单位:中科院自动化所
作者:fanzhiyun
会议:2019 ASRU
abstract
e2e-ASR存在的问题是train和test的说话人mismatch的问题,做法是:在speech-Transformer的基础上加speaker attention module. SAM有一个i-vector组成的固定的speaker knowledge block,每个时间步,encoder output和i-vectors求相似度,生成一个加权后的speaker embedding,帮助模型归一化说话人的变量。因此使得模型是说话人无关的,可以对没见过的说话人更好的泛化。
introduction
E2E语音识别相较于之前传统方案的优势:(1)更简化的训练过程;(2)各部分联合优化;(3)更紧凑的网络结构。之前已经成功应用的大规模ASR的E2E方法包括:(1)CTC,(2)attention-based encoder-decoder transducer;(3)RNN-transducer。
speaker adaptation是hybrid systems中重要的一部分,主要方法有3种:(1)预训练,然后特定层或者整个模型re-train.(2)speaker dependent transformation被用于将SI model转成SD model.(3)speaker-aware model,用i-vector, speaker code,speaker embedding等方式促进模型对说话人进行归一化。
上述提到的方法是用在hybrid system上,他们在E2E-ASR上的作用还没有被探究,本文用的第3种方法,基于speech-transformer的结构,但是改进的方法也可以用于the popular listen, attend and spell (LAS) model 。
speech-transformer相比于 hybrid TDNN-LSTM system展示出更好的性能,因此作为本文的platform。最简单的方法就是把i-vector拼接到encoder的输入上,但是坐着的实验表明这样性能改进有限,分析认为是self-attention mechanism使得encoder有足够的能力捕捉并且norm长时speaker characteristic。
在speech-transformer的结构上添加speaker attention module,生成soft speaker embedding,使得speech-transformer的主体部分是说话人无关的,因此可以对unseen speaker有更好的泛化能力。文章探究了speaker attention module的几个影响因素:(1)i-vector的数量;(2)speaker attention module在网络中的部位;(3)the level of soft embedding. 结果表明,在aishell-1的数据集上,CER的错误率降低6.5%.
3.background
3.1 self-attention
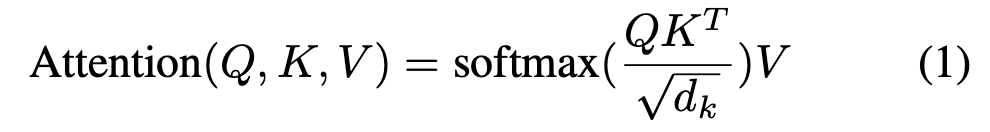
3.2 multi-head attention

3.3 Position-wise Feed-Forward Networks
2层fully-connected,

3.4 speech-transformer
attention-based encoder-decoder
输入 x = (x1 , …xT ),经encoder编码成 z = (z1 , …zT ),然后送给decoder,输出y = (y1 , …yU ),一次输出一个词。

为了防止信息向左流动并在解码器中保留自回归属性,在解码器的自注意子层中将与非法连接相对应的所有值都屏蔽掉了。在encoder和decoder堆栈底部的输入嵌入中添加了additional position encoding,以注入有关序列中相对或绝对位置的某些信息。
4. proposed method
4.1 Speaker Embedding: Soft vs. Hard
hard speaker embedding:作者对直接拼接speaker embedding,然后对模型re-train的说话人向量的称呼。
soft speaker embedding:每一个speaker vector可以用basic speaker representation的线形组合表示。一个说话人的声学特征vector,计算声学特征vector和speaker space的每一个i-vector进行相似度计算得到basic i-vector,最后所有的basic i-vectors的加权和得到soft speaker embedding.
优点:(1)解码过程中,decoder对于unseesn的说话人关于basic vector的合理加权和,但是对于hard embed,unseen speaker的向量对于训练模型是完全陌生的。(2)对于测试模型,不需要计算每一个tester的i-vector,而只需要声学特征,因此相对于hard的前端更为简化。
4.2. Speaker-Aware Speech-Transformer


计算过程
(1)projection

(2)compute similarity
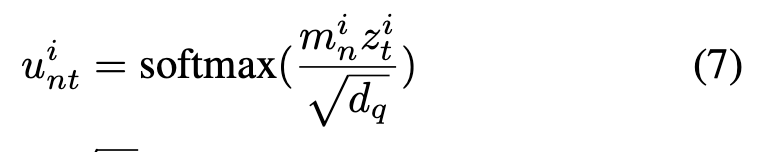
其中,
是防止softmax进入很小的梯度区域。
(3)每个时间步的soft speaker embedding—每个得到的basic i-vectors(相似度概率结果)和projection之后的
求和
is the soft speaker embedding at time step t for the i-th head,是时间依赖的(frame-level)
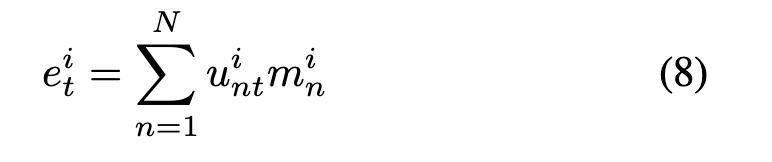
(4)拼接送给decoder

5. experiments
做了5个方面的实验:(1)i-vector的数量探究;(2)SAM在encoder的位置;(3)the level of soft speaker embedding (frame-level or utterance-level);(4)soft 和hard speaker embedding的比较;(5)knowledge block 的i-vector是否必须来自speech-transformer的训练集。
5.1 datasets
speech-transformer 用aishell-1训练
AISHELL-1包含400个说话人,178h
i-vector extractor 用aishell-2 训练
2048 UBM, 200d i-vector, 最后LDA压缩成100d, length normalization
结论:
(1)i-vector的数量探究
控制frame-level speaker embedding,位置不变,从30~340个人随机挑选数量,结果证明100个i-vector性能最好。-----340不好是因为模型训练的时候很容易在SAM中找到对应的,因此学不到对于unseen speaker 线形组合的关系。
(2)SAM在encoder的位置
一共6层encoder,分别在2/4/6的地方计算basic i-vectors,然后同一拼接encoder outputs,结果证明6最好
(3)frame vs utterance level
将frame level 的speaker embedding沿时间求和再平均
frame level的会更好,包含句子中更多的变化
(4)soft vs hard
其中hard 尝试了2种结构----输入拼接, encoder output拼接。
(5)集外i-vector组成的knowledge block
从AISHELL-2从排除AISHELL-1的说话人,然后重复(1)类似的步骤,不同数量的i-vector,测试CER
