本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: TM0831
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
页面分析
首先打开微信读书,往下拉之后可以看到有榜单推荐,而且显示总共有25个榜单,有的榜单只有几百本,有的榜单却有几万本书。 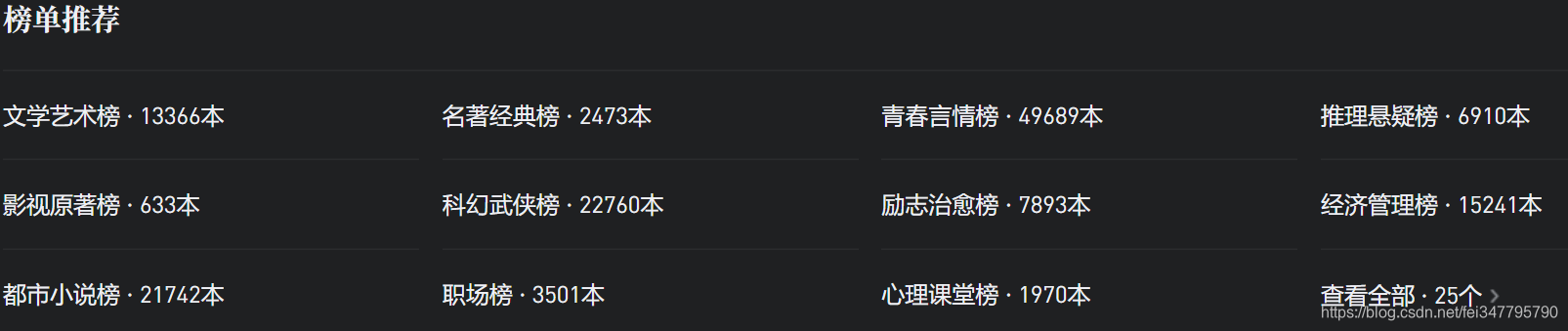 打开“文学艺术榜”,可以看到一页显示了20条书本信息,下拉之后很容易就能发现这些书本信息是通过 AJAX 来加载的。
打开“文学艺术榜”,可以看到一页显示了20条书本信息,下拉之后很容易就能发现这些书本信息是通过 AJAX 来加载的。
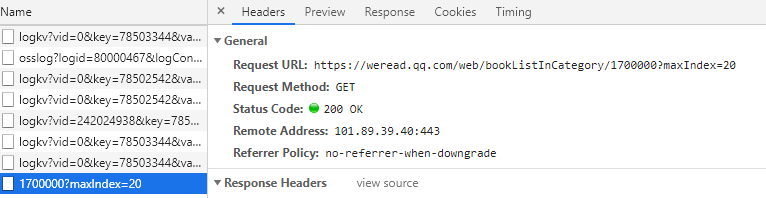
更关键的是,要获取这些书籍信息,只需要得到分类 ID 和参数 maxIndex。不过测试发现,每个分类只会返回50个页面的内容,也就是最多一千条书本信息。那么,如果只有这25个类别的榜单,能得到的数据还是有点少的,所以要怎么得到更多的数据呢?
