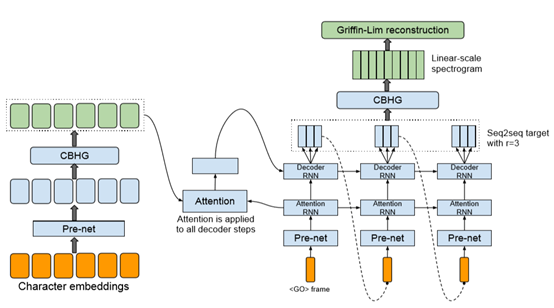
Tacotron模型架构图
(1) 下载tacotron模型的实现到本地,这里是基于GitHub上一个tacotron模型的实现开展研究的,GitHub网址:https://github.com/keithito/tacotron,由于
谷歌没有给出tacotron模型的官方实现,这里给出了tacotron模型的非官方实现;
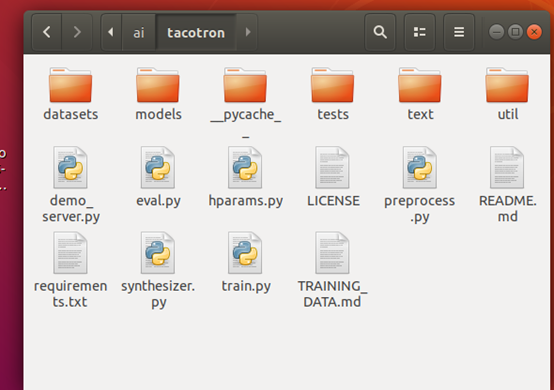
1) 研究是在linux下开展的,由于源码较多,只展示tacotron模型源码的基本结构如下:
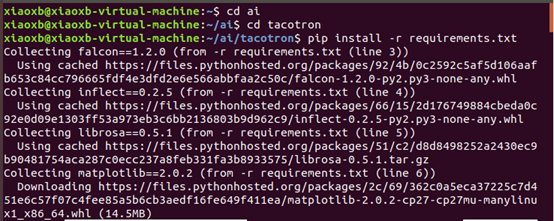
2) 安装一些依赖项:
① 安装Python 3。
② 安装最新版本的TensorFlow。
③ 安装此模型的一些要求:pip install -r requirements.txt
requirements.txt 文件:

安装过程:
(2) 基于预先训练好的模型来进行语音和成:
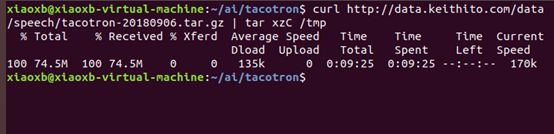
1) 下载并解压缩模型:
curl http://data.keithito.com/data/speech/tacotron-20180906.tar.gz | tar xzC /tmp
2) 运行服务器,基于端口(9000)
python3 demo_server.py --checkpoint /tmp/tacotron-20180906/model.ckpt
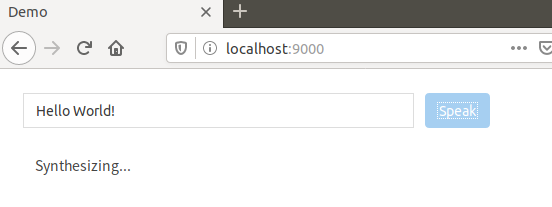
3) 将浏览器指向localhost:9000,即可输入要合成的内容,并输出合成的音频
合成中:
合成完毕:

(3) 使用其他数据,训练,合成语音
1) 下载语音数据集,我们尝试下载了一些数据集,如LJ Speech(LJ语音数据集);
2) 将数据集解压缩到 ai/tacotron(ai是我电脑下的一个目录)
解压缩后,对于LJ语音,对应的树如下所示:
tacotron
|- LJSpeech-1.1
|- metadata.csv
|- wavs
3) 预处理数据:
python3 preprocess.py --dataset ljspeech
4) 训练模型
python3 train.py
5) 从检查点合成
python3 demo_server.py –checkpoint ~/tacotron/logs-tacotron /model .ckpt-185000
可将“185000”替换为要使用的检查点编号,然后打开浏览器localhost:9000并键入您要说的内容,即可合成。
在使用其他数据集来训练和合成的时候,经常由于不知道参数的意义、如何设置,机器太慢,导致花了很长时间都没有效果,这一块没有做出理想的效果。