摘要
最近开发的WaveNet结构是现实语音合成中最新的技术,一直被认为是更接近于自然声音。然而,因为wavenet依赖于依次生成音频中的每一个样本点,那么就不适合现在这种强大的并行计算机,因此,不适用与在生产环境部署。本文介绍了概率密度蒸馏法,可以从训练好的wavenet上训练一个新的并行前馈网络,并且在质量上没有显著差异。这样的系统可以实现20倍实时的高保真语音合成,已经在谷歌助手中使用,并且支持英语和日语。
1. 引言
最近,深度学习在语音识别,图像识别和机器翻译等领域都发挥出色,最近发表的wavenet代表着最先进的语音合成技术,并且显著的缩小了与人类语音的差距,但是它合成的速度限制了在生产环境的应用,在本文中,提出了一个新算法将wavenet提取到一个前馈神经网络中,它可以高效的合成同样高质量的语音,并应用与数百万用户。
wavenet是一个深度自回归生成模型,在文字,图像,手写,语音和音乐合成上都有很大的成功。wavenet对原始音频信号的生成使用了非常极限的自回归,每秒要生成24000个点,这种高分辨率的网络在训练中是没有问题的,因为可以使用原始的音频作为输入,基于卷积结构可以并行处理,但是在生成时需要上一个生成的点作为下一个的输入,那么就不可能并行处理。
逆自回归流(IAF)提出了一种相对于深度自回归模型的对偶公式,它可以在顺序并且缓慢的似然估计推理的同时,实现并行采样。这个文章的目的是结合两个模型最好的特征:最有效的训练WaveNet和有效的IAF采样。我们以一个新型的神经网络蒸馏算法作为他们相连的桥梁,参考于概率密度蒸馏算法。使用一个训练好的wavenet作为前馈IAF模型的教师。
下一节描述原始的WaveNet模型,而第三节和第四节详细定义WaveNet的新的并行版本以及用于在它们之间传递知识的蒸馏过程。第5部分然后给出实验结果,表明并行相对于原始WaveNet在感知质量方面没有损失,并且继续优于以前的基准。我们还提出了定时生成样本,演示了超过1000×加速相对于原始WaveNet
2. WaveNet
自回归模型模拟了高维数据的条件分布基于概率链规则,生成联合分布的过程。
其中 是x的第 t 个变量,
是自回归模型的参数。以 所有第 t 个之前的 x 作为输入,并输出
作为输出的条件分布。
WaveNet是一个卷积自回归模型,它经过一次前向传播产生了所有 ,通过使用因果或掩膜卷积。每一个因果卷积层都可以对输入进行并行处理,在训练中比RNN快很多,因为RNN只能按顺序更新。但是在生成的时候,因为当我们想要生成
时,
必须已经生成结束,所以它也需要顺序合成。由于这种性质,所以实时合成对于自回归系统是有挑战性的,采样速度虽然在离线系统中不重要,但是在实时系统中是必不可少的。对此我们开发了一种实时的wavenet,但是它用了很小的网络,导致质量严重下降。
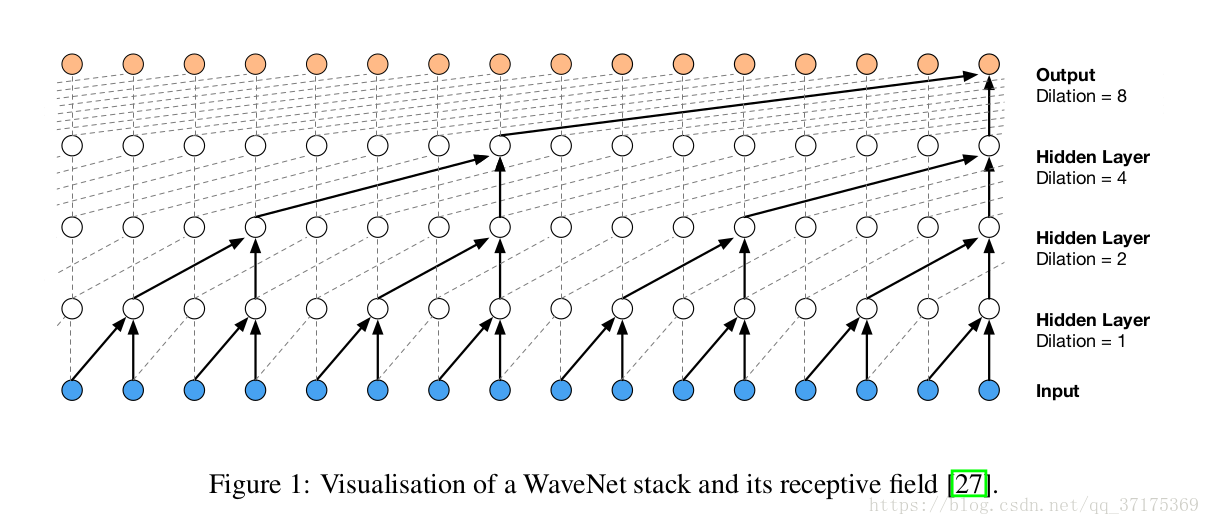
原始音频数据通常是非常高维的(例如 16khz的音频每秒都有16000个采样点) ,并且在跨越数千的采样时间点上包含非常复杂、分层的结构,比如语言中的词和音乐中的旋律。对它建模需要很深层的卷积结构,才能保证足够宽的感受野。wavenet避免了这个问题,它使用扩张因果卷积,使感受野随着层数的加深呈指数增长。
wavenet使用了门控激活单元和某论文中引入的简单机制来把语言学特征和分类标签引入模型中(这个某论文还是值得看看的。原文中有连接)
