- 与机器进行自然的语音交互一直是一个梦想。虽然语音识别已经达到了相当高的准确度,但在语音交互的回路中不只有语音识别,自然的语音合成也是一个非常重要的研究领域。
- 2016年deepmind提出wavenet:
- 可以直接生成原始音频波形
-
结构:一个完全卷积的神经网络,其中的卷积层有不同的膨胀系数(dilation factors),这让其感受野(receptive field)可在深度(depth)上指数式地增长并可覆盖数千个时间步骤(timesteps)。
-
训练时,输入序列是由人类说话者录制的真实波形,训练后可以对这个网络进行采样以生成合成话语。在采样的每一个时间步骤,都会从该网络所计算出的概率分布中取出一个值。然后这个值会被反馈进入输入,并为下一个步骤生成一个新的预测。但一次一步地构建样本就会产生很高的计算成本。
-
使用 WaveNet 将文本转化为语音,需要识别文本中是什么。在DeepMind 这篇论文中,研究人员是通过将文本转换为一序列的语言和语音特征(包含了当前音素、音节、词等方面的信息)做到这一点的。
- 缺点:计算量太大,无法直接用到产品上
- 语音合成有两个主要目标:可理解性(intelligibility)和自然感(naturalness)。
- 可理解性是指合成音频的清晰度,特别是听话人能够在多大程度上提取出原信息。
- 自然感则描述了无法被可理解性直接获取的信息,比如听的整体容易程度、全局的风格一致性、地域或语言层面的微妙差异等等。
- 在语音合成领域的三个成果:
- 百度的deep voice:
- 一个完全由深度神经网络构建的高质量文本转语音系统。
- 已做到了实时的语音合成,相比以前的 WaveNet 推理的实现有 400 倍的加速。
- 该系统更适用于新数据集、语音和没有任何手动数据注释或其他特征调配的领域。
- 为真正的端到端语音合成奠定了基础,这种端到端系统没有复杂的处理流程,也不依赖于人工调配(hand-engineered)的特征作为输入或进行预训练(pre-training)。
- TTS 包含 5 个模块:
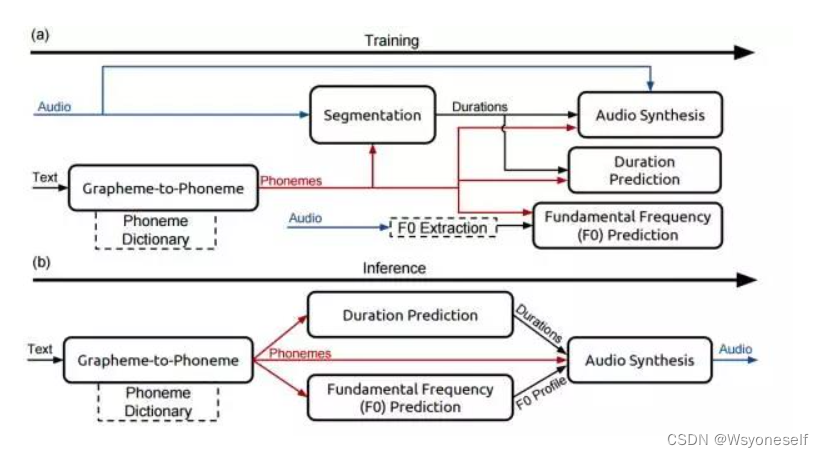
- 一个字素转音素模型;
- 一个在语音数据集中定位音素边界的分隔模型;
- 预测音素序列中每个音素时距(temporal duration)的音素长度模型;
- 一个基本的频率模型预测音素是否浊音的;
- 一个音频合成模型,结合以上 4 个组件的输出来合成音频。
- 端到端语音合成模型 Char2wav
- Char2Wav 由两个组成部分:一个读取器(reader)和一个神经声码器(nerual vocoder):
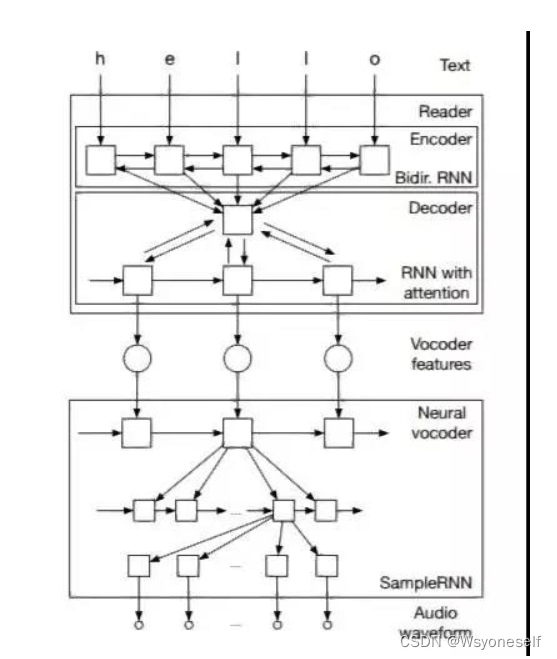
- 读取器是一个带有注意(attention)的编码器-解码器模型。其中编码器是一个以文本或音素作为输入的双向循环神经网络(RNN)
- 解码器则是一个带有注意的循环神经网络,其会产出声码器声学特征(vocoder acoustic features)。神经声码器是指 SampleRNN 的一种条件式的扩展,其可以根据中间表征(intermediate representations)生成原始的声波样本。
- Char2Wav 可以学习直接根据文本生成音频。这和百度的 Deep Voice 系统一致。
- Char2Wav 由两个组成部分:一个读取器(reader)和一个神经声码器(nerual vocoder):
- 谷歌端到端的文本转语音合成模型 Tacotron:
- 该模型可接收字符的输入,输出相应的原始频谱图,然后将其提供给 Griffin-Lim 重建算法直接生成语音:

- 由于 Tacotron 是在帧(frame)层面上生成语音,所以它比样本级自回归(sample-level autoregressive)方式快得多。
- 该模型可接收字符的输入,输出相应的原始频谱图,然后将其提供给 Griffin-Lim 重建算法直接生成语音:
- 百度的deep voice:
语音合成部分模型--学习笔记
猜你喜欢
转载自blog.csdn.net/weixin_45647721/article/details/127294331
今日推荐
周排行