自己做的第一个爬虫程序,记录一下错误。
如果你想学习,请一点一点看下去,我把自己犯过的错误也列了出来,希望对你有所帮助。
如果你想直接得到源码,请滑到到最后,源码在最后!
如果文章对你有所帮助,请点个赞再走!
github地址:github地址
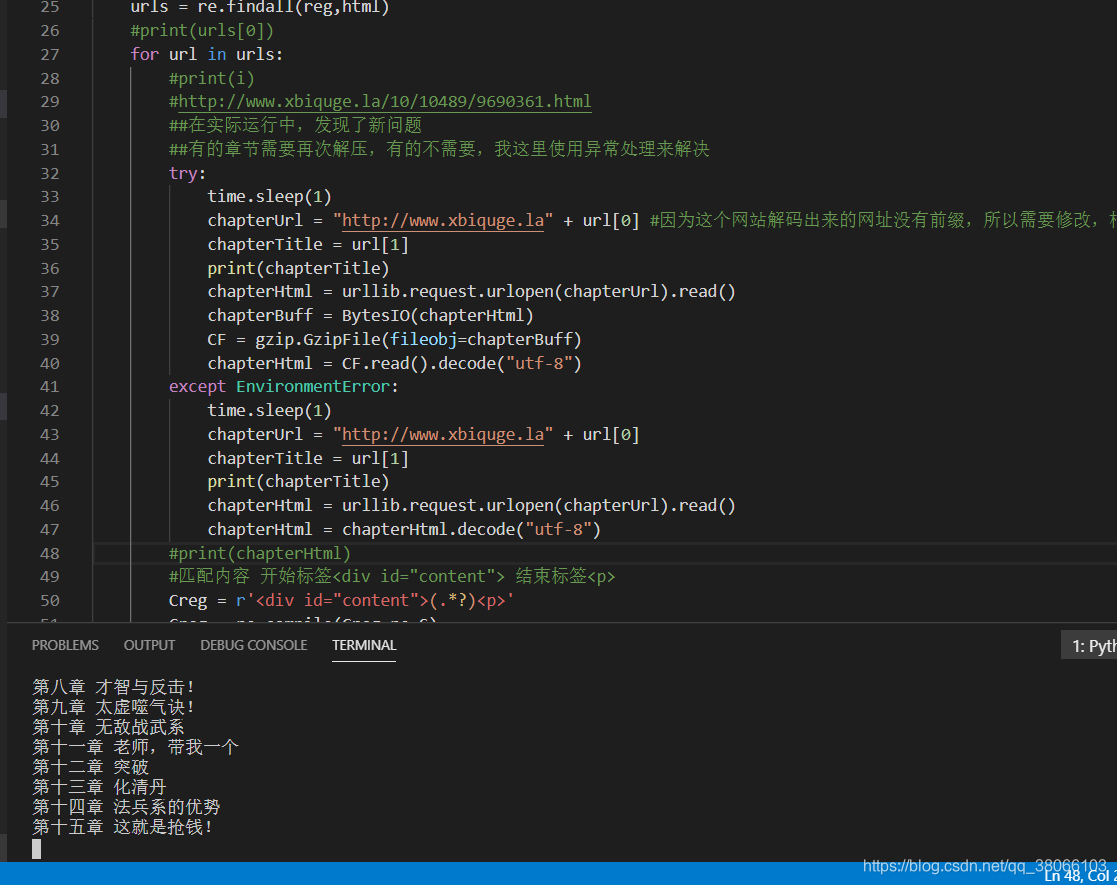
一、 运行中的效果图
二、代码详解
1.导入常用的包
import re
import urllib.request
2.创建函数,爬取网站
def GetNovel():
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
print(html)
这里爬取的是一个小说网站,通过urllib的request,打开网页链接。
我们输出一下网址,看看是否可以请得到数据:
import re
import urllib.request
def GetNovel():
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
print(html)
GetNovel()
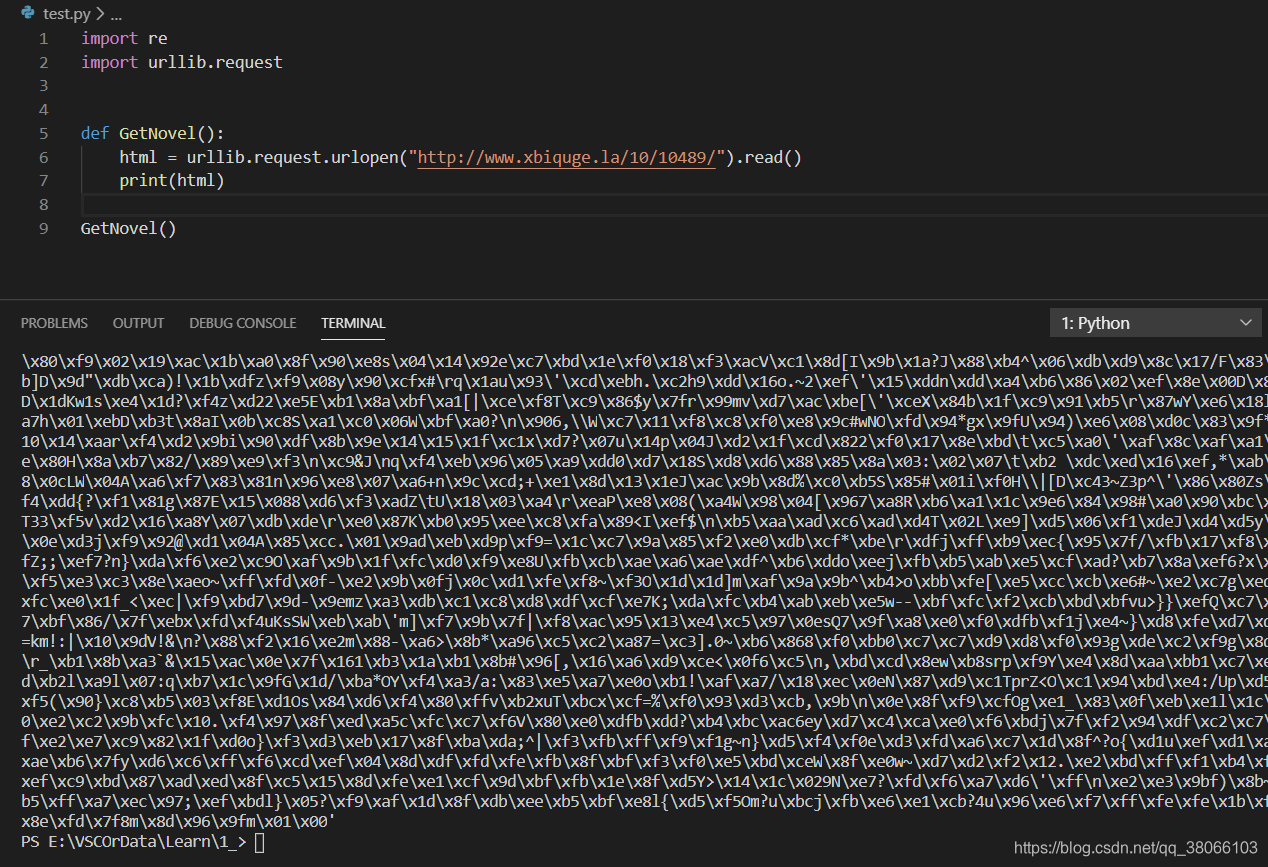
可以看到,运行之后的结果是一堆乱码,我当时以为是utf-8的格式不对,所以再次声明了一下读取的格式,结果出现了以下错误:
*UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x8b in position 1: invalid start byte