细心的人可以发现右侧还能选择类别!如下图:
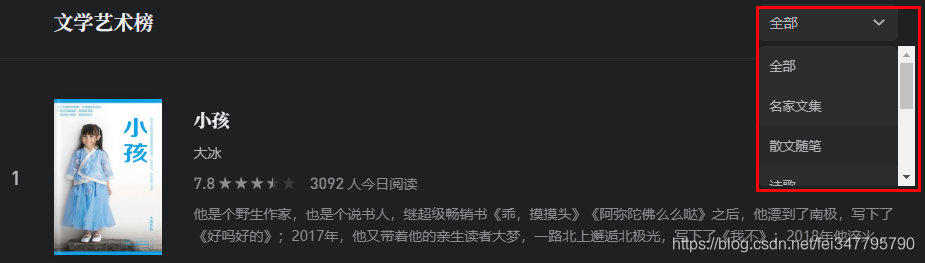
不过,查看这些元素发现里面是没有显示 URL 的,如下图:


但是这也不表示没有办法了,全局搜索一下就能找到了,如下图:
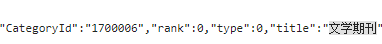
CategoryId 就是这个分类的 ID,也就是 URL 中“bookListInCategory/”后面的内容。至于 maxIndex,可以先设为0,然后发送请求得到这一分类的书本总数“totalCount”,然后根据这个书本总数是否超过一千来设置页数,就能得到这一分类下能够爬取到的所有 URL 了。 