原论文地址:https://arxiv.org/abs/1609.03499
WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
| Aaron van den Oord |
Sander Dieleman |
Heiga Zen |
| Karen Simonyan |
Oriol Vinyals |
Alex Graves |
| Nal Kalchbrenner |
Andrew Senior |
Koray Kavukcuoglu |
{avdnoord, sedielem, heigazen, simonyan, vinyals, gravesa, nalk, andrewsenior, korayk}@google.com
Google DeepMind, London, UK
Google, London, UK
摘要
这篇论文提出了WaveNet,一个生成原始音频波形的深度神经网络。这是一个完全的概率自回归模型,它基于之前已经生成的所有样本,来预测当前音频样本的概率分布;不过,我们将会展示它可以在每秒数万采样率的音频数据上高效的进行训练。将其应用到语音合成,它可以获得当前业界最佳的性能,不管是英语还是中文普通话,相比之前最好的参数式和拼接式系统,人类听众评价其在自然度上有大幅度进步。单一模型的WaveNet可以以相同的保真度捕获很多说话人的特征,并可以针对说话者进行训练后在多人之间切换。将其应用于音乐合成,我们发现它可以产生新颖的高度真实的音乐片段。同时,我们也会展示它还可以作为判别模型应用在音素识别中,获得有可观前景的结果。
1 介绍
近来对图像(van den Oord et al., 2016a;b)和文本(Jozefowicz et al., 2016)等复杂分布进行建模的神经自回归生成模型有了进展,受这些进展的启发,我们研究了原始音频生成技术。使用神经网络架构,把像素或者单词的联合概率作为条件概率分布的乘积的建模方法,取得了业界最佳的成绩。
特别是,这些架构可以对上千个随机变量(例如在PixelRNN中64x64像素(van den Oord et al., 2016a))的概率分布进行建模。这篇论文要解决的问题是,同样的方法是否可以在宽带原始音频波形的生成中奏效,这些音频波形信号具有非常高的短时分辨率,至少每秒16000个样本(参照图1)。

这篇论文介绍WaveNet,一个基于PixelCNN(van den Oord et al., 2016a;b)架构的音频生成模型。这份研究的主要贡献是:
l 展示了WaveNet可以生成原始语音信号,其自然度由人类裁判进行主观评分,这在语音合成(TTS)领域还未被报道过。
l 为了处理原始音频生成中所需的大跨度时间依赖,我们基于扩大因果卷积开发了新的架构,它具有非常大的感受野。
l 展示了 如果基于说话人身份进行训练,单个模型可以生成不同风格的语音。
l 同样的架构在小规模语音识别数据集的测试中获得了很好的结果,同时用于音乐等其他形态的音频生成中也有很好的前景。
我们相信WaveNet为很多依赖于音频生成的应用(如语音合成,音乐,语音增强,语音转换,声源分离),提供了一个通用的灵活的框架。
2 WAVENET
这篇论文中我们提出一个新的生成模型,它能直接产生原始音频波形。音频波形的联合概率x = {x1; : : : ; xT}可以分解成如下条件概率分布的乘积:
![]()
因此每一个音频样本xt都依赖之前所有步骤产生的样本。
与PixelCNNs (van den Oord et al., 2016a;b)类似,条件概率分布由若干卷积层进行建模。网络中没有下采样层,模型的输出与输入具有相同的时间维度。模型使用softmax层输出一个xt上的类别分布,使用最大对数似然方法对参数进行优化。由于对数似然易于处理,我们在验证数据集上对超参数进行优化,可以容易的测定模型过拟合或者欠拟合。
2.1 扩大因果卷积
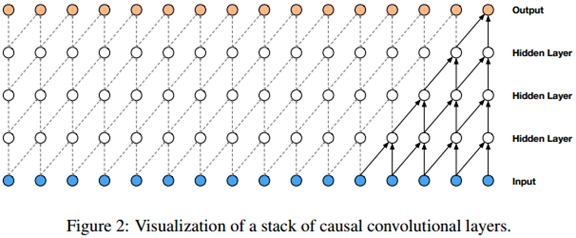
WaveNet的主要成分是因果卷积。因果卷积确保了模型输出不会违反数据的顺序:模型在t时刻输出的预测p (xt+1 | x1; :::; xt)不会依赖任何一个未来时刻的数据xt+1; xt+2; : : : ; xT,如图2所示。对图像来说,因果卷积是一个遮蔽卷积(van den Oord et al., 2016a),可以在使用前通过构建一个遮蔽张量与卷积核进行点乘来实现。对于音频这样的一维数据来说实现起来更简单,将正常卷积的输出偏移几个时间步骤即可。
在训练阶段,由于标定真实数据x的所有时间步骤都是已知的,因此所有时间步骤的条件概率预测可以并行进行。在推断阶段,预测结果是串行的:每一个预测出的样本都被传回网络用于预测下一个样本。
由于使用因果卷积的模型中没有循环连接,通常训练起来比RNN更快,特别是对于很长的句子的训练。因果卷积存在的一个问题是它需要很多层,或者很大的卷积核来增大其感受野。例如,在图2中,感受野只有5(=层数 + 卷积核长度 - 1)。在这篇论文中,我们使用扩大卷积(dilated convolution)使感受野增大几个数量级,同时不会显著增加计算成本。
扩大卷积(也称为带洞卷积),是卷积核在比自身大的数据上进行卷积时跳步的卷积方法。这与通过用零补边使卷积核扩大的效果是一样的,但是这样效率更高。与正常卷积相比,扩大卷积有效地使网络可以执行粗粒度的卷积操作。这与下采样或者跳步卷积类似,只是这里的输出保持与输入同样大小。作为特例,扩大因子=1的扩大卷积就是标准卷积。图3描绘了扩大因子为1,2,4,8的扩大因果卷积。扩大卷积之前在不同的上下文中被使用过,如信号处理(Holschneider et al., 1989; Dutilleux, 1989),图像分割(Chen et al., 2015; Yu & Koltun, 2016)。
