
声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Mixture Density Network for Phone-Level Prosody Modelling in Speech Synthesis
该文章是上海交通大学在2021.02.01更新的文章,主要优化声学模型韵律,使语音更加自然,具体的文章链接
https://arxiv.org/pdf/2102.00851.pdf
1 背景
为了使语音合成系统合成更加自然的语音,很多人研究韵律模型。韵律模型主要分为:global prosody 和fine-grained prosody。其中global prosody是把参考的句子转成一个embedding,这也是目前很多系统采用的方案。fine-grained prosody主要是音素级别(PL:phone level)的韵律建模,常使用单高斯来建模。本文提到使用单高斯来建模不能很好表达音素级别之间的信息,因此使用GMM来对PL进行建模。
(对PL建模的文章也有这篇语音合成论文优选:个性化AdaSpeech: Adaptive Text to Speech for Custom Voice,最近我也在搞这些东西)
2 详细设计
本文设计的系统如图1所示,其使用MDN网络来预测GMM分布。图中prosody extractor是从音素对应的mel-spec来抽取prosody embedding,主要在训练阶段使用。在推理阶段则使用prosody prediector来预测GMM,并获取prosody embedding。
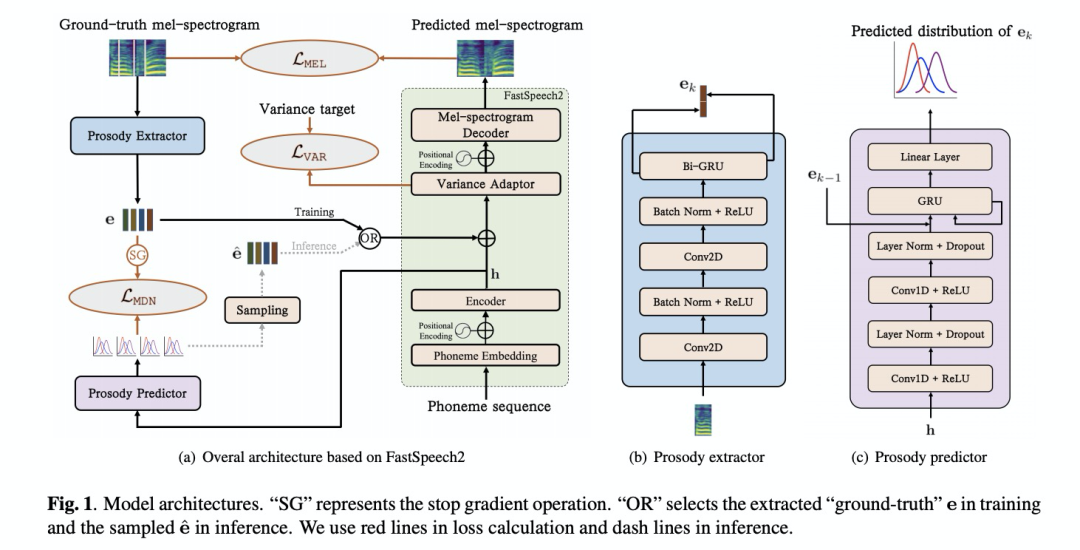
3 实验
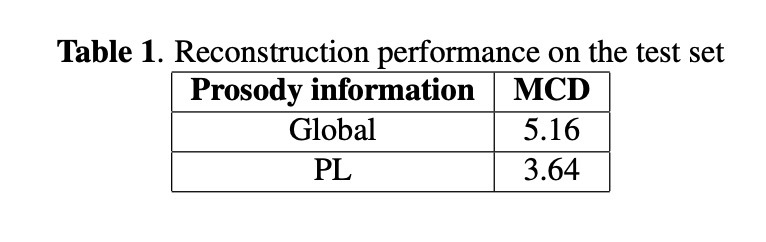
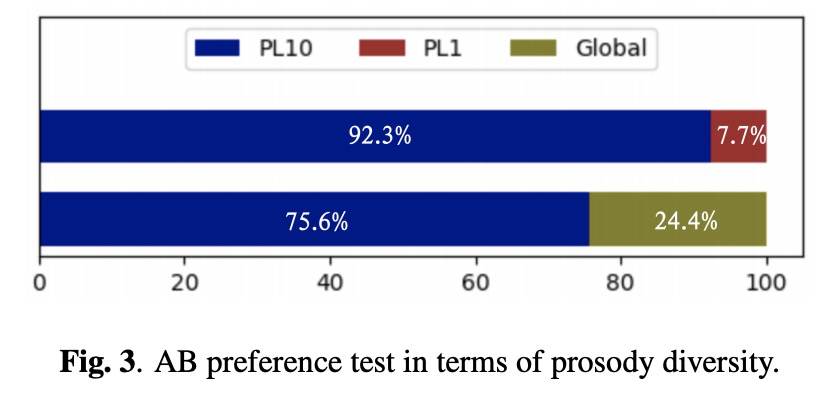
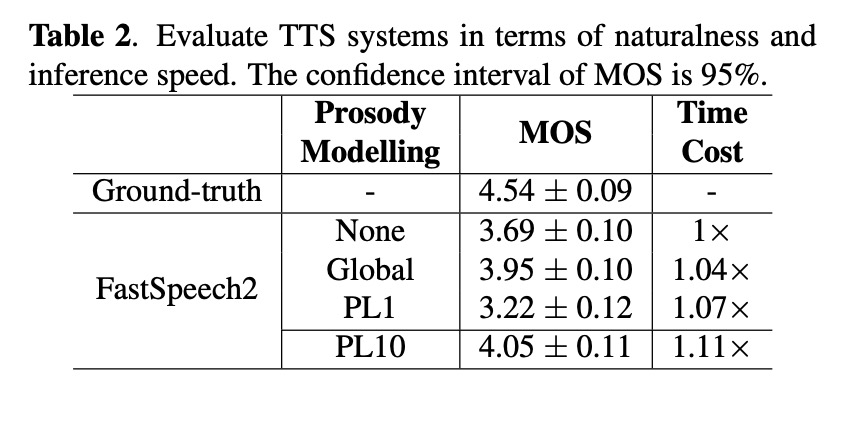
本文先对比使用global和phone级别合成的语音效果,table1展示PL的语音更加接近原始音频。图2展示高斯数量对结果的影响,高斯数量越多越好。图3展示abtest,其中使用PL远远好于global级别。使用越多高斯远远好于单高斯。table2展示了MOS值,本文的MOS值最高,而且对推理速度影响很小。

4 总结
本文使用GMM对phone-level的韵律进行建模,从而很好的增加语音的自然度。