其中 * 表示卷积操作, 表示元素的乘法,
是一个 logistic sigmod 方程,c 代表了额外的状态参数,i 是层数的序号,f 代表filter , g 代表了 gate,W 和 V是可训练的权重,案例中的 c 编码了空间和顺序的信息(例如语言学特征的序列),两个矩阵被卷积替代。
2.1 高保真WaveNet
为此我们对基本的wavenet模型做了两项优化,来提高音频的质量。区别于之前的wavenet,我们用16bit的音频(65536位深)替代了8bit的音频(256位深)。因为训练65536个分类的分布是非常昂贵的,我们替换了采样模型,使用了离散化混合逻辑斯蒂分布来模拟模型。然后将16khz的采样率提升到24khz,它需要wavenet有更高的感受野,所以我们将扩张卷积层的扩张倍数从2提升到3,其他替代的方法包括提升层数,或者增加扩张阶段。
3 Parallel WaveNet
虽然wavenet的卷积结构可以实现快速,并行的训练,但是生成仍然要保证顺序,所以很慢。因此我们寻找一个替代的,可以快速并行生成音频的模型。
逆自回归流是使用了潜变量的随机生成模型目的是可以并行的生成高维可观测样本的所有元素。IAF是一种特殊的归一化流,它将多元分布p(x) 模拟为一个简单分布p(z)的可逆非线性变换(如同向高斯分布),所获得的随机变量 x = f(x)有一个对数概率:
是函数 f 的雅克比行列式,通常选用一个可逆的或者行列式比较好算的函数作为变换函数 f 。 IAF中,
决定于
为了使
这个变换有一个三角雅可比矩阵,随意行列式比较容易计算。
首先,一个随机采样被一个logistic(0, I)的 z 模拟。(公式实在写不动了。自行参照parallel wavenet论文吧)
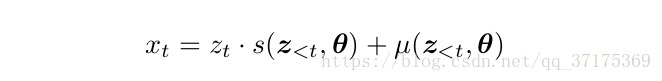
网络的输出分布是一个 x 作为样本,包括μ和s,因此,x对于z的条件概率也由μ个s决定

虽然μ和s可以是任何自回归模型,但是我们使用与原始wavenet相同的自回归模型,如果IAF和自回归模型共用相同的输出分布方式,那么数学上他们就应该可以模拟相同的多元分布。然而,在实验中他们是不同的(详见附录 A.2) 。为了输出正确的 t 时刻的概率分布 xt ,逆自回归流会预测所有之前的时间点的概率分布x 1 --> x t-1 , 基于噪声 z ,所以允许并行的生成所有的 xt
通常,归一化流需要反复的迭代,来将无关的噪声转化为结构化的样本。在下一次的合成中将本次的输出作为输入。这对IAF来说不那么重要因为它会在一次流程中对潜变量进行自回归。尽管如此,我们发现4个迭代流(我们只是将4个网络简单堆叠)确实的提高了质量。最终的结构中,权重在各流中不共享。
第一个网络将无条件的logistic白噪声作为输入,x 0 = z ,然后将每层网络的输出作为下一层的输入
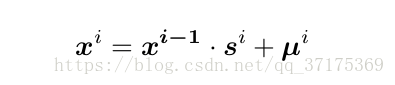
因为我们在所有流中使用了相同的排序,所以最终的分布是μ和s的逻辑分布
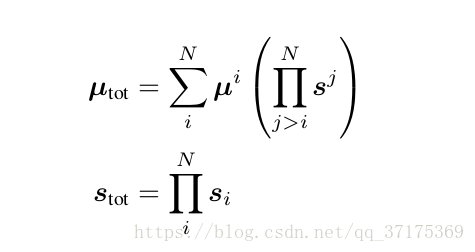
其中N是流的序号,为了简单,省去了 t 和 z 的逻辑关系
4 概率密度蒸馏