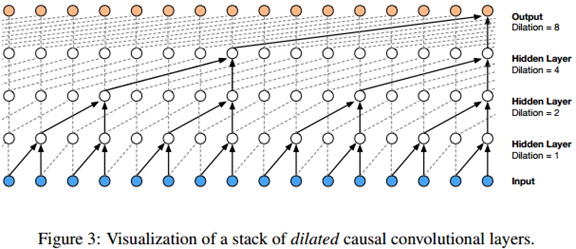
堆叠式扩大卷积使得网络只通过少数几层便拥有了非常大的感受野,同时保留了输入分辨率和计算效率。在这边论文中,扩大系数每层都翻倍直到上限,然后重复循环,如:1; 2; 4; : : : ; 512; 1; 2; 4; : : : ; 512; 1; 2; 4; : : : ; 512。
这种配置其背后的直觉有两个。首先随着深度增加,扩大因子的指数增长可以使感受野呈指数级增大(Yu & Koltun, 2016)。例如每一组1;2;4;:::;512这样的卷积模块都拥有1024大小的感受野, 可视为与1x1024卷积对等的更高效的(非线性)判别式卷积操作 。其次,将多组这样的卷积模块堆叠起来会进一步增大模型容量和感受野大小。
2.2 SOFTMAX分布
对单个音频样本的条件概率分布进行建模的一个方法是使用混合模型,如混合密度网络(Bishop, 1994)或者条件高斯尺度混合模型(MCGSM) (Theis & Bethge, 2015)。然而,van den Oord et al. (2016a)指出softmax分布倾向于更有效,即便数据是隐含式的连续数据(图像的像素光照强度或者音频采样值),该方法同样有效。原因之一是类别分布更灵活,并且由于对数据的形状没有假定前提,所以它更容易对任意分布进行建模。
因为原始音频通常保存为16位整数序列(每个时间步骤一个值),对每个时间步骤的所有可能值,softmax层将需要输出65536个概率,为了更容易处理,我们先对数据实施一个µ律压扩变换(ITU-T, 1988),然后量化成256个可能值:
![]()
这里−1 < xt < 1 并且µ = 255。与简单的线性量化相比,这个非线性量化处理可以对数据进行更好的重构,特别是对于语音数据,我们发现这样重构后的信号听起来非常接近原始信号。
2.3 门控激活单元
我们使用与gated PixelCNN (van den Oord et al., 2016b)中相同的门控激活单元:
![]()
这里*代表卷积操作,Sigma前面的符号代表点乘。σ(·)是sigmoid函数,k是层数索引,f和g是滤波器和门,W是可学习的卷积核。我们在最初的试验中观察到,对于音频信号建模,这个非线性操作显著优于ReLU激活函数(Nair & Hinton, 2010)。
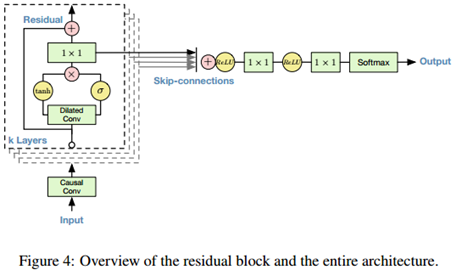
2.4 残差和跳步连接
网络中使用了残差(He et al., 2015)和参数化跳步连接,以加速收敛,并使梯度下降能在更深的模型中传播。 。在图4中我们展示了模型中的一个残差模块,网络中会将多个这样的模块堆叠在一起:
2.5 WAVENET条件建模
给定一个额外输入h,WaveNet可以对这个给定输入进行条件分布建模,这时公式(1)就变成了:
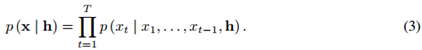
基于额外的变量进行条件建模,我们可以引导模型产生有期望特点的音频。例如,在多人对话场景中,通过把说话人身份作为额外的条件输入给模型,我们可以从模型中选择某个说话人进行音频输出。类似的,在TTS任务中,我们需要额外的关于文本的信息输入给模型(译者:以在模型中选择符合特定条件的文本进行输出(比如新闻类,体育类风格))。
基于额外变量进行条件建模有两种方式:全局条件和局部条件。全局条件的特点是,通过单一的隐式表达h作为额外输入,在所有时间步骤上影响输出分布,例如被嵌入到TTS模型中的说话人。公式(2)的激活函数现在变成了:
![]()
这里V*,k是一个可学习的线性投影,V*,kTh在所有时间节点上进行传播。
局部条件建模,我们准备第二个时间序列ht,可以通过对原始音频信号进行低频率采样获得,比如TTS模型中的语言学特征。我们首先用转置卷积网络(上采样)将音频信号映射到一个新的时间序列y = f(h),使其具有与音频信号相同的分辨率,然后交由激活单元处理,如下:
![]()
这里Vf,k*y是一个1x1卷积。作为转置卷积网络的替代方法,也可以使用Vf,k*h,然后沿时间重复这些值,但是在我们的实验中,这个方法的表现稍差一些。
2.6 上下文堆栈(CONTEXT STACKS)
我们提出了多种方法来增加WaveNet的感受野大小:增加扩大卷积模块数,模块内使用更多的扩大卷积层,更大的卷积核,更大的扩大因子,或者他们的组合。增加感受野的另外一个补充方法是,使用一个独立的更小的上下文堆栈来处理语音信号的长跨度信息,并局部调试一个更大的WaveNet只用来处理语音信号的更短的局部信息(在结尾处截断)。可以使用多个变长的具有不同数量隐藏单元的上下文堆栈,拥有越大感受野的堆栈其每层含有的隐藏单元越少。上下文堆栈还可以使用池化层来降低频率,这使得计算成本被控制在合理范围,也与用更长的跨度对时间相关性建模会使体量更小的直觉相吻合。
3 实验
为了测量WaveNet音频建模的性能,我们在三个不同的任务上对其进行评估:多说话人语音生成(没有基于文本训练),文本合成语音,音乐音频建模。我们在网站上公布了实验中WaveNet生成的音频样本:
https://www.deepmind.com/blog/wavenet-generative-model-raw-audio/.
