机器学习的主要挑战在于在未见过的数据输入上表现良好,这个能力称为泛化能力(generalization)。
首先我们要了解俩个词过拟合和欠拟合
过拟合和欠拟合
过拟合:
过拟合是指为了得到一致假设而使假设变得过度严格。就是说训练过度使泛化能力下降。
欠拟合:
模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。也就是说未能学好训练样本的普遍规律。
过拟合是机器学习的关键障碍且不可避免。
学习器泛化评估——实现测试
测试方法主要:
留出法:
我们有数据集D,把D划分为两部分:训练集S和测试集T,其中SUT=D,S∩T=Φ。
划分时一般不宜随机划分,因为如果T中正好只取到某一种特殊类型数据,从而带来了额外的误差。此时处理方法要视具体情况而定,如当数据明显的分为有限类时,可以采用分层抽样方式选择测试数据,保证数据分布比例的平衡。
大多情形下,难以得到合适的测试集,此时一般多次重复划分-训练-测试求误差的步骤,取误差的平均值。
注意事项:
分层采样
重复试验取平均评估结果
优缺点:
测试集小,评估结果方差较大
训练集小,评估结果偏差较大
交叉验证方法:
交叉验证需要将数据集分为训练集和验证集(或者称测试集),在训练集上对模型训练参数,在验证集上看训练出的模型的好坏
又可称为‘p次k折交叉验证’,p次是指进行了p次测试,k折指将数据集分成了k等份。
留一法:
留一法是机器学习中对学习器进行评估的一种方法,属于交叉验证法(cross validation)的一个特例。
如将数据集分为1,2,3,4份,拿2,3,做训练集,先用1做测试集看结果,然后在用4做测试集看结果。

注意事项:
每次使用一个样本验证
优缺点:
不受随机样本划分方式影响
数据量大时计算量大
自助法:
从给定训练集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。
注意事项:
可重复采样/有放回采样
优缺点:
数据集较小有用
改变初始数据集的分布,引入偏差
机器学习中的方差和偏差的区别
偏差:
偏差度量了学习算法的期望预测与真实结果的偏离程序, 即 刻画了学习算法本身的拟合能力 .
方差:
方差度量了同样大小的训练集的变动所导致的学习性能的变化, 即 刻画了数据扰动所造成的影响 .
想象你开着一架黑鹰直升机,攻击地面上一只敌军部队,于是你连打数十梭子,结果有一下几种情况:
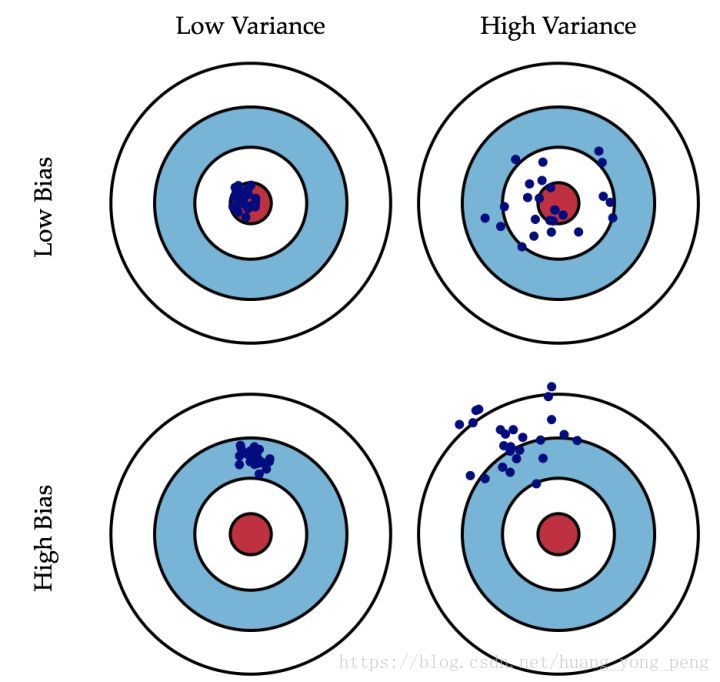
1.子弹一颗没浪费,每一颗都打死一个敌军,跟抗战神剧一样,这就是方差小(子弹全部都集中在一个位置),偏差小(子弹集中的位置正是它应该射向的位置)
2.子弹打死了一部分敌军,但是也打偏了些打到花花草草了,这就是方差大(子弹不集中),偏差小(已经在目标周围了)。
3.子弹基本上都打在队伍经过的一棵树上了,这就是方差小(子弹打得很集中),偏差大(跟目的相距甚远)。
4.子弹打在了树上,石头上,花花草草也都中弹,但是敌军安然无恙,这就是方差大(子弹到处都是),偏差大
性能度量
性能度量:衡量模型泛化能力的评估指标
以二分法为例
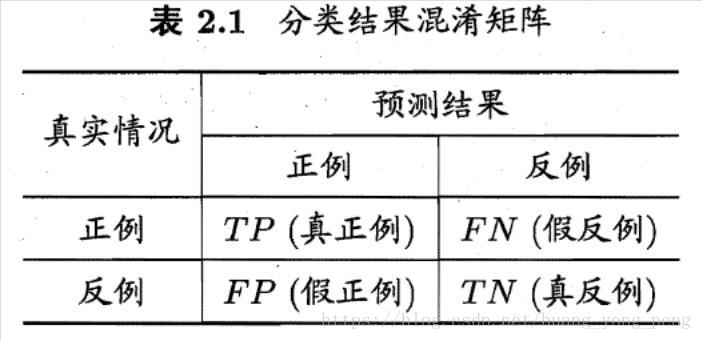
混淆矩阵:
非对角,纠缠相
查准率(precision):
P=TP/TP+FP
查全率(recall):
R=TP/TP+FN
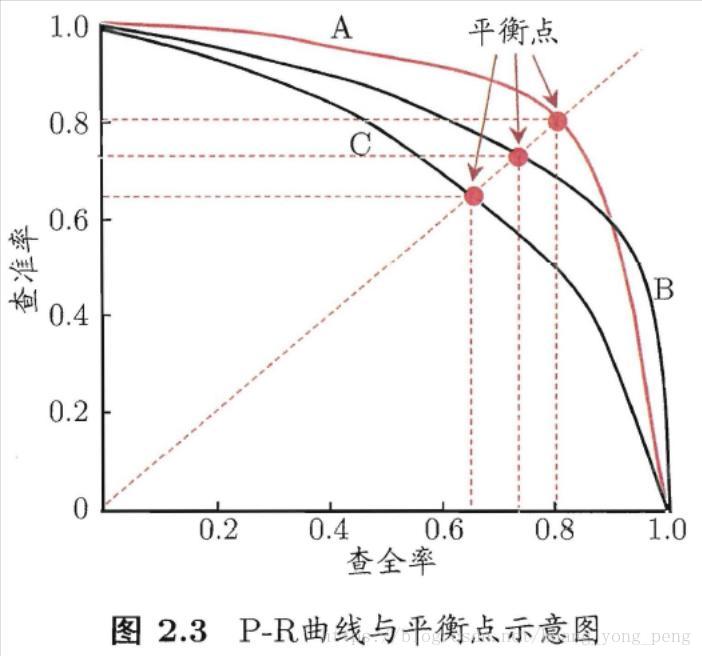
P-R曲线:
面积,平衡点
F1是基于precision与recall的调和平均(harmonic mean)
F1度量:P*R/2(P+R)
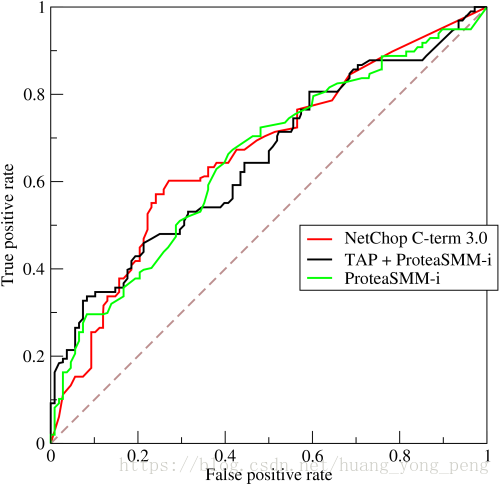
ROC曲线
ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。
- 横轴——假正例率:FPR=FP/TN+FP
- 纵轴——真正例率:TPR=TP/TP+FN
考虑ROC曲线图中的四个点和一条线。
第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。
第四个点(1,1),分类器实际上预测所有的样本都为正样本。
经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。