阅读中科大雷鸣2012年博士毕业论文后整理个人读书笔记
1. 绪论
传统语音合成的方法
- 基于HMM的统计参数语音合成(也是本文要讲的重点,参数统计的办法)
- 基于大量语料的单元挑选与波形拼接

一般的语音合成系统可以分成(1)前端文本–文本转成层次化的语音学表示;(2)后端语音合成–从层次化的语音学表示合成语音,其中韵律特征预测可以和语音合成作为一个整体,也可以单独拉出来作为一个模块。
人类发生系统可以发出三类语音:
(1)浊音:(比如元音)肺部气压升高,强迫空气通过声门,使声带振动产生的类周期性宽频脉冲
(2)摩擦音:(比如辅音,/s/, /sh/, /f/)空气以足够的速度通过部分关闭的声门
(3)爆破音:(比如/p/, /t/,/k/)空气在完全闭合的声道累积增压,然后突然打开声道产生的。
1.3 语音合成方法的分类
1.3.1 基于规则的参数化语音合成
—每一个音段的合成参数需要根据上下文情况结合规则进行一定的设定,合成器根据设定好的语音参数进行合成
- 物理机理语音合成
例如VODER(语音合成器),由宽带噪声源和周期振荡器组成两个声源,还有多个带通滤波器模拟声道。还有一种是对声带和发声器官在发音过程中的变化进行3D建模。
但是这类方法模拟的对象非常复杂,很难精确度量变化。 - source-filter合成

其中基于source-filter合成的有两种方法,两者原理类似,但是声道模型不同
(1)线性预测分析合成

其中, 是线性预测系数,用最小均方误差,Levinson-Durbin等算法估计线性预测系数。
(2)共振峰合成器—它的设计考虑了人的发声机理,声道模型堪称一个谐振腔,声道特性由谐振腔的谐振频率,也就是共振峰表示。共振峰合成可以根据发生机理模拟各种声学特征,但它的结构比较复杂,实际实现的效果并不好。
1.3.2 基于波形拼接的语音合成
方法: 根据输入文本分析后的信息,从指定的音库中挑选合适的信息,进行必要的调整之后,合成最终的语音。由于最终的语音的基本单元都是从音库中直接挑选出来的,因此保持了原始发音人的音质。
评价:该方法会受到音库大小和单元挑选算法的影响,但是随着计算机运算和存储能力的提升,上述的限制已经不大。但是需要大的语料库,成本昂贵。
1.3.3 基于统计建模的参数化语音合成
方法:对输入的语音进行参数化表征,然后进行声学参数建模,并以训练得到的模型为基础构建合成系统。是自动构架的合成系统。
2. 基于HMM的统计参数语音合成
2.1 HMM简介
- 一阶马尔可夫链:序列中任意时刻的变量仅和它前一时刻变量的分布有关,与更前的时刻无关。
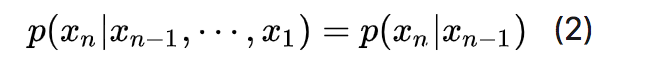
因此,根据贝叶斯定理,随机变量的联合分布可以写成条件分布的连乘积:
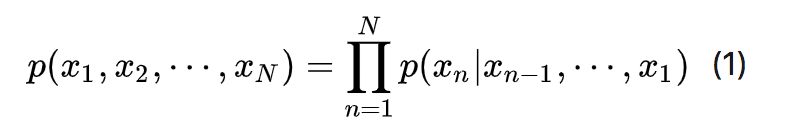
在一阶马尔可夫的假设下,随机变量的分布可以简化为
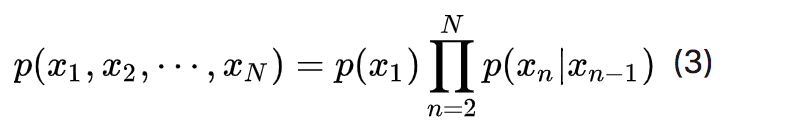
- M阶马尔可夫链:序列中任意时刻的变量仅和它前M个时刻变量的分布有关,与更前的时刻无关。