3.1多说话人语音生成
第一个实验进行自由格式的语音生成(没有基于文本进行调节训练)。我们使用VCTK(Yamagishi, 2012)数据集中的英文多人语料,并基于说话人进行了条件建模,条件建模的条件是发言者的id(采用one hot 编码)。数据集总共包含109位不同说话人的44小时语音数据。
由于模型没有基于文本进行建模,因此它会产生不存在的但是听起来很像人类语言的词语,而且很流畅,语调逼真。这与语言或图像的生成模型很相似,其生成的样本咋一看很逼真,细看就不自然了。生成的语音在长跨度上缺乏连贯性,部分是由于受模型感受野大小的限制(大概300毫秒),这意味着模型只能记住它产生的最后2-3个音素。
单个WaveNet可以通过one-hot编码对任意一个说话人的语音进行建模。这确认了单个模型也能够从数据中捕获所有109人特征的足够强大的能力。我们观察到,与在单人数据集上训练相比,增加训练集的说话人数量可以在验证集上获得更好的性能。这提示我们,WaveNet的内部表达在多个说话人中是共享的。
最后,我们观察到,模型从音频中不但提取到了语音特征,还提取到了其他的特征,如音响质量,说话人的呼吸和嘴部动作等。
3.2 文本合成语音
第二个实验选择TTS。我们使用Google北美英语和中文普通话TTS系统使用的单说话人语音数据集。北美英语数据集包含24.6小时数据,中文普通话数据集包含34.8小时数据,两个数据集都由专业女播音员录制。
在TTS任务中,首先基于从输入文本获得的语言学特征进行调节训练WaveNet。另外还在语言学特征+对数基频(F0)上调节训练了WaveNet。两种语言都训练了外部模型,用来从语言学特征预测对数基频和音长。WaveNet的感受野是240毫秒。还构建了HMM单元选择拼接(Gonzalvo et al., 2016)语音合成器作为基于例句的基线,以及LSTM-RNN统计参数(Zen et al., 2016)语音合成器作为基于模型的基线。由于使用相同的数据集和语言学特征来训练基线语音合成器和WaveNet模型,对结果的性能比较应该是公平的。
为了评估WaveNet的性能,我们实施了主观配对比较测试和平均意见得分(MOS)测试。在主观配对比较测试中,听完每一对样本,评分者会选择他们更喜欢哪一个样本,如果没有倾向也可以选择中立。在MOS测试中,听完每一个合成结果,评分者会对语音的自然度进行5分制打分(1:很差,2:差,3:一样,4:好,5:很好),详细情况请参考附录B。
图5展示了主观配对比较测试的结果之一(全部测试结果请看附录B)。从结果来看,WaveNet在两种语言上都优于基线的统计式和参数式语音合成器。我们发现只用语言学特征调节训练的WaveNet,其合成的语音有很自然的断句,但有时候会弄错重音而使韵律不自然。这可能是由于F0轮廓的大跨度依赖造成的:WaveNet的感受野只有240毫秒,不能捕获这么大跨度的依赖。而同时用语言学特征和F0训练的WaveNet就没有这个问题:预测F0的外部模型以低频(200Hz)运行,所以它可以学到存在于F0轮廓中的大跨度依赖。
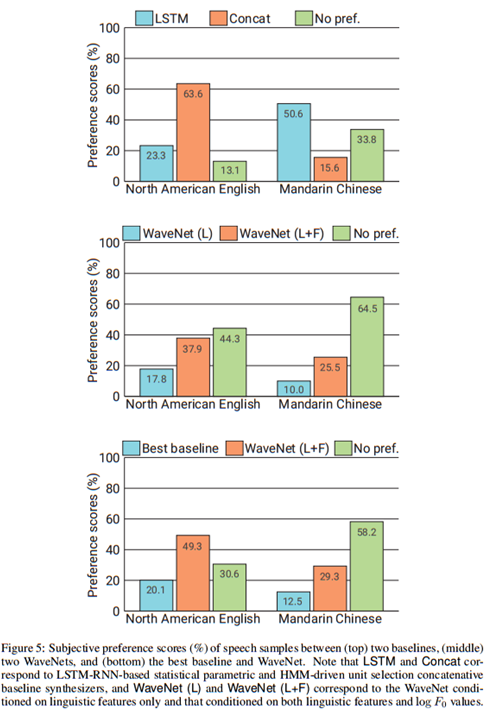
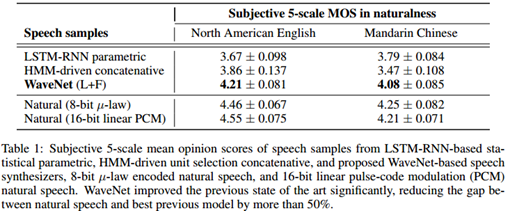
表1展示了MOS测试结果。从表中可以看出WaveNet的自然度在5分制MOS评分中超过了4分,比基线系统高出一大截。它们是目前MOS得分的最高纪录。合成语音与人类自然语音的MOS得分差距,在美式英语中从0.69下降到0.34(51%),中文普通话从0.42下降到0.13(69%)。
3.3 音乐生成
第三组实验选择对两组音乐数据建模:
l MagnaTagATune数据集 (Law & Von Ahn, 2009), 包含200小时音乐,每个片段29秒,片段都加注了标签(总共188种),包括流派,乐器,节拍,音量和情绪。
