Tacotron是谷歌于2017年提出的端到端语音合成系统,该模型可接收字符的输入,输出相应的原始频谱图,
然后将其提供给 Griffin-Lim 重建算法直接生成语音。原论文链接: Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
最近开始研究端到端语音合成。相关的论文原本准备自己翻译,看到网上已经有翻译的比较好的版本,
故转载于此,仅作略微修改。 翻译原地址:https://my.oschina.net/stephenyng/blog/1620467
摘要
这篇论文描述了Tacotron 2,一个直接从文本合成语音的神经网络架构。系统由两部分构成,一个循环seq2seq结构的特征预测网络,把字符向量映射到梅尔声谱图,后接一个WaveNet模型的修订版,把梅尔声谱图合成为时域波形。我们的模型得到了4.53的平均意见得分(MOS),而专业录制语音的MOS得分是4.58。为了验证模型设计,我们对系统的关键组件作了剥离实验研究,并且评估了使用梅尔频谱替代语言学、音长和F0特征作为WaveNet输入带来的影响。我们进一步展示了使用这种紧凑的声学中间表征可以显著地简化WaveNet架构。
1. 介绍
从文本生成自然语音(语音合成,TTS)研究了几十年[1]仍然是一项有挑战的任务。这一领域的主导技术随着时代的发展不断更迭。单元挑选和拼接式合成方法,是一项把预先录制的语音波形的小片段缝合在一起的技术[2, 3],过去很多年中一直代表了最高水平。统计参数语音合成方法[4, 5, 6, 7],是直接生成语音特征的平滑轨迹,然后交由声码器来合成语音,这种方法解决了带边界人工痕迹的拼接合成方法的很多问题。然而由这些方法构造的系统生成的语音与人类语音相比,经常模糊不清并且不自然。
WaveNet [8]是时域波形的生成式模型,它生成的语音质量开始可以与真人语音媲美,该模型已经应用到一些完整的语音合成系统中 [9, 10, 11]。然而WaveNet的输入数据(语言学特征,预测的对数基频(F0),以及音素时长)却需要大量的领域专门知识才能生成,涉及复杂的文本分析系统,还要一个健壮的语音字典(发音指南)。
Tacotron [12]是一个从字符序列生成幅度谱图的seq2seq架构 [13],它仅用输入数据训练出一个单一的神经网络,用于替换语言学和声学特征的生成模块,从而简化了传统语音合成的流水线。为了最终合成出幅度谱图,Tacotron使用Griffin-Lim [14] 算法估计相位,然后施加一个短时傅里叶逆变换。作者们指出,相比WaveNet中使用的方法,Griffin-Lim算法会产生特有的人工痕迹并且合成的语音质量较低,所以这只是一个临时方法,将来要替换成神经声码器。
在这篇论文中,我们描绘一个统一的完整的神经网络语音合成方法,它集前述两种方法之长:一个seq2seq的Tacotron风格的模型 [12] 用来生成梅尔声谱图,后接一个WaveNet声码器 [10, 15] 的修订版。模型直接使用归一化的字符序列和语音波形数据进行端到端的训练,学习合成的语音的自然度接近了真人语音。
Deep Voice 3 [11]描述了一个类似的方法,然而,不同于我们的系统,它的语音自然度还不能与人类语音匹敌。Char2Wav [16]提出了另外一个类似的方法,也使用神经声码器进行端到端的TTS学习,但它使用与我们不同的中间特征表达(传统的声码器特征),并且他们的模型架构与我们迥然不同。
2. 模型架构
我们提出的系统由两部分组成,如Fig.1所示:
(1)一个引入注意力机制(attention)的基于循环seq2seq的特征预测网络,用于从输入的字符序列预测梅尔频谱的帧序列;
(2)一个WaveNet网络的修订版,用于基于预测的梅尔频谱帧序列来生成时域波形样本。
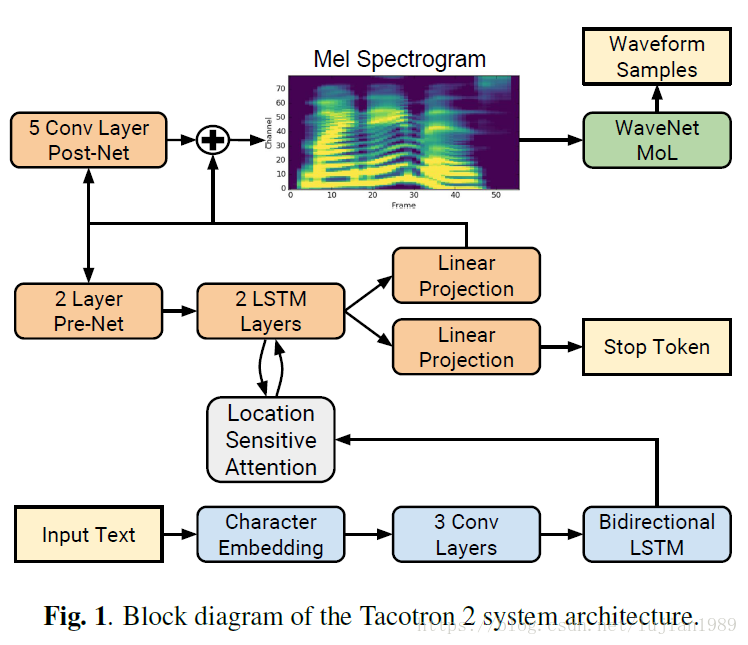
2.1 中间特征表达
在这项研究中,我们使用低层次的声学表征:梅尔频率声谱图,来衔接系统的两个部分。梅尔声谱图通过对时域波形进行计算很容易得到,使用这样一个表征,为我们独立训练两部分组件提供了可能。梅尔频谱比波形样本更平滑,并且由于其每一帧都是对相位不变的,所以更容易用平方误差损失进行训练。
梅尔频率声谱图与线性频率声谱图,即短时傅里叶变换的振幅是相关的。从对人类听觉系统的响应测试中得到启发,梅尔频谱是对短时傅里叶变换的频率轴施加一个非线性变换,用较少的维度对频率范围进行压缩变换得到的。这个与听觉系统类似的频率刻度方法,会强调语音的低频细节,低频细节对语音的可理解度非常关键,同时淡化高频细节,而高频部分通常被磨擦声和其他爆裂噪声所主导,因此基本上在高保真处理中不需要对高频部分进行建模。正是由于具有这样的属性,基于梅尔刻度的特征表达在过去几十年一直广泛应用于语音识别中。
线性声谱图抛弃了相位信息(因此是有损的),而像Griffin-Lim [14] 这样的算法可以对抛弃的相位信息进行估计,用一个短时傅里叶逆变换就可以把线性声谱图转换成时域波形。梅尔声谱图抛弃的信息更多,因此对逆向波形合成任务提出了挑战。但是,对比WaveNet中使用的语言学和声学特征,梅尔声谱图更简单,是音频信号的更低层次的声学表征,因此使用类似WaveNet的模型构造神经声码器时,在梅尔声谱图上训练语音合成应该更直截了当。我们将会展示用WaveNet架构的修订版从梅尔声谱图可以生成高质量的音频。