模型的评估标准
- 准确率
- estimator.score() 最常见,预测结果的正确百分比
- 混淆矩阵
- 在分类任务下,预测结果与正确标记之间存在四种不同的组合,构成了混淆矩阵(适用于多分类)
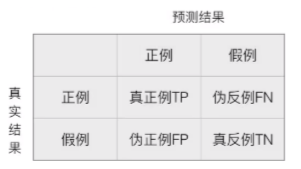
- 在分类任务下,预测结果与正确标记之间存在四种不同的组合,构成了混淆矩阵(适用于多分类)
- 精确率
- 预测结果为正例样本中真实为正例的比例,也就是查得准

- 召回率
- 真实为正例的样本中预测结果为正例的比例,查的全,对正样本的区分能力

- 其他分类标准
- F1-score , 反映了模型的稳健性。具体会在代码运行结果中会显示。
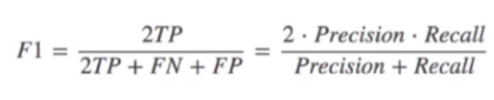
以上都是对模型评估的一个标准。一些基础。
分类模型的评估API
sklearn.metrics.classfication_report(y_true,y_pred,target_names=None) y_true:真实目标值 y_pred:估计器预测目标值 target_names:目标类别名称 return:每个类别精确率与召回率
案例演示:


# 以新闻分类这个案例为例 from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer # 特征抽取 from sklearn.naive_bayes import MultinomialNB # 贝叶斯 # 1.获取数据 news = fetch_20newsgroups(subset='all') # 2. 进行数据分割 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25) # 3.对数据集进特征抽取 tf = TfidfVectorizer() # 以训练集当中的词进行重要性统计 x_train = tf.fit_transform(x_train) # 对测试集也要进行词重要性统计 x_test = tf.transform(x_test) # 4. 进行朴素贝叶斯算法 bys = MultinomialNB(alpha=0.1) bys.fit(x_train, y_train) # 5. 进行预测 predict = bys.predict(x_test) print("预测文章类别为:",predict) print("准确率:", bys.score(x_test, y_test)) # 6. 模型评估 from sklearn.metrics import classification_report classification_report(y_test, predict, target_names=news.target_names)

模型的选择与调优
交叉验证
为了让评估模型更加的精准和可靠
交叉验证过程:
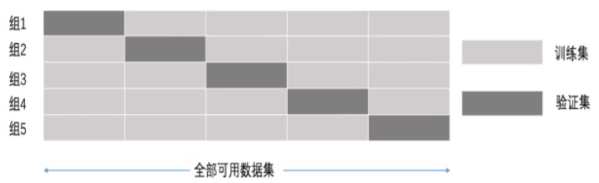
将拿到的训练数据,分为训练和验证集.以下图为例:将数据分成 5份,其中一份作为验证集.然后经过 5次(组)的测试,每次都更换不同的验证集。
即得到5组模型的结果,取平均值作为最终结果.又称 5折交叉验证。
网格搜索
调参数,也叫 超参数!
超参数搜索 -- 网格搜索:
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。
每组超参数都采用交叉验证来进行评估。最后选出 最优参数组合建立模型.

网格搜索 和 交叉验证API
sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None) 对估计器的指定参数进行详尽搜索 estimator:估计器对象 param_grid:估计器参数(dict){"n_neighbors":[1,3,5]} cv:指定几折交叉验证 fit:输入训练集数据 score:准确率 结果分析 best_score:在交叉验证中验证的最好结果 best_estimator_:最好的参数模型 cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
案例代码:
# 代码案例 from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.preprocessing import MinMaxScaler # 读取数据 import pandas as pd import numpy as np data = np.loadtxt('datingTestSet.txt',dtype=np.object,delimiter='\t',encoding='gbk') df = pd.DataFrame(data) #获取特征值 x = df.iloc[:,:3] # 获取目标值 y = df[3] #特征工程 # 归一化 scaler = MinMaxScaler() x = scaler.fit_transform(x) # 分割数据集 x_train , x_test, y_train,y_test=train_test_split(x,y,test_size=0.25) # 实例化估计器 kn= KNeighborsClassifier() # 构造一些参数的值进行搜索 param={'n_neighbors':[15,16,17,18,19,20,21,22,23,24]} # 进行网格交叉搜索 gc = GridSearchCV(kn,param_grid=param,cv=2) gc.fit(x_train,y_train) # 预测准确率 print('测试集上的准确率:',gc.score(x_test,y_test)) print('在交叉验证中最好的结果:',gc.best_score_) print('选择最好的模型是:',gc.best_estimator_) print('每个超参数,每次交叉验证的结果:',gc.cv_results_)