l YouTube钢琴数据集,包含60小时独奏。由于限定于单一乐器,所以建模相对容易。
尽管模型评估难以量化,但是可以通过倾听生成的样本进行主观评价。我们发现扩大感受野是获取悦耳音频的关键。即使把感受野增加到数秒长,模型也没能取得长时间的一致性,每秒的流派,乐器,音量和声音质量都有变化。然而,即使是非条件建模产生的音乐样本,听起来也很和谐,令人愉悦。
一个特殊的兴趣是进行条件建模,使模型产生特定标签的音频,如不同流派或乐器的音乐。与条件语音生成模型类似,每个音乐片段都有关联的音乐标签,把这些标签用二进制向量表达,然后给模型插入一个依赖于这些二进制向量的偏置参数,这样通过给模型传入一个代表了想要的属性的二进制向量,就使得在模型生成合成样本时可以控制输出的不同特性。我么在MagnaTagAtune数据集上训练模型,尽管数据标签有噪声和遗漏,经过清洗合并类似标签并移除标签所含数据过少的音乐片段,训练结果还是不错的。
3.4 语音识别
尽管WaveNet被设计成生成模型,但是也可以直接修改为判别模型来完成语音识别这样的判别任务。
传统上,语音识别研究主要关注梅尔滤波器组能量谱,或者梅尔频率倒谱系数(MFCCs)的使用,但是近期的研究(Palaz et al., 2013; Tuske et al., 2014; Hoshen et al., 2015; Sainath et al., 2015)开始转向直接对原始语音数据进行建模。循环神经网络,如LSTM-RNNs(Hochreiter & Schmidhuber, 1997),在这些新的语音分类流水线中已经成为主要组件,因为它允许对大跨度上下文进行建模。使用WaveNet的扩大卷积,相比LSTM,可以用极低的成本增大感受野。
最后一个实验,我们在TIMIT (Garofolo et al., 1993)数据集上用WaveNet进行语音识别。这个实验中我们在扩大卷积后面增加了一个平均池化层,它把激活输出聚合成10毫秒的帧(160×下采样)。池化层后接几个非因果卷积。损失函数包含两项,一项是下一个样本的预测损失,另一项是数据帧分类损失,两项损失比单项损失的泛化能力更好,在测试集上获得了直接从TIMIT原始语音数据建模的最好结果:18:8 PER。
4 结论
这篇论文提出了WaveNet,该模型可以直接对原始语音数据进行建模。WaveNet是自动回归的,它结合了因果卷积和扩大卷积,让感受野随着模型深度增加而指数级增加。感受野的增加对原始语音建模中的大跨度依赖非常重要。我们还展示了WaveNet如何基于其他额外输入进行全局(说话人身份)和局部(语言学特征)条件建模。
应用到TTS中,WaveNet生成的语音样本在主观自然度上优于目前的最佳模型。最后WaveNet在音乐建模和语音识别上也很有前景。
ACKNOWLEDGEMENTS
The authors would like to thank Lasse Espeholt, Jeffrey De Fauw and Grzegorz Swirszcz for their inputs, Adam Cain, Max Cant and Adrian Bolton for their help with artwork, Helen King, Steven Gaffney and Steve Crossan for helping to manage the project, Faith Mackinder for help with preparing the blogpost, James Besley for legal support and Demis Hassabis for managing the project and his inputs.