并行的训练wavenet的极大似然是不切实际的,因为推理过程中计算对数似然是需要顺序进行并且非常缓慢的。因此我们介绍了一个新形式的网络蒸馏模型,使用了一个已经训练好的wavenet作为teacher,和一个parallel wavenet作为student来实现高效的学习,为了强调我们使用了归一化模型,我们将这个过程成为概率密度蒸馏(区别与概率密度估计)。基本的思路是让学生网络去模拟教师网络生成的概率分布,这个概率分布式是由学生网络自己生成,然后将生成的样本经过教师网络处理的。
我们以ps(x)代表学生网络的概率。pt(x)作为教师网络的概率,用这个公式计算了概率米的蒸馏的损失:

Dkl是相对熵,H(ps,pt)是ps和pt的交叉熵,H(ps)是学生网络概率分布的熵。当KL散度到0的时候,学生网络完全找回了教师网络的分布。
熵项(在以前的蒸馏目标[11]中没有出现)是至关重要的,因为它防止学生的分布崩溃到教师的模式(这与直觉相反,没有产生好的样本-参见附录部分A.1)。关键地,如我们将看到的,估计这种损失的导数所需的所有操作(从p S(x)取样、评估p T(x)和评估H(P S))都可以有效地执行。(这段完全不懂,直接机翻,附上原文 The entropy term (which is not present in previous distillation objectives [11]) is vital in that it prevents the student’s distribution from collapsing to the mode of the teacher (which, counter-intuitively, does not yield a good sample—see Appendix section A.1). Crucially, all the operations required to estimate derivatives for this loss (sampling from p S (x), evaluating p T (x), and evaluating H(P S )) can be performed efficiently, as we will see.)
值得注意的是这与GAN模型有一些相似,学生网络充当了生成器的角色,而教师网络充当了鉴别器的角色。然而,学生并不是试图以敌对的方式愚弄老师;相反,他们是在合作,通过尝试模拟老师的概率分布。此外,老师在训练中是保持不变的,而不会与学生一起训练,这样两个模型都能得到归一化分布。
最近[9 ]提出了一种训练前馈神经网络的相关思想。他们的方法是基于调节前馈解码器的生育力值,这需要外部对准系统的监督。训练过程还包括创建额外的数据集以及微调。在推理过程中,他们的模型依赖于自动回归模型的重新评分。

图2:一个预训练的teacher会对student生成的样本进行评分。学生需要在训练中,最小化与教师模型的KL散度,最大化它自己样本经过教师网络处理后的对数似然,并且最大化自己样本的熵。
首先,观察方程6中的H ps 可以被如下函数重写
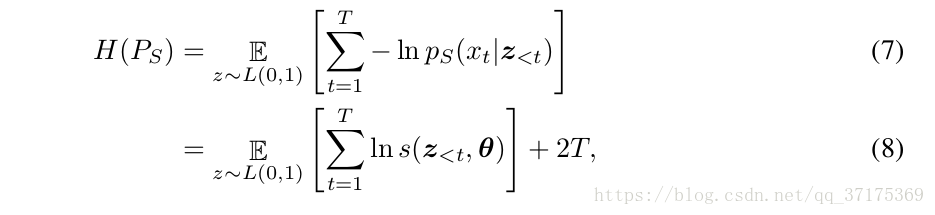
x = g(z) 并且 zt 是一个独立的logistic分布。等式8是因为logistic分布的熵,L (μ, s) 是 ln s + 2,因此我们可以直接计算这些项,而不用生成x 。然而,交叉熵需要显示的依赖于 x = g(z) 所以需要拿到学生生成的样本去估算。
