经历了两周的bug,终于把全连接神经网络搭好,并把数据成功的喂入到神经网络中。下面我我对我的网络进行简单的介绍:
首先通过tensorboard‘画图’,网络的结构如下图所示:

这是一侧五层的全连接神经网路:神经元等超参数的设定在之后的脚本中有详细的解释,具体见后面的代码。
之后训练200轮之后绘制出测试集和训练集的曲线以及loss曲线如下图所示:

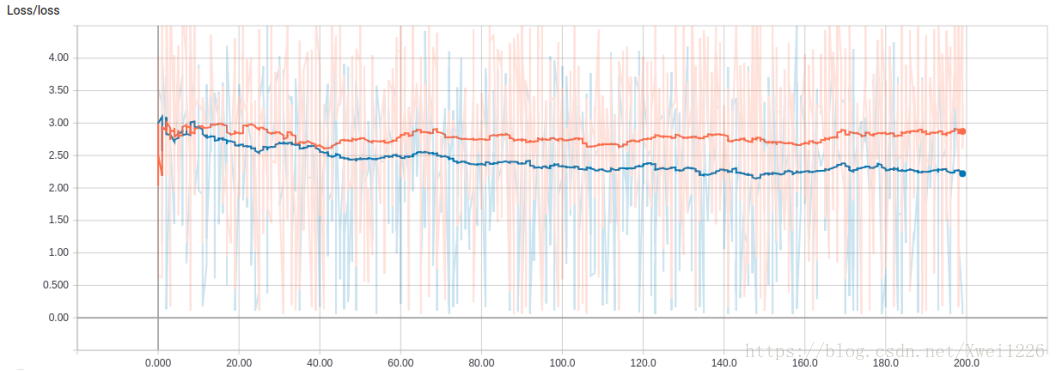
通过上面的分析,我们发现,当网络堆叠到5层的时候,处理80w的声学特征的准确率也只有在40%左右,无法达到更高的效果,这个和网络的本身的结构有关,之后准备尝试使用RNN,CNN等不同结构的网络进行试验,下面附上代码:
#-*- coding:utf-8 -*- #author : zhangwei import numpy as np import tensorflow as tf filename_01 = '/home/zhangwei/data/train_mfcc_800000.txt' filename_02 = '/home/zhangwei/data/train_label_800000.txt' filename_03 = '/home/zhangwei/data/test_mfcc.txt' filename_04 = '/home/zhangwei/data/test_label.txt' X_train = np.loadtxt(filename_01) Y_train = np.loadtxt(filename_02) X_test = np.loadtxt(filename_03) Y_test = np.loadtxt(filename_04) batch_size = 100 n_epoch = 200 def bn(in_size,out_size): fc_mean , fc_var = tf.nn.moments(in_size , axes=[0]) scale = tf.Variable(tf.ones([out_size])) shift = tf.Variable(tf.zeros([out_size])) epsilon = 0.001 Wx_plus_b = tf.nn.batch_normalization(in_size , fc_mean , fc_var , shift , scale , epsilon) return Wx_plus_b with tf.Graph().as_default(): with tf.name_scope('Input'): x = tf.placeholder(tf.float32 , [batch_size , 39]) y = tf.placeholder(tf.int64 , [batch_size , 219]) keep_prob = tf.placeholder(tf.float32) with tf.name_scope('Layer_1'): W1 = tf.Variable(tf.truncated_normal([39,100] , stddev=0.1)) tf.summary.histogram('layer1_W' , W1) b1 = tf.Variable(tf.zeros([100]) + 0.1) tf.summary.histogram('layer1_b' , b1) l1 = tf.add(tf.matmul(x , W1) ,b1) l1_bn = bn(l1 , 100) h1 = tf.nn.relu(l1_bn) h1_prob = tf.nn.dropout(h1 , keep_prob) with tf.name_scope('Layer_2'): W2 = tf.Variable(tf.truncated_normal([100 , 256] , stddev=0.1)) tf.summary.histogram('layer2_W', W2) b2 = tf.Variable(tf.zeros([256])+0.1) tf.summary.histogram('layer2_b', b2) l2 = tf.matmul(h1_prob , W2) + b2 l2_bn = bn(l2 , 256) h2 = tf.nn.relu(l2_bn) h2_drop = tf.nn.dropout(h2 , keep_prob) with tf.name_scope('Layer_3'): W3 = tf.Variable(tf.truncated_normal([256 , 512] , stddev=0.1)) tf.summary.histogram('layers_w' , W3) b3 = tf.Variable(tf.zeros([512])+0.1) tf.summary.histogram('layer3_b' , b3) l3 = tf.matmul(h2 , W3) + b3 l3_bn = bn(l3 , 512) h3 = tf.nn.relu(l3_bn) h3_drop = tf.nn.dropout(h3 , keep_prob) with tf.name_scope('Layer_4'): W4 = tf.Variable(tf.truncated_normal([512 , 219] , stddev=0.1)) tf.summary.histogram('layer4_w' , W4) b4 = tf.Variable(tf.zeros([219])+0.1) tf.summary.histogram('layer4_b' , b4) l4= tf.matmul(h3_drop , W4) + b4 prediction = tf.nn.relu(l4) with tf.name_scope('Loss'): loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction , labels=y)) tf.summary.scalar('loss' , loss_op) with tf.name_scope('Train'): train_op = tf.train.AdamOptimizer(0.001).minimize(loss_op) with tf.name_scope('Accuracy'): correct_prediction = tf.equal(tf.argmax(prediction , 1) , tf.argmax(y , 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction , tf.float32)) tf.summary.scalar('Accuracy' , accuracy) merged = tf.summary.merge_all() init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) train_writer = tf.summary.FileWriter('/home/zhangwei/tensorboard/train' , sess.graph) test_writer = tf.summary.FileWriter('/home/zhangwei/tensorboard/test' , sess.graph) test_acc = sess.run(accuracy , feed_dict=feed_dict) summary = sess.run(merged , feed_dict=feed_dict) test_writer.add_summary(summary , j) # result = sess.run(prediction , feed_dict=feed_dict) # print 'Iter : ' + str(j) + '; result' + str(result) print 'Iter : ' + str(j) + ' ; Loss : ' + str(loss) + ' ; training_Accuracy : ' + str(train_acc) +\ ' ; testing accuracy : ' + str(test_acc)