附录:
A:文本转语音背景
TTS语音合成的目标是给定一段文本合成出听感自然的语音信号。人类语音的产生过程中,首先把一段语音(或者观念)转换成发音器官的肌肉运动,然后使用从肺呼出的气流作为声源激励信号而产生的,声源激励信号中包含周期性信号(通过声带振动)和非周期性信号(通过扰动噪声)成分。由发音器官控制的时变声道传递函数,对声源激励信号进行滤波,从而声源的频率特征得到了调制。最后,生成的语音信号被发送出来。TTS的目的就是要用计算机模拟这个发音过程。
TTS语音合成可以看作是seq2seq的映射问题:从一个离散符号序列(文本)映射到一个实数时间序列(语音信号)。典型的TTS流水线包含两部分:一是文本分析,二是语音合成。文本分析部分通常包含很多自然语言处理(NLP)步骤,例如断句,分词,文本正规化,词性标注(POS),字音转换(G2P)。文本分析把词序列作为输入,输出具有多样化语言学上下文的音素序列。语音合成部分输入上下文依赖的音素序列,输出合成的语音波形,这部分通常包括韵律预测和语音波形生成。
实现语音合成部分主要有两种方法:非参数基于样例的方法,也称为拼接式语音合成(Moulines & Charpentier, 1990; Sagisaka et al., 1992; Hunt & Black, 1996),以及参数化基于模型的方法,也称为统计参数式语音合成(Yoshimura, 2002; Zen et al., 2009)。拼接式方法从预先录制的语音中选取语音单元然后拼接成句子,而统计参数方法使用一个生成模型来合成语音。统计参数方法从语音信号x = {x1; : : : ; xT }中提取声码器参数(Dudley, 1939) o = {o1; : : : ; oN},并从文本W中提取语言学特征 l,这里N和T对应声码器参数向量和语音信号的个数。通常声码器参数向量oN每5毫秒提取一次,声码器参数通常包括,代表声道传递函数的倒谱(Imai & Furuichi, 1988)或者线谱对,以及代表声源激励信号的基频(F0)和非周期性噪声(Kawahara et al., 2001)。然后基于提取出的声码器参数和语言学特征训练一组生成式模型,如隐马尔科夫模型(HMMs) (Yoshimura, 2002),前向传递神经网络(Zen et al., 2013),以及循环神经网络(Tuerk & Robinson, 1993; Karaali et al., 1997; Fan et al., 2014),使得:
![]()
其中Λ代表生成式模型的参数集。在合成阶段,给定从文本中提取的语言学特征,生成最大可能的声码器参数:
![]()
随后声码器把生成的声码器参数o^重构语音波形。统计参数方法相比拼接式方法有多方面好处,比如体量小,容易修改语音特征等。然而,它的主观自然度经常比拼接式方法差很多:其合成的语音听起来含混不清并且有人工痕迹。Zen et al. (2009)指出了降低主观自然度的三个因素:声码器质量,生成式模型的精度以及过度平滑效果的影响。第一个因素导致了人工痕迹,后两个导致了合成语音的含混不清。已经有几个解决该问题的尝试,如开发高品质声码器(Kawahara et al., 1999; Agiomyrgiannakis, 2015; Morise et al., 2016),提高生成式模型的精度(Zen et al., 2007; 2013; Fan et al., 2014; Uria et al., 2015),以及过度平滑效果补偿(Toda & Tokuda, 2007; Takamichi et al., 2016)。Zen et al. (2016)指出,在某些语言上,业界最佳的统计参数式语音合成器已经可以匹敌业界最佳拼接方法。然而,它合成的声音质量仍然是一个主要问题。
提取声码器参数可以看作是给定语音信号情况下生成式模型参数的一个估计(Itakura & Saito, 1970; Imai & Furuichi, 1988)。例如,在语音编码中已经被使用的线性预测分析(Itakura & Saito, 1970),假定语音信号的生成式模型是一个线性自动回归(AR)的零均值高斯过程:

其中ap是第p阶线性预测系数(LPC),G2是模型方差。这些参数是基于最大似然(ML)准则的估计值。这样说来,统计参数方法的训练部分可以看作是一个两阶段优化和局部最优过程:通过让生成式模型拟合语音信号来提取声码器参数,然后用另外一个生成式模型对声码器参数进行建模来生成时间序列波形(Tokuda, 2011)。之前有几个尝试要把两个阶段合二为一(Toda & Tokuda, 2008; Wu & Tokuda, 2008; Maia et al., 2010; Nakamura et al., 2014; Muthukumar & Black, 2014; Tokuda & Zen, 2015; 2016; Takaki & Yamagishi, 2016)。例如,Tokuda & Zen (2016) 把非平稳的非零均值的高斯过程的语音信号生成模型和基于LSTM-RNN的生成模型整合成一个模型并通过向后传播算法进行了联合优化。尽管他们展示了这个模型可以逼近自然语音喜好,但是过度泛化和对语音信号的噪声成分的过度估计,使得其分段自然度显著差于非整合模型。
传统的原始音频信号生成模型的很多假设是受语音产生过程的启发,比如:
l 使用定长分析窗口:这种方法通常基于一个平稳的随机过程(Itakura & Saito, 1970; Imai & Furuichi, 1988; Poritz, 1982; Juang & Rabiner, 1985; Kameoka et al., 2010)。用平稳随机过程对时变语音信号建模,模型参数在一个固定长度,交叠的一定分析窗口(通常长度为20-30毫秒,窗移5-10毫秒)上进行估计。然而如停顿等一些音素其音长不足20毫秒(Rabiner & Juang, 1993),因此使用这种定长分析窗有限制。