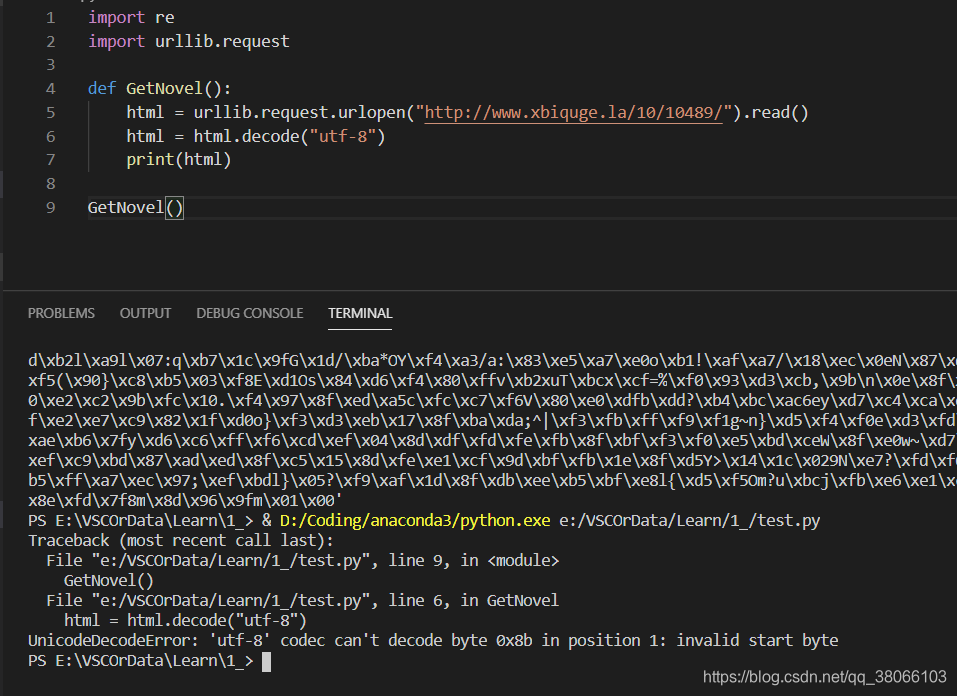
经百度发现,是还需要再次解码,才能得到原始网站。
于是修改代码,在此解压网址,需要在此导入两个包,from io import BytesIO 和
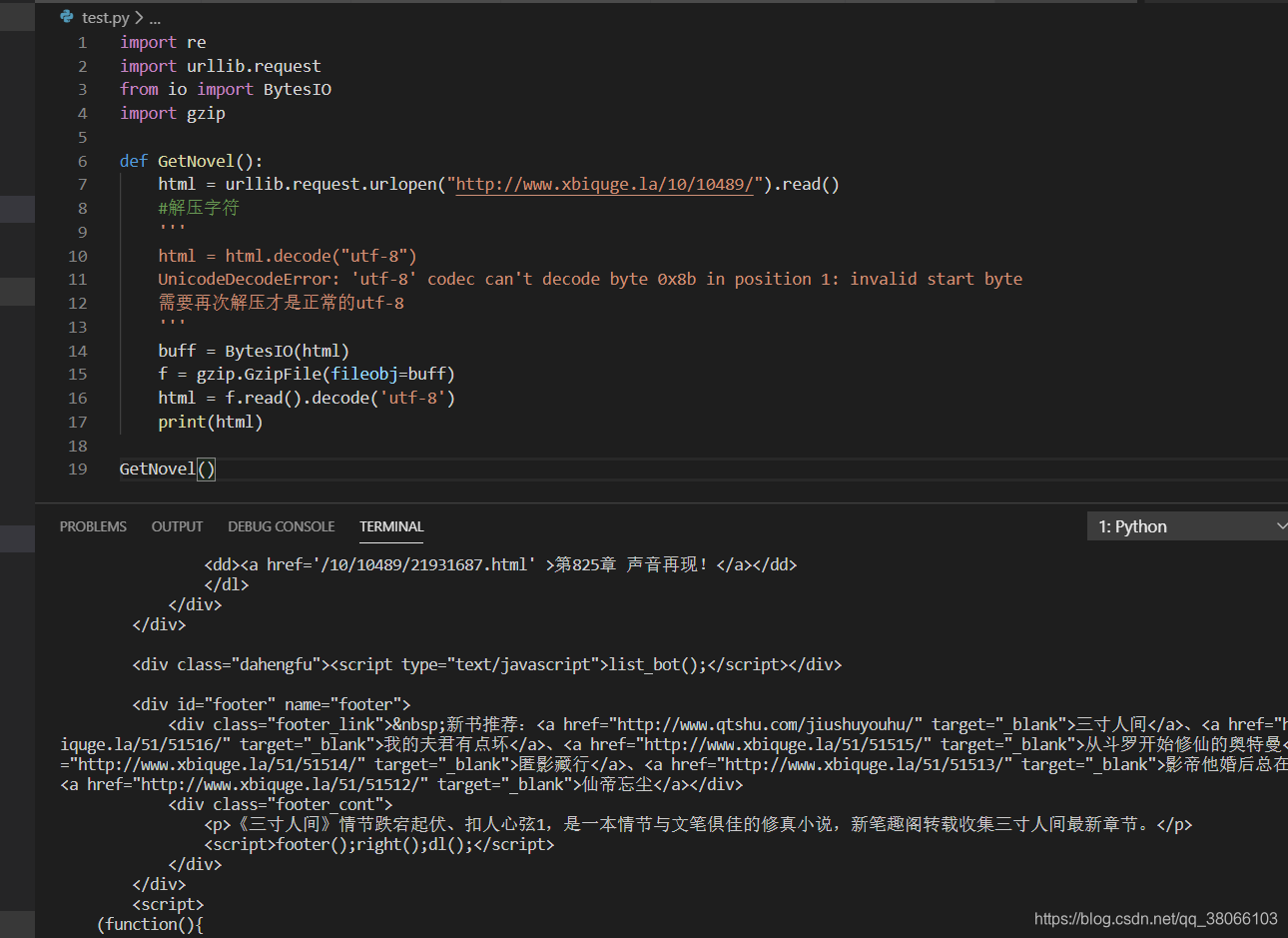
import gzip,再次输出可得到正常的网页:
import re
import urllib.request
from io import BytesIO
import gzip
def GetNovel():
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
#解压字符
'''
html = html.decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
需要再次解压才是正常的utf-8
'''
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8')
print(html)
GetNovel()
3.抓去章节目录
目前为止,网站网址已经得到,并且可以输出得到网站源码。之后就要开始抓取每一章节的目录,得到每一章节的超链接,才能读取到每一章节的内容。
打开网页源码,选取一个章节的超链接标签,作为框架。

选取一个章节目录唯一的难点就是正则表达式的匹配。
reg = r"<dd><a href='(.*?)' >(.*?)</a></dd>"
这里把不是相同的链接地址,用(.*?)的方式进行匹配,包括每一章节的超链接和每一章节的名称。