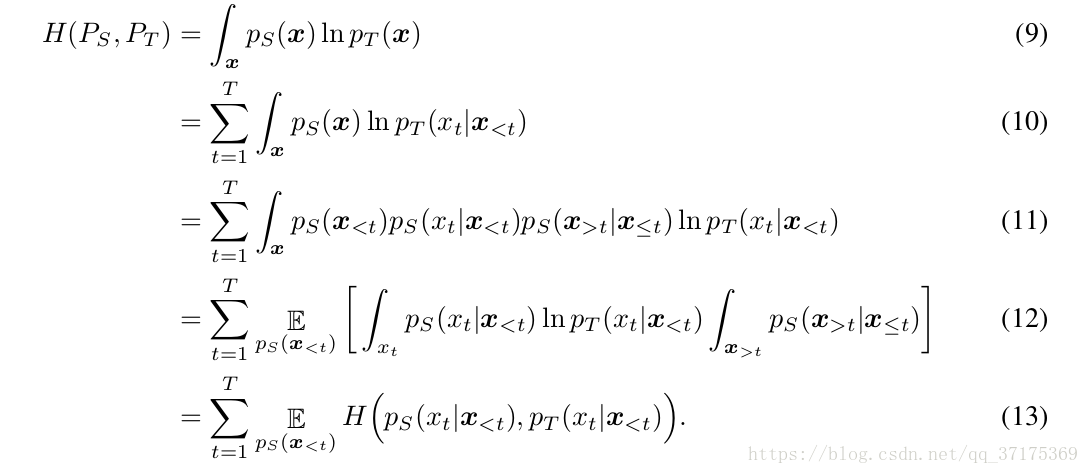
算交叉熵比算学生网络的概率分布高效很多,这种没有偏置项的估算会比原始的算法9,产生相对来说更小的方差。
因为teacher的输出分布是mol分布,所以损失项对于 x t 和 x <t都是可微的
4.1 附加损失项
只使用概率密度蒸馏可能不足以让学生网络去生成高质量的音频流。因此,我们同样介绍一些附加的损失函数,去知道学生网络可以更接近于所需的概率空间。
power loss 功率损失
我们第一个提出的附加损失是功率损失,它确保了在不同的频率段内,他的功率都是平均的,类似于人类说话的声音。power loss有助于降低学生网络的损坏,在高熵的教师模型中。比如窃窃私语这种情况。

其中 y 是数据,c 是condition,函数是STFT,我们发现STFT的功率可以先平均,再计算欧氏距离,这意味着不同频率之间的平均功率是很重要的。
Perceptual loss 感知损失
在公式14的功率损失中,可以用神经网络替代STFT去保存信号的感知损失,而不是总能量。在我们的训练中使用了一个类似于wavenet的分类器来预测原声音频的发音。因为这种分类器提取了有关发音的高层特征,所以这个损失项会惩罚错误的发音。在机器视觉的风格化中,使用了相似的损失项。或者超分辨率中使用的更好的感知重建损失。我们使用了两种不同的感知损失方法,其中风格损失(在Gram矩阵之间的欧几里德距离)更好一些。
Contrastive loss 对比损失
最后我们同样介绍一个对比蒸馏损失:
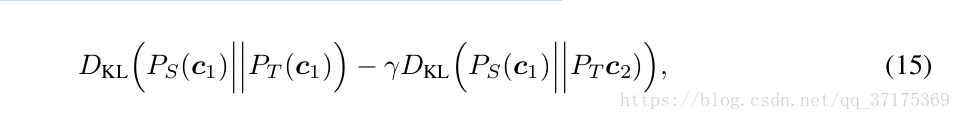
它同时最小化了teacher和student间的KL散度,当他们都是用了相同的local condition比如语言学特征,speaker id等。我们计算了两次损失,一次是使用相同的local condition,一次是使用随机local condition,对比项r 的权重设置为0.3,这个对比损失惩罚了一些没有注重local condition而生成的波形。
抽取一些5 实验中相对重要的部分
仅KL散度是不够的,但是KL散读 + power loss 就已经足够生成高质量的音频了,增加感知损失会带来微小但明显的改善,而对比损失不会提高评分,但会减小噪音。
附录
A.1 关于MAP估算的争论
在本节中,我们对 MAP算法提出异议,之前也有作者提出了相似的异议
在第4节中定义了蒸馏的最小化teacher和student之间的kl散度,相反我们只计算交叉熵,让学生和教师生成的样本更接近。这样会导致 MAP 估计。相反的,进行MAP估计产生的样本并不会像想象中一样与teacher相似,事实上,它几乎完全沉默,即使使用了语言学特征作为local condition,。这种影响不是由于教师的敌对行为,而是教师估计了数据分布的基频。
作为一个示例,考虑一个简单的情况,其中我们有来自白噪声源的音频:每个时间步的分布是N(0,1),而不管先前时间步的样本。白噪声有一个非常具体的和可感知的声音:持续的嘶嘶声。根据MAP估计数据分布,因此,任何一个生成的与它匹配的模型,恢复到原始分布中,会变成全都是0,即完全沉默。更普遍的说,任何的高频分布都可能有无声,因此会产生特殊的情况,对于KL散度,最佳是恢复完整的教师分布,这明显不同于任何的随机样本。