l 线性滤波器:这些生成式模型通常在一个窗帧内部实现成线性时不变滤波器(Itakura & Saito, 1970; Imai & Furuichi, 1988; Poritz, 1982; Juang & Rabiner, 1985; Kameoka et al., 2010)。然而,连续音频样本之间的关系是高度非线性的。
l 高斯过程假设:传统的生成式模型是基于高斯过程的(Itakura & Saito, 1970; Imai & Furuichi, 1988; Poritz, 1982; Juang & Rabiner, 1985; Kameoka et al., 2010; Tokuda & Zen, 2015; 2016)。从语音产生(Chiba & Kajiyama, 1942; Fant, 1970)过程的声源-滤波器模型观点来说,这与假定声源激励信号是一个高斯分布的样本(Itakura & Saito, 1970; Imai & Furuichi, 1988; Poritz, 1982; Juang & Rabiner, 1985; Tokuda & Zen, 2015; Kameoka et al., 2010; Tokuda & Zen, 2016)是对等的。有了上面的线性假定,就可以假定语音信号是服从正太分布的。
然而,真实语音信号的分布与高斯分布大不相同。尽管这些假设很便利,用这些模型生成的样本往往嘈杂并且丢失了使语音听起来更自然的重要细节。
在第2节描述的WaveNet,没有基于上面这些假设,除了选择感受野和使用信号µ律编码算法,它几乎不需要任何音频信号的先验知识。它也可以看作是量化信号的一个非线性的因果滤波器。尽管这样一个非线性滤波器可以在保留细节的同时表达复杂信号,但是设计这样的滤波器通常很困难(Peltonen et al., 2001)。WaveNet给出了一个直接从数据训练它的方法。
B:TTS实验细节
使用16k赫兹采样率的语音数据,构建了基于HMM的单元选择语音合成器和WaveNet TTS系统。尽管LSTM-RNN是基于22.05kHz采样率的语音数据训练的,16kHz采样率的语音在合成时使用Vocaine声码器(Agiomyrgiannakis, 2015)的函数进行了重采样。基于LSTM-RNN的统计参数模型和基于HMM的单元选择语音合成器都是基于16位线性PCM语音数据集构建,而WaveNet语音合成器基于同一数据集的8位µ律编码进行的训练。
语言学特征包括音素,音节,词,短语以及句子特征(Zen, 2006)(例如音素id,音节重音,词内音节数量,音节在短语中的位置),以及帧位置和音素时长特征(Zen et al., 2013)。在训练阶段,每5毫秒对这些特征进行音素水平的强制对齐,从而把这些特征与语音信号关联在一起。我们使用基于LSTM-RNN的音长预测模型,以及基于自回归CNN的对数基频(F0)预测模型。使用最小均方差(MSE)训练模型。请注意,WaveNet生成的语音信号没有经过任何后处理。
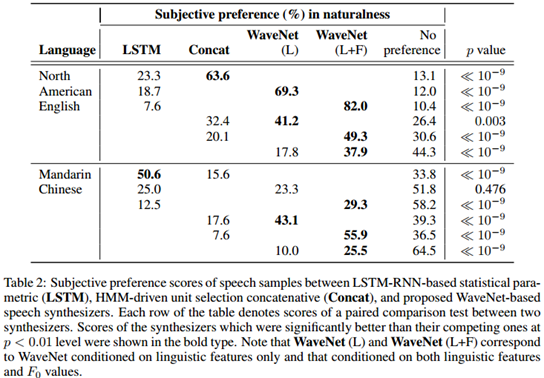
主观聆听测试是众包盲测,使用没在训练数据集中出现的100个句子作为评估数据。每一位评测者可以评估最多8个北美英语或最多63个中文普通话句子。测试句子随机选择并播放给测试者。在配对比较测试中,每一对语音样本都是不同模型对同一段文本的合成结果。在MOS测试中,每个句子都隔离的播放给评测者。在配对比较测试中每对句子都由8位评测者打分,在MOS测试中每个句子由八位评测者进行打分。评测者都是说母语的人并且评测是付费的。在进行偏向性和MOS评分时,未使用头戴式耳机的评分(约40%)被排除在外。表2展示了图5种配对比较测试的所有细节信息:
REFERENCES
Agiomyrgiannakis, Yannis. Vocaine the vocoder and applications is speech synthesis. In ICASSP, pp. 4230–4234, 2015.
Bishop, Christopher M. Mixture density networks. Technical Report NCRG/94/004, Neural Computing Research Group, Aston University, 1994.
Chen, Liang-Chieh, Papandreou, George, Kokkinos, Iasonas, Murphy, Kevin, and Yuille, Alan L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015. URL http://arxiv.org/abs/1412.7062.
Chiba, Tsutomu and Kajiyama, Masato. The Vowel: Its Nature and Structure. Tokyo-Kaiseikan, 1942.
Dudley, Homer. Remaking speech. The Journal of the Acoustical Society of America, 11(2):169–177, 1939.
Dutilleux, Pierre. An implementation of the “algorithme a trous” to compute the wavelet transform. In Combes, Jean-Michel, Grossmann, Alexander, and Tchamitchian, Philippe (eds.), Wavelets: Time-Frequency Methods and Phase Space, pp. 298–304. Springer Berlin Heidelberg, 1989.
Fan, Yuchen, Qian, Yao, and Xie, Feng-Long, Soong Frank K. TTS synthesis with bidirectional LSTM based recurrent neural networks. In Interspeech, pp. 1964–1968, 2014.
Fant, Gunnar. Acoustic Theory of Speech Production. Mouton De Gruyter, 1970.
Garofolo, John S., Lamel, Lori F., Fisher, William M., Fiscus, Jonathon G., and Pallett, David S. DARPA TIMIT acoustic-phonetic continuous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon technical report, 93, 1993.
Gonzalvo, Xavi, Tazari, Siamak, Chan, Chun-an, Becker, Markus, Gutkin, Alexander, and Silen, Hanna. Recent advances in Google real-time HMM-driven unit selection synthesizer. In Interspeech, 2016. URL http://research.google.com/pubs/pub45564.html.
He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015.
Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural Comput., 9(8):1735–1780, 1997.
Holschneider, Matthias, Kronland-Martinet, Richard, Morlet, Jean, and Tchamitchian, Philippe. A real-time algorithm for signal analysis with the help of the wavelet transform. In Combes, JeanMichel, Grossmann, Alexander, and Tchamitchian, Philippe (eds.), Wavelets: Time-Frequency Methods and Phase Space, pp. 286–297. Springer Berlin Heidelberg, 1989.
Hoshen, Yedid, Weiss, Ron J., and Wilson, Kevin W. Speech acoustic modeling from raw multichannel waveforms. In ICASSP, pp. 4624–4628. IEEE, 2015.
Hunt, Andrew J. and Black, Alan W. Unit selection in a concatenative speech synthesis system using a large speech database. In ICASSP, pp. 373–376, 1996.
Imai, Satoshi and Furuichi, Chieko. Unbiased estimation of log spectrum. In EURASIP, pp. 203–206, 1988.
Itakura, Fumitada. Line spectrum representation of linear predictor coefficients of speech signals. The Journal of the Acoust. Society of America, 57(S1):S35–S35, 1975.
Itakura, Fumitada and Saito, Shuzo. A statistical method for estimation of speech spectral density and formant frequencies. Trans. IEICE, J53A:35–42, 1970.
9ITU-T. Recommendation G. 711. Pulse Code Modulation (PCM) of voice frequencies, 1988.
Jozefowicz, Rafal, Vinyals, Oriol, Schuster, Mike, Shazeer, Noam, and Wu, Yonghui. Exploring the limits of language modeling. CoRR, abs/1602.02410, 2016. URL http://arxiv.org/abs/1602.02410.
Juang, Biing-Hwang and Rabiner, Lawrence. Mixture autoregressive hidden Markov models for speech signals. IEEE Trans. Acoust. Speech Signal Process., pp. 1404–1413, 1985.
Kameoka, Hirokazu, Ohishi, Yasunori, Mochihashi, Daichi, and Le Roux, Jonathan. Speech analysis with multi-kernel linear prediction. In Spring Conference of ASJ, pp. 499–502, 2010. (in Japanese).
Karaali, Orhan, Corrigan, Gerald, Gerson, Ira, and Massey, Noel. Text-to-speech conversion with neural networks: A recurrent TDNN approach. In Eurospeech, pp. 561–564, 1997.
Kawahara, Hideki, Masuda-Katsuse, Ikuyo, and de Cheveigne, Alain. Restructuring speech rep-resentations using a pitch-adaptive time-frequency smoothing and an instantaneous-frequencybased f0 extraction: possible role of a repetitive structure in sounds. Speech Commn., 27:187–207, 1999.
Kawahara, Hideki, Estill, Jo, and Fujimura, Osamu. Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis, modification and synthesis system STRAIGHT. In MAVEBA, pp. 13–15, 2001.
Law, Edith and Von Ahn, Luis. Input-agreement: a new mechanism for collecting data using human computation games. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 1197–1206. ACM, 2009.
Maia, Ranniery, Zen, Heiga, and Gales, Mark J. F. Statistical parametric speech synthesis with joint estimation of acoustic and excitation model parameters. In ISCA SSW7, pp. 88–93, 2010.
Morise, Masanori, Yokomori, Fumiya, and Ozawa, Kenji. WORLD: A vocoder-based high-quality speech synthesis system for real-time applications. IEICE Trans. Inf. Syst., E99-D(7):1877–1884, 2016.
Moulines, Eric and Charpentier, Francis. Pitch synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Commn., 9:453–467, 1990.
Muthukumar, P. and Black, Alan W. A deep learning approach to data-driven parameterizations for statistical parametric speech synthesis. arXiv:1409.8558, 2014.
Nair, Vinod and Hinton, Geoffrey E. Rectified linear units improve restricted Boltzmann machines. In ICML, pp. 807–814, 2010.
Nakamura, Kazuhiro, Hashimoto, Kei, Nankaku, Yoshihiko, and Tokuda, Keiichi. Integration of spectral feature extraction and modeling for HMM-based speech synthesis. IEICE Trans. Inf. Syst., E97-D(6):1438–1448, 2014.
Palaz, Dimitri, Collobert, Ronan, and Magimai-Doss, Mathew. Estimating phoneme class conditional probabilities from raw speech signal using convolutional neural networks. In Interspeech, pp. 1766–1770, 2013.
Peltonen, Sari, Gabbouj, Moncef, and Astola, Jaakko. Nonlinear filter design: methodologies and challenges. In IEEE ISPA, pp. 102–107, 2001.
Poritz, Alan B. Linear predictive hidden Markov models and the speech signal. In ICASSP, pp. 1291–1294, 1982.