import re
import urllib.request
from io import BytesIO
import gzip
def GetNovel():
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
#解压字符
'''
html = html.decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
需要再次解压才是正常的utf-8
'''
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8')
#print(html)
#<dd><a href='/10/10489/9690361.html' >第六章 麻烦大了</a></dd>
#IndentationError: unindent does not match any outer indentation level 代码没有对齐
reg = r"<dd><a href='(.*?)' >(.*?)</a></dd>"
reg = re.compile(reg) #可添加可不添加,增加效率
urls = re.findall(reg,html)
GetNovel()
在这里中间还遇到过一次错误,是由于代码没有对齐报的错误,我顺便把报错代码记录了下来
#IndentationError: unindent does not match any outer indentation level
由于代码没有对齐的报错。
因为得到的urls是一个list对象,所以我们通过for循环遍历,得到列表中存储的数据:
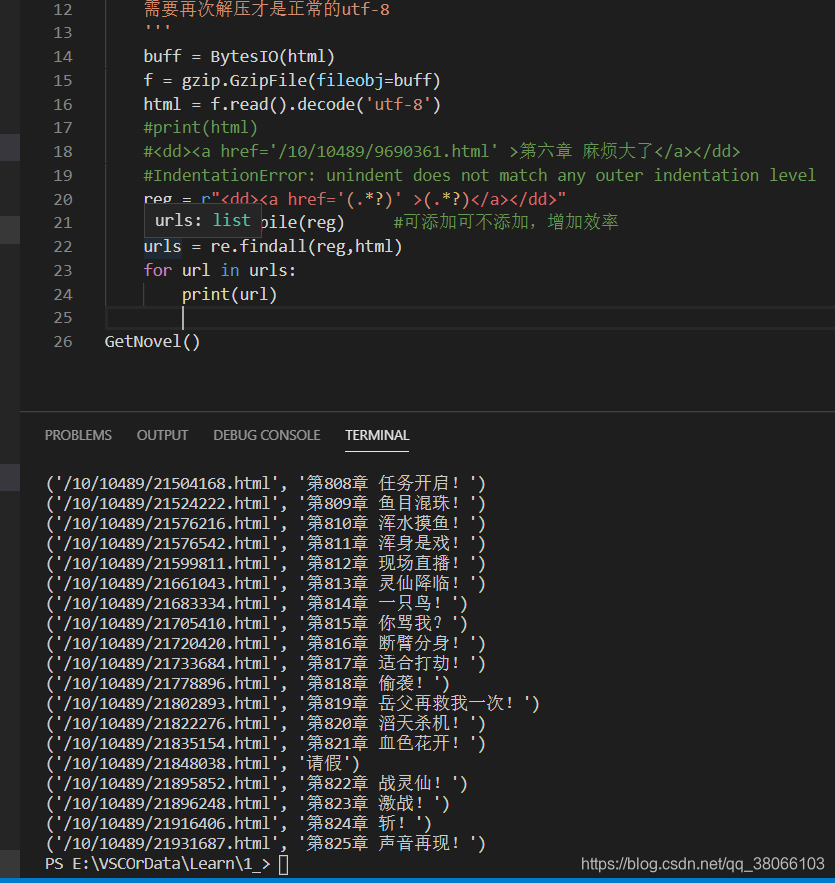
由上图可知:list中存储的数据是0位的章节超链接和1位的章节名称,但是可以看到,网站的超链接,并不能直接打开,缺少了网址的头,所以我们打开网站,截取出来一个完整的网址,再次拼接,即可得到能够打开的章节超链接。
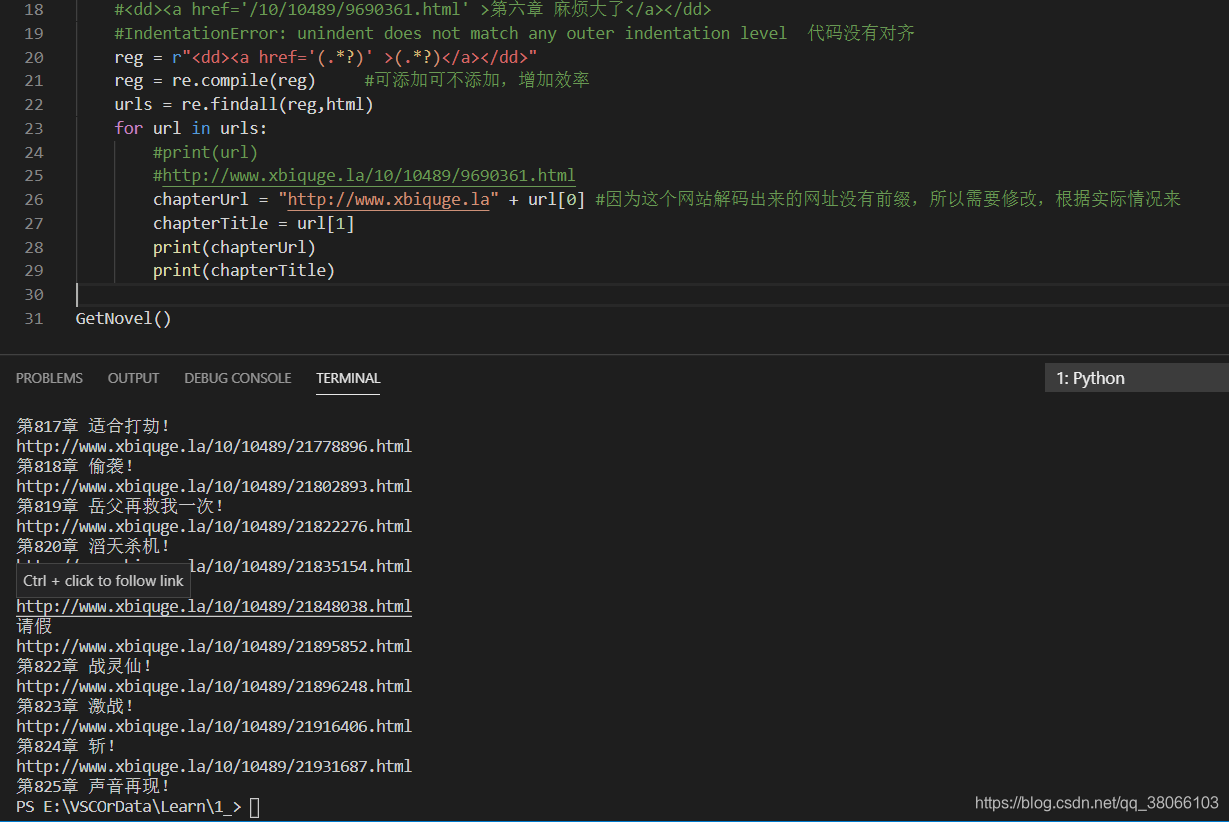
4.爬取章节内容(+处理错误)
通过第三步得到了章节的超链接,于是我们可以通过和之前获得网站源码的代码一样,获得各个章节的网站源码,需要注意的是,同样需要再次解压才可以:
import re
import urllib.request
from io import BytesIO
import gzip
def GetNovel():
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
#解压字符
'''
html = html.decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
需要再次解压才是正常的utf-8
'''
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8')
#print(html)
#<dd><a href='/10/10489/9690361.html' >第六章 麻烦大了</a></dd>
#IndentationError: unindent does not match any outer indentation level 代码没有对齐
reg = r"<dd><a href='(.*?)' >(.*?)</a></dd>"
reg = re.compile(reg) #可添加可不添加,增加效率
urls = re.findall(reg,html)
for url in urls:
#print(url)
#http://www.xbiquge.la/10/10489/9690361.html
chapterUrl = "http://www.xbiquge.la" + url[0] #因为这个网站解码出来的网址没有前缀,所以需要修改,根据实际情况来
chapterTitle = url[1]
#print(chapterUrl)
print(chapterTitle)
chapterHtml = urllib.request.urlopen(chapterUrl).read()
chapterBuff = BytesIO(chapterHtml)
CF = gzip.GzipFile(fileobj=chapterBuff)
chapterHtml = CF.read().decode("utf-8")
print(chapterHtml)
GetNovel()
下边是运行之后的结果:
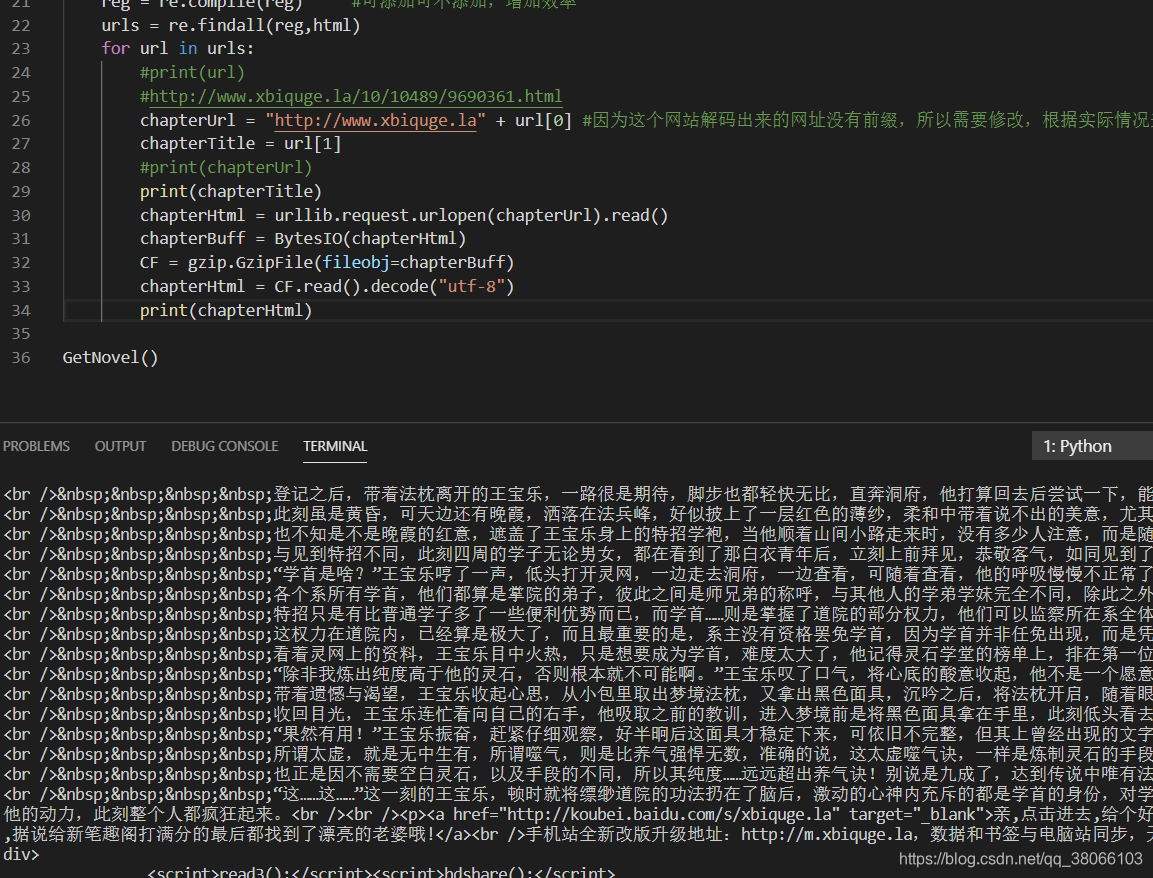
然而在实际运行中,却遇到了另一个问题:
urllib.error.HTTPError: HTTP Error 503: Service Temporarily Unavailable
由于访问服务器次数太多,导致了服务器拒绝访问。由于这是练习使用,没有使用ip代理池的办法解决此问题,而是通过限制访问速度来实现。
导入了包:import time ,通过time.sleep(1)的方法解决的。
在每次请求网页之前,加入
time.sleep(1)
然而在运行了十几次之后,发现了一个新的问题
OSError: Not a gzipped file (b’<!’)
问题原因竟然是这个章节不需要再次解压。真是坑!!
对这个问题,我通过异常处理来解决的,防止还有其他章节也有这种情况。
import re
import urllib.request
from io import BytesIO
import gzip
import time
def GetNovel():
time.sleep(1)
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
#解压字符
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8')
'''
html = html.decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
需要再次解压才是正常的utf-8
'''
#print(html)
#<dd><a href='/10/10489/9690361.html' >第六章 麻烦大了</a></dd>
#IndentationError: unindent does not match any outer indentation level 代码没有对齐
reg = r"<dd><a href='(.*?)' >(.*?)</a></dd>"
reg = re.compile(reg) #可添加可不添加,增加效率
urls = re.findall(reg,html)
#print(urls[0])
for url in urls:
#print(i)
#http://www.xbiquge.la/10/10489/9690361.html
##在实际运行中,发现了新问题
##有的章节需要再次解压,有的不需要,我这里使用异常处理来解决
try:
time.sleep(1)
chapterUrl = "http://www.xbiquge.la" + url[0] #因为这个网站解码出来的网址没有前缀,所以需要修改,根据实际情况来
chapterTitle = url[1]
print(chapterTitle)
chapterHtml = urllib.request.urlopen(chapterUrl).read()
chapterBuff = BytesIO(chapterHtml)
CF = gzip.GzipFile(fileobj=chapterBuff)
chapterHtml = CF.read().decode("utf-8")
except EnvironmentError:
time.sleep(1)
chapterUrl = "http://www.xbiquge.la" + url[0]