计算机视觉领域中和目标有关的经典任务有三种:分类、检测和分割。其中分类是为了告诉你「是什么」,后面两个任务的目标是为了告诉你「在哪里」,而分割任务将在像素级别上回答这个问题。
视频实现目标检测任务有:Visual tracking,action classification,action (temporal)recognition,video semantic segmentation等。
视频目标分割需要解决的是半监督问题,只给出视频第一帧的正确分割掩码,然后在之后的每一连续 帧中分割标注的目标,而视觉跟踪解决的是值给出视频第一帧的定位边界框,在后续每一连续帧中同样用边界框的形式标注物体。
视频目标分割任务和语义分割有两个基本区别:
1.视频目标分割任务分割的是一般的、非语义的目标;
2.视频目标分割添加了一个时序模块:它的任务是在视频的每一连续帧中寻找感兴趣目标的对应像素。
基于视频任务的特性,我们可以将问题分成两个子类:
无监督(亦称作视频显著性检测):寻找并分割视频中的主要目标。这意味着算法需要自行决定哪个物体才是「主要的」。
半监督:在输入中(只)给出视频第一帧的正确分割掩膜,然后在之后的每一连续帧中分割标注的目标。
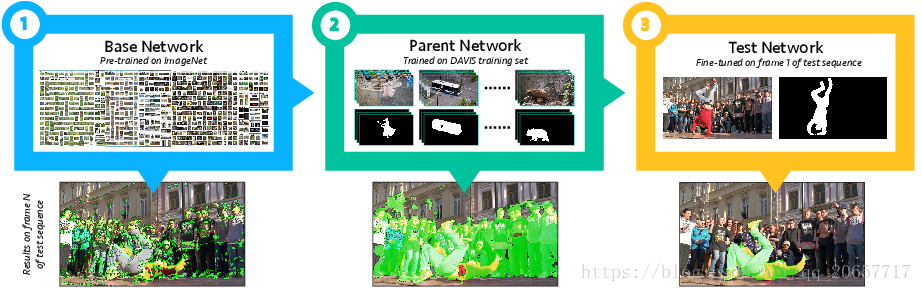
论文有以下贡献:
1.将图像识别任务中的预训练CNN模型迁移到只有一张图片标注(one-shot)的视频分割任务中。然后,将它在人工分割的视频数据集上训练。最后在测试阶段,只在一帧人工标注的图片微调,采用FCN实现特定目标实体分割。
2.论文使用OSVOS独立处理视频的每个帧,同时以副产品的形式取得了不错的时间连续性。考虑到物体在两帧之间变化不大,我们独立处理每一帧图片,与主流方法着重考虑时间连续性不同。这些主流方法在渐变的连续帧之间取得了不错的分割性能,但是对于遮挡和不完整的运动情况效果不太好。运动检测确实是当前视频分割算法中的关键组成,但是相关计算却是一个很大的问题。我们认为时间连续性并不是现在一定要考虑的问题,我们更应该关注如何提高分割的准确性。另一方面,我们的模型也展示了深度学习的方法在独立处理每一帧时也能保证优异的时间连续性。自然的,OSVOS有以下优点:在遮挡时也可以进行分割,不局限与某些运动,不需要处理时序信息也就没有时序错误累积。
3.OSVOS算法在精度和速度上取得平衡,用户可以选择更高准确率或者更高分割速度,实验显示OSVOS每帧181ms的速度可以取得71.5%的准确率,每帧7.83s的速度取得79.7%的准确率。另外,用户可以标注更多的视频帧来提高准确率,实验显示每个视频标注2张可以取得84.6%的准确率,标注4张可以取得86.9%的准确率。
论文使用的数据集是DAVIS 2016。J是区域重合判断标准,F是轮廓重合判断标准,T是时间稳定性。-BS是没有获取边界,-PN是没有在父网络上预训练,-OS是没有学习第一帧。其有两个度量分割准确率的主要标准:
1.区域相似度(Region Similarity):区域相似度是掩码 M 和真值 G 之间的 Intersection over Union。
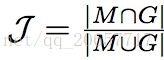
2.轮廓精确度(Contour Accuracy):将掩码看成一系列闭合轮廓的集合,并计算基于轮廓的 F 度量,即准确率和召回率的函数。
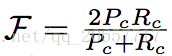
直观上,区域相似度度量标注错误像素的数量,而轮廓精确度度量分割边界的准确率。
OSVOS 训练流程
选择一个网络(比如 VGG-16)在 ImageNet 上进行分类预训练。
将其转换为全连接卷积网络(FCN),从而保存空间信息,训练结束时删去 FC 层。嵌入一个新的损失函数:像素级 sigmoid 平衡交叉熵(pixel-wise sigmoid balanced cross entropy,曾用于 HED)。现在,每一个像素都可以被分类成前景或背景。
在 DAVIS-2016 训练集上训练新的全连接卷积网络。
单次训练:在推断的时候,给定一个新的视频输入进行分割并在第一帧给出真实标注(记住,这是一个半监督问题),创建一个新模型,使用 [3] 中训练的权重进行初始化,并在第一帧进行调整。
这个流程的结果,是适用于每一个新视频的唯一且一次性使用的模型,由于第一帧的标注,对于该新视频而言,模型其实是过拟合的。由于大多数视频中的目标和背景并不会发生巨大改变,因此这个模型的结果还是不错的。自然,如果该模型用于处理随机视频序列时,则它的表现得就没那么好了。
注:OSVOS 方法是独立地分割视频的每一帧的,因此视频中的时序信息是没有用的。
训练:1.osvos_demo.py将“base network”进一步在DAVIS上训练,学习如何将物体从背景中分割出来。然后用随机梯度下降设置momentum 0.9做了50000次迭代。通过反射和放大来处理数据。半监督设置为3,学习率设置为10^-8,逐渐减小。在离线训练后,网络学习如何分割前景和背景。这个网络称为“parent network”。2.parent_demo.py给定第一帧的分割,在视频中分割出该特定物体。通过进一步训练特定物体的image/ground truth对来训练parent network。然后使用新的权重对图像序列测试。时间上主要两个,一个是fine-tuning时间,一个是分割所有帧的时间。之前在质量和时间上有做trade-off,学习图像对的次数越多,得到的结果越好。第二步对gpu要求较高,需自行设置。
参考自:https://www.paperweekly.site/papers/notes/238
https://blog.csdn.net/zdyueguanyun/article/details/78204802
http://it.sohu.com/20171006/n516277259.shtml