
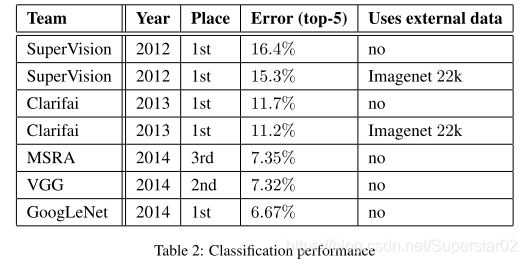
从图像分类比赛top-5的实验结果来看,效果很明显,差错率比MSRA、VGG等模型都要低,并且没有使用额外的数据,说明Inception-v1取得了很好的性能。
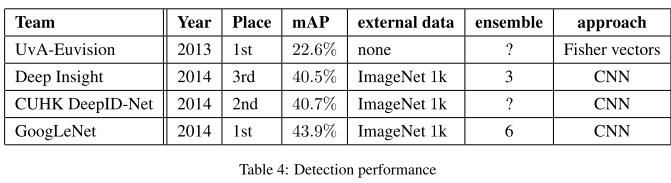
在目标检测比赛中,使用6个卷积神经网络对每个区域进行分类,准确率从40%提高到43.9%。平均精度在参赛的模型中最高。
总结:
对于改进计算机视觉神经网络,利用现有的密集构造块来逼近期望的最有稀疏结构,是一种可行的方法。优点:与较浅、较宽的网络相比,计算量适度增加的情况下,有显著的质量增益。
补:Hebbian原理
刚开始看GoogLeNet时,不太明白为什么还能分开成稀疏结构分别卷积再聚合一起,经查阅相关资料知,该稀疏结构基于Hebbian原理。解释如下:
神经反射活动的持续与重复会导致神经元连接稳定性的持久提升,当两个神经元细胞A和B距离很近,并且A参与了对B重复、持续的兴奋,那么某些代谢变化会导致A将作为能使B兴奋的细胞。总结一下即“一起发射的神经元会连在一起”(Cells that fire together, wire together),学习过程中的刺激会使神经元间的突触强度增加。
受Hebbian原理启发,另一篇文章Provable Bounds for Learning Some Deep Representations提出,如果数据集的概率分布可以被一个很大很稀疏的神经网络所表达,那么构筑这个网络的最佳方法是逐层构筑网络:将上一层高度相关(correlated)的节点聚类,并将聚类出来的每一个小簇(cluster)连接到一起,如图11所示。这个相关性高的节点应该被连接在一起的结论,即是从神经网络的角度对Hebbian原理有效性的证明。
将高度相关的节点连接在一起,形成稀疏网络 如下图:
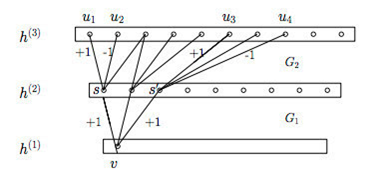
因此一个“好”的稀疏结构,应该是符合Hebbian原理的,我们应该把相关性高的一簇神经元节点连接在一起。在普通的数据集中,这可能需要对神经元节点聚类,但是在图片数据中,天然的就是临近区域的数据相关性高,因此相邻的像素点被卷积操作连接在一起。而我们可能有多个卷积核,在同一空间位置但在不同通道的卷积核的输出结果相关性极高。因此,一个1×1的卷积就可以很自然地把这些相关性很高的、在同一个空间位置但是不同通道的特征连接在一起,这就是为什么1×1卷积这么频繁地被应用到Inception Net中的原因。1×1卷积所连接的节点的相关性是最高的,而稍微大一点尺寸的卷积,比如3×3、5×5的卷积所连接的节点相关性也很高,因此也可以适当地使用一些大尺寸的卷积,增加多样性(diversity)。最后Inception Module通过4个分支中不同尺寸的1×1、3×3、5×5等小型卷积将相关性很高的节点连接在一起,就完成了其设计初衷,构建出了很高效的符合Hebbian原理的稀疏结构。