爬取步骤 前面经过分析已经知道只要拿到书本分类 ID,就能发送请求得到书本总数,也就能构造该分类下的所有页面的 URL 了。那要怎么得到所有分类呢?前面全局搜索的时候已经搜到了书本分类的 CategoryId 等信息,如下图:
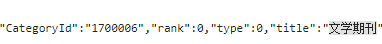
所以只需先请求页面然后用正则匹配 CategoryId 就行了!然后对每个分类发送一次请求,用于获取书本总数,并构造这一分类下的所有 URL。这一部分代码如下:
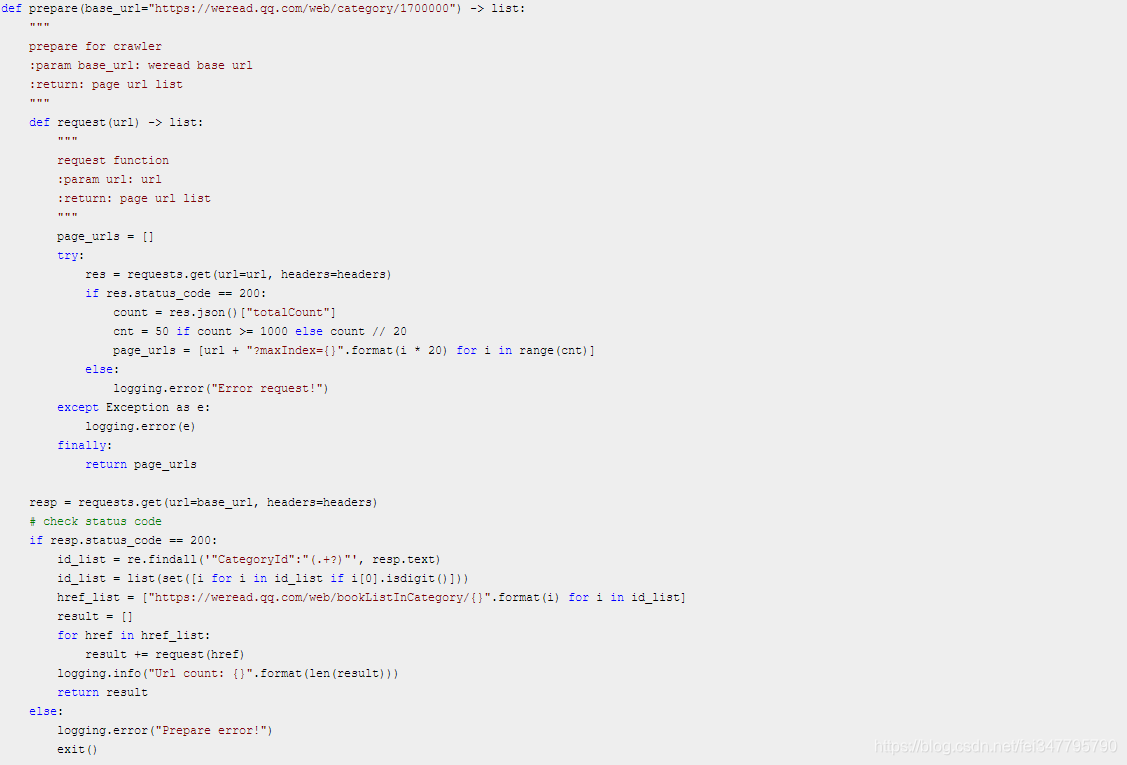
进行到这一步,后面就很简单了,就是获取请求结果并解析即可。程序运行时打印输出如下:
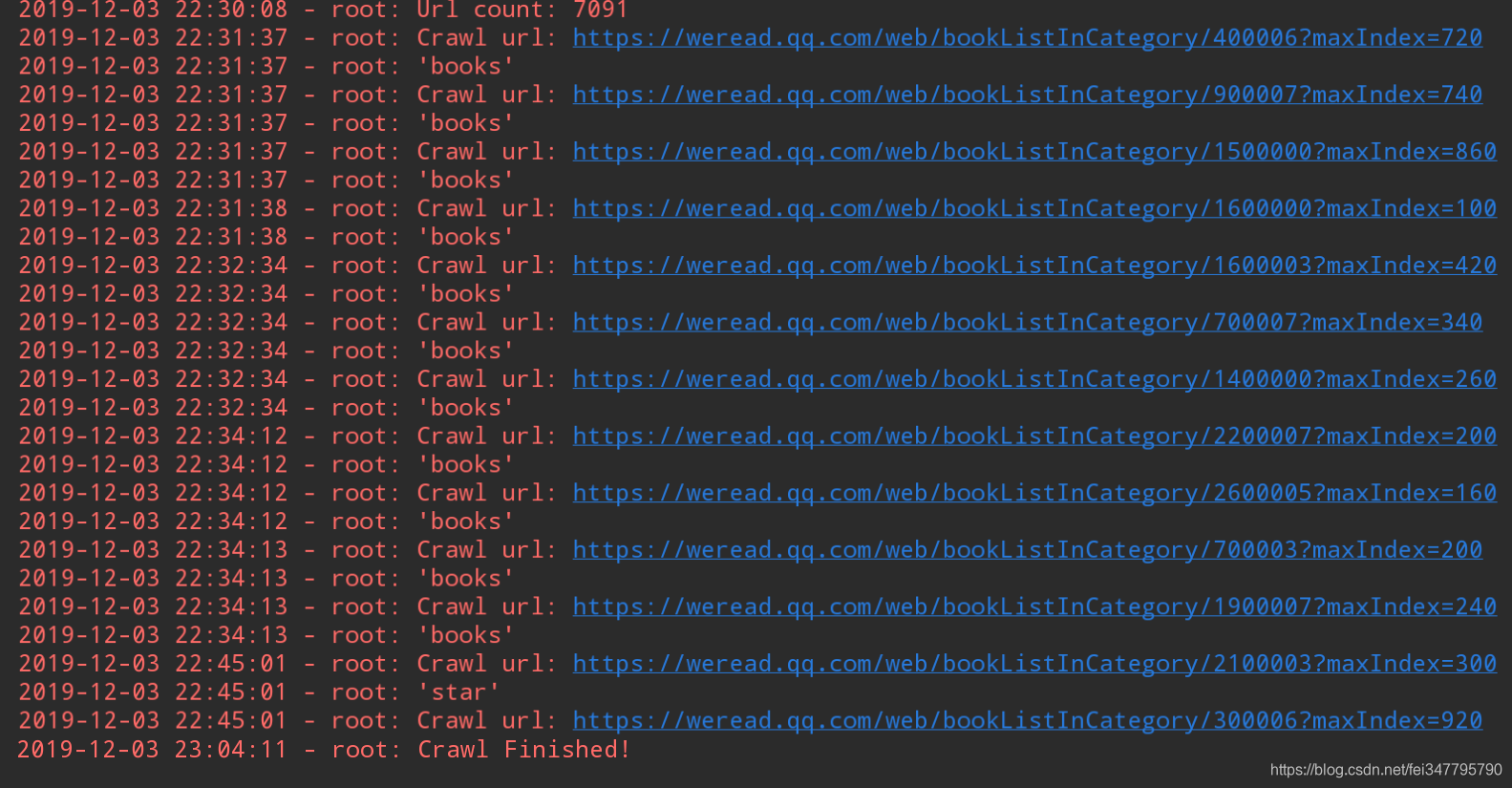
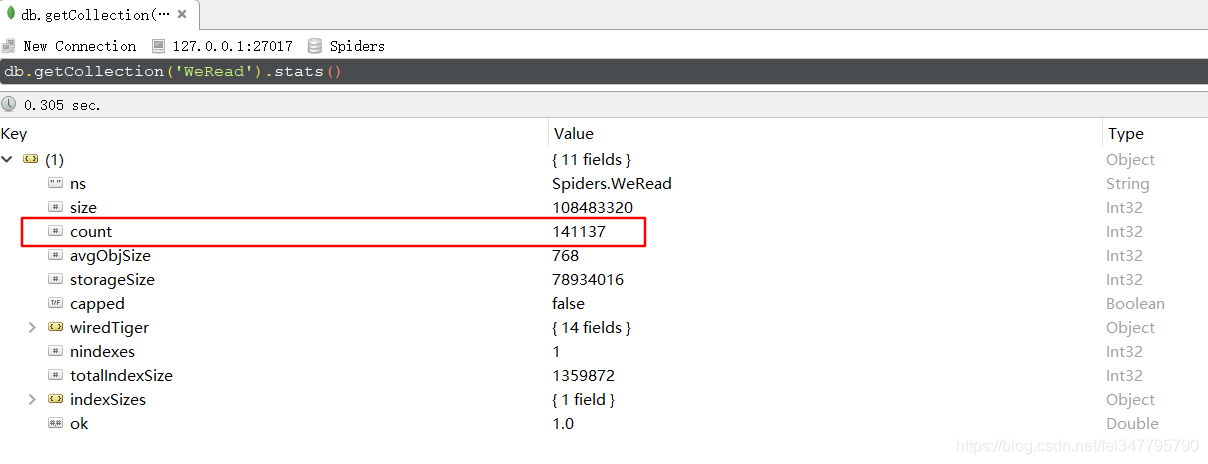
可以看到总链接数有7091条,那么爬到的书本信息有多少条呢?因为我用的是 MongoDB 保存的,所以打开 Robot3T 查看,总共有141137条,结果如下图:
绘图分析
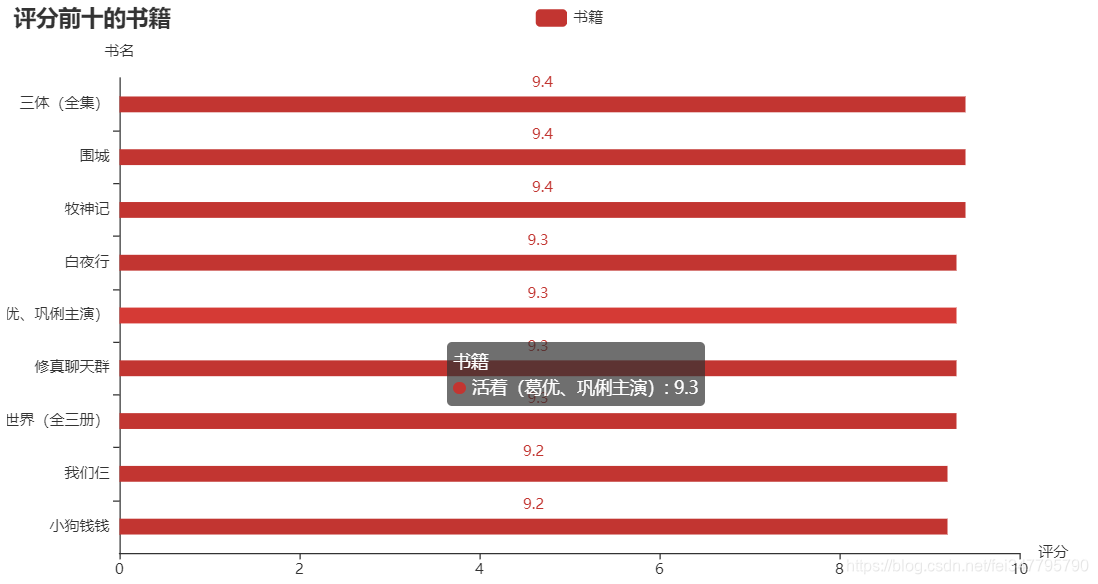