Rabiner, Lawrence and Juang, Biing-Hwang. Fundamentals of Speech Recognition. PrenticeHall, 1993.
Sagisaka, Yoshinori, Kaiki, Nobuyoshi, Iwahashi, Naoto, and Mimura, Katsuhiko. ATR ν-talk speech synthesis system. In ICSLP, pp. 483–486, 1992.
10Sainath, Tara N., Weiss, Ron J., Senior, Andrew, Wilson, Kevin W., and Vinyals, Oriol. Learning the speech front-end with raw waveform CLDNNs. In Interspeech, pp. 1–5, 2015.
Takaki, Shinji and Yamagishi, Junichi. A deep auto-encoder based low-dimensional feature extraction from FFT spectral envelopes for statistical parametric speech synthesis. In ICASSP, pp. 5535–5539, 2016.
Takamichi, Shinnosuke, Toda, Tomoki, Black, Alan W., Neubig, Graham, Sakriani, Sakti, and Nakamura, Satoshi. Postfilters to modify the modulation spectrum for statistical parametric speech synthesis. IEEE/ACM Trans. Audio Speech Lang. Process., 24(4):755–767, 2016.
Theis, Lucas and Bethge, Matthias. Generative image modeling using spatial LSTMs. In NIPS, pp. 1927–1935, 2015.
Toda, Tomoki and Tokuda, Keiichi. A speech parameter generation algorithm considering global variance for HMM-based speech synthesis. IEICE Trans. Inf. Syst., E90-D(5):816–824, 2007.
Toda, Tomoki and Tokuda, Keiichi. Statistical approach to vocal tract transfer function estimation based on factor analyzed trajectory hmm. In ICASSP, pp. 3925–3928, 2008.
Tokuda, Keiichi. Speech synthesis as a statistical machine learning problem. http://www.sp.nitech.ac.jp/˜tokuda/tokuda_asru2011_for_pdf.pdf, 2011. Invited talk given at ASRU.
Tokuda, Keiichi and Zen, Heiga. Directly modeling speech waveforms by neural networks for statistical parametric speech synthesis. In ICASSP, pp. 4215–4219, 2015.
Tokuda, Keiichi and Zen, Heiga. Directly modeling voiced and unvoiced components in speech waveforms by neural networks. In ICASSP, pp. 5640–5644, 2016.
Tuerk, Christine and Robinson, Tony. Speech synthesis using artificial neural networks trained on cepstral coefficients. In Proc. Eurospeech, pp. 1713–1716, 1993.
Tuske, Zolt ¨ an, Golik, Pavel, Schl ´ uter, Ralf, and Ney, Hermann. Acoustic modeling with deep neural networks using raw time signal for LVCSR. In Interspeech, pp. 890–894, 2014.
Uria, Benigno, Murray, Iain, Renals, Steve, Valentini-Botinhao, Cassia, and Bridle, John. Modelling acoustic feature dependencies with artificial neural networks: Trajectory-RNADE. In ICASSP, pp. 4465–4469, 2015.
van den Oord, Aaron, Kalchbrenner, Nal, and Kavukcuoglu, Koray. Pixel recurrent neural networks. arXiv preprint arXiv:1601.06759, 2016a.
van den Oord, Aaron, Kalchbrenner, Nal, Vinyals, Oriol, Espeholt, Lasse, Graves, Alex, and Kavukcuoglu, Koray. Conditional image generation with PixelCNN decoders. CoRR, abs/1606.05328, 2016b. URL http://arxiv.org/abs/1606.05328.
Wu, Yi-Jian and Tokuda, Keiichi. Minimum generation error training with direct log spectral distortion on LSPs for HMM-based speech synthesis. In Interspeech, pp. 577–580, 2008.
Yamagishi, Junichi. English multi-speaker corpus for CSTR voice cloning toolkit, 2012. URL
http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html.
Yoshimura, Takayoshi. Simultaneous modeling of phonetic and prosodic parameters, and characteristic conversion for HMM-based text-to-speech systems. PhD thesis, Nagoya Institute of Technology, 2002.
Yu, Fisher and Koltun, Vladlen. Multi-scale context aggregation by dilated convolutions. In ICLR, 2016. URL http://arxiv.org/abs/1511.07122.
Zen, Heiga. An example of context-dependent label format for HMM-based speech synthesis in English, 2006. URL http://hts.sp.nitech.ac.jp/?Download
Zen, Heiga, Tokuda, Keiichi, and Kitamura, Tadashi. Reformulating the HMM as a trajectory model by imposing explicit relationships between static and dynamic features. Comput. Speech Lang., 21(1):153–173, 2007.
Zen, Heiga, Tokuda, Keiichi, and Black, Alan W. Statistical parametric speech synthesis. Speech Commn., 51(11):1039–1064, 2009.
Zen, Heiga, Senior, Andrew, and Schuster, Mike. Statistical parametric speech synthesis using deep
neural networks. In Proc. ICASSP, pp. 7962–7966, 2013.
Zen, Heiga, Agiomyrgiannakis, Yannis, Egberts, Niels, Henderson, Fergus, and Szczepaniak, Przemysław. Fast, compact, and high quality LSTM-RNN based statistical parametric speech synthesizers for mobile devices. In Interspeech, 2016. URL https://arxiv.org/abs/1606.06061.