近段时间一直忙于语音开源克隆模型的尝试,现总结如下:
MockingBird:特点是克隆的声音音色比较像,缺点也很明显,速度慢,5秒左右,可以优化到0.4-1.2秒左右,MOS值偏低;
Vits:特点是目前公开MOS值最接近真实值的,速度比较快,0.08-0.4秒左右;
ms_istft_vits:特点是性能是vits的4倍左右,速度更快,0.06-0.1秒左右,MOS值接近真实值。
这些模型代码或多或少都有些BUG,需要自己去修复,另外vits类的多人训练模型代码需要自己修改,可以使用拼音,也可以使用音素,使用音素加上停顿效果更佳。
vits模型多人训练以AISHELL-3 多人(174人,8万多条语音)中文数据集8K采样率,batch_size=16,需要训练到500K步效果比较好。T4 GPU 16G大概需要训练10天左右。AISHELL单人1万条女声44K采样率,模型大概需要9天左右,240K步效果比较好,可以克隆荷塘月色。
多音字方面:需要维护自己的多音字字典。
加速方面:量化、转onnx或script模型失败,代码不支持,其中转traced_model成功,但性能很低,短句需要10秒,放弃。
论文MOS值对比图:
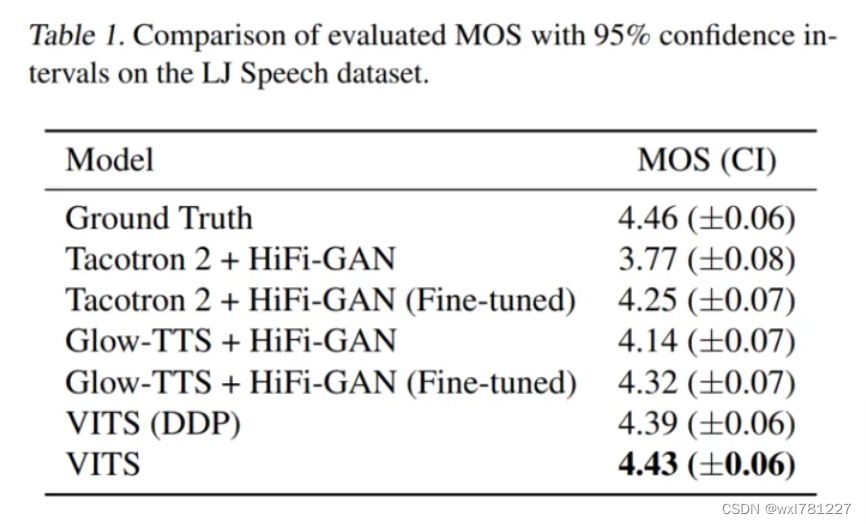

MOS值及单次推理性能(单位:秒)对比:
