一、精确率与召回率
1、精确率(Presicion)
预测结果为正例样本中真实为正例的比例(查的准)。

2、召回率(Recall)
真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)。

3、精确率与召回率的理解
- 混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)。
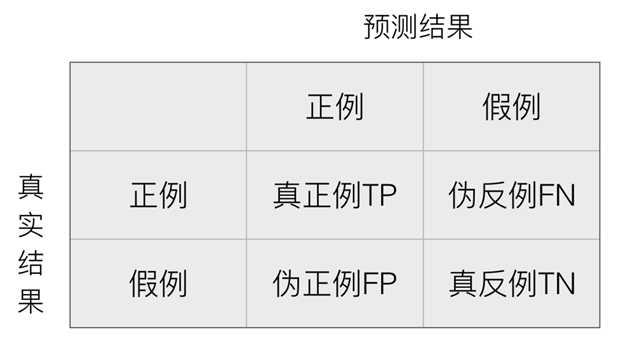
例如:在100个人中有20人患病,80人健康,这是真实结果;预测结果可能是10人患病,90人正常。那么这个例子中,每一个样本有两种结果要么患病,要么正常,假设患病为正例,不患病(正常)为假例,那么:
召回率为:
(10/20)*100% = 50%
显然,召回率的值越大越好,说明预测的就越贴近真实。
4、其它指标(F1-score)
反映模型的稳健性。
\[{F_1} = \frac{{2TP}}{{2TP + FN + FP}} = \frac{{2\Pr ecision*{\mathop{\rm Re}\nolimits} call}}{{\Pr ecision + {\mathop{\rm Re}\nolimits} call}}\]
该值越大,说明模型越稳健。
5、分类模型评估API
- sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值 y_pred:估计器预测目标值 target_names:目标类别名称 return:每个类别精确率与召回率
将其运用到之前的20篇文章分类中进行测试:
from sklearn.datasets import fetch_20newsgroups from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.metrics import classification_report def naive_bytes(): """ 朴素贝叶斯进行文本分类 :return: None """ #获取数据 news = fetch_20newsgroups(subset='all') #进行数据分割 x_train,x_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25) #对数据集进行特征抽取 tf = TfidfVectorizer() #以训练集当中的词的列表进行每篇文章重要性统计 x_train = tf.fit_transform(x_train) print(tf.get_feature_names()) #特征值 x_test = tf.transform(x_test) #进行朴素贝叶斯算法预测 mlt = MultinomialNB(alpha=1.0) mlt.fit(x_train,y_train) y_predict = mlt.predict(x_test) print("文章的预测类别为:",y_predict) #准确率 print("准确率为:",mlt.score(x_test,y_test)) #每一个类别的精确率和召回率 result = classification_report(y_test,y_predict,target_names=news.target_names) print(result) return None if __name__ == '__main__': naive_bytes()
二、交叉验证与网格搜索
(一)交叉验证
1、什么是交叉验证
数据集我们一般分为训练集和测试集,交叉验证针对的就是训练集,将训练集的数据再次重新划分:
- 训练集进行n等分
- 其中一份作为验证集合
- 其余各份都是作为训练集
经过n组测试,每次更换不同的验证集,这样就会得到n组模型的结果,取所有模型结果的平均值作为最终的结果,该方法又被称为n折交叉验证,比如下面的四折交叉验证:
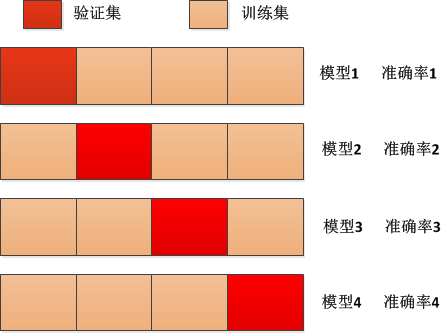
将上述4个模型的准确率进行求平均值,从而得到最终的结果,其最明显的应用就是在k-近邻算法中k的取值默认为5,假如我们将k=1,6,8,11,每一个k值下进行4折验证取平均值,然后看哪一个k值下的效果更好就取哪一个k值,这样就更好。
2、为什么进行交叉验证
为了让被评估的模型更加精确、可信。
(二)网格搜索(超参数搜索)
1、什么是网格搜索
网格搜索一般是和上述的交叉验证进行配合使用, 那么什么是网格搜索呢?通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
就像上面预设的k=1,6,8,11,然后对其进行4折验证取平均值,然后看每一个预设k值得效果,取最好的即可。
如果出现超参数有多个,那么就会进行组合,比如x=[1,2,3],y=[1,2,3],z=[4,5,6],这样对27种组合,每一种进行10折验证取平均值,得到27种结果,取最好的组合结果即可。
2、网格搜索API
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
其中:
estimator:估计器对象(knn对象)
param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
fit:输入训练数据
score:准确率
当然,还有一些输出结果的参数可供查看:
best_score_:在交叉验证中测试的最好结果
best_estimator_:最好的参数模型(比如knn中k的值代表的模型)
cv_results_:每次交叉验证后的测试集准确率结果和训练集准确率结果
- 实例说明
import pandas as pd from sklearn.model_selection import train_test_split,GridSearchCV from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier import numpy as np def knn(): """ 近邻算法:预测入住位置 :return: """ # 读取训练集数据 df = pd.read_csv("./data/k-近邻算法数据/train.csv") # 读取前5行数据 # print(df.head(5)) """ 进行数据处理: 1、缩小数据范围 2、时间戳处理 3、删除少于指定位置的签到人数位置删除 """ # 1、缩小数据范围 df = df.query("x>0 & x<1.2 & y>0 & y<1.23") # # 2、时间戳处理 df_time = pd.to_datetime(df["time"], unit='s') # print(df_time) """ 132 1970-01-08 19:14:45 142 1970-01-02 00:41:22 ... """ # #把日期格式处理成字典格式 time_dict = pd.DatetimeIndex(df_time) # print(time_dict) """ DatetimeIndex( ['1970-01-08 19:14:45', '1970-01-02 00:41:22', '1970-01-07 06:32:23', '1970-01-02 18:59:24',...], dtype='datetime64[ns]', name='time', length=417477, freq=None ) """ # 构造时间特征 df["day"] = time_dict.day df["hour"] = time_dict.hour df["weekday"] = time_dict.weekday # 删除时间戳这一列 df = df.drop(['time'], axis=1) # print(df) """ row_id x y ... day hour weekday 132 132 0.1902 0.1510 ... 8 19 3 142 142 0.1318 0.4975 ... 2 0 4 149 149 0.0179 0.2321 ... 7 6 2 ... """ # 3、删除少于指定位置的签到人数位置删除 place_count = df.groupby('place_id').count() # print(place_count) """ row_id x y accuracy day hour weekday place_id 1000213704 22 22 22 22 22 22 22 1000842315 6 6 6 6 6 6 6 1002574526 1 1 1 1 1 1 1 1002803051 1 1 1 1 1 1 1 ... """ # 过滤出少于指定位置的签到人数位置,通过reset_index将索引转成列进行操作 pf = place_count[place_count["row_id"] > 3].reset_index() # print(pf) """ place_id row_id x y accuracy day hour weekday 0 1000213704 22 22 22 22 22 22 22 1 1000842315 6 6 6 6 6 6 6 ... """ # 根据指定place_id进行过滤 df = df[df['place_id'].isin(pf['place_id'])] # print(df) """ 获取特征值、目标值 """ # 1、获取特征值 x = df.drop(['place_id'], axis=1) # 2、获取目标值 y = df['place_id'] """ 进行数据集分割,分成训练集和测试集 """ x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) """ 特征工程:标准化 """ sd = StandardScaler() # 对训练集进行标准化 x_train = sd.fit_transform(x_train.astype(np.float64)) # 对测试集进行标准化 x_test = sd.transform(x_test.astype(np.float64)) """ 进行KNN算法预测 fit predict score """ knn = KNeighborsClassifier() #相当于网格搜索参数中的estimator #构造预设参数 param = {"n_neighbors":[2,8,10,12]} #进行网格搜索 gc = GridSearchCV(knn,param_grid=param,cv=2) gc.fit(x_train,y_train) #训练模型 #输出结果 print('测试集上的准确率:',gc.score(x_test,y_test)) print('交叉验证当中最好的结果:',gc.best_score_) #比较每个超参数最后的2折平均值,选择最大的那个 print('选择最好的模型是:',gc.best_estimator_) #选择出最合适的n_neighbors print('每个超参数每次交叉验证的结果:',gc.cv_results_) #每个超参数有两个结果 if __name__ == '__main__': knn()