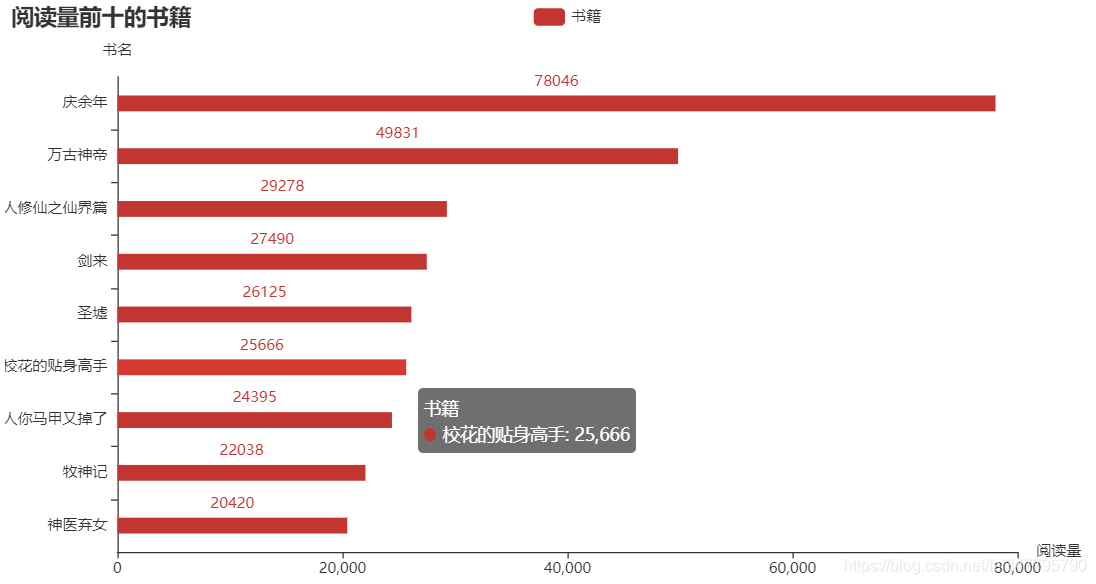
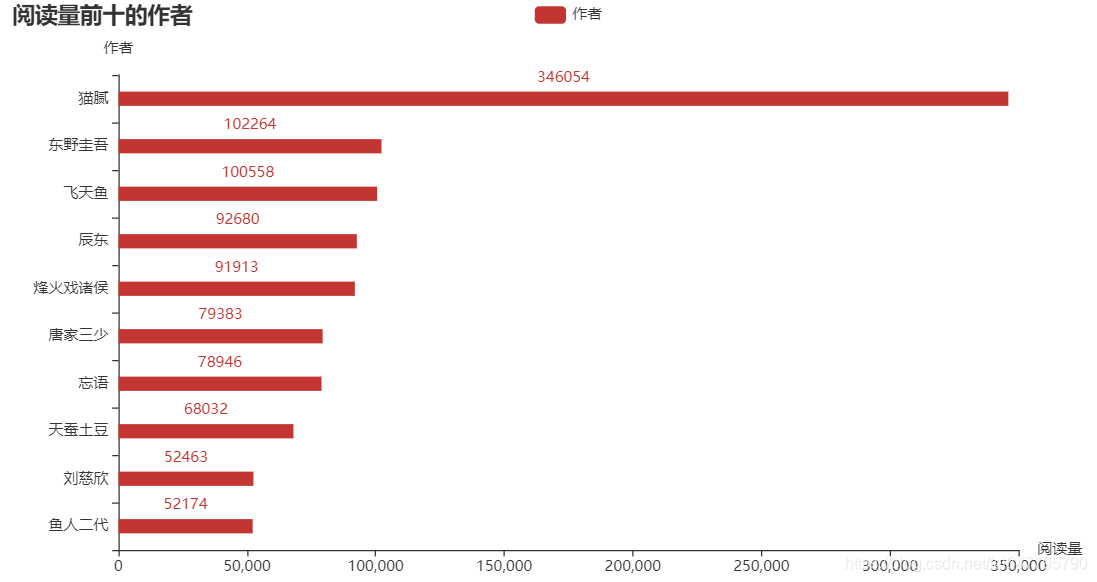
熟悉 Python 的都知道,matplotlib 是 Python 中用的最多的 2D 图形绘图库。不过我在这推荐一个好用的第三方库:pyecharts,这是一个用于生成 Echarts 图表的类库,生成的图表更加精巧,可视化效果更好,不过需要注意的是 pyecharts 的0.5版本和1.0版本使用方法是不同的。下面就是使用这个库生成的横向柱状图了,分别表示评分前十的书籍、阅读量前十的书籍和总阅读量前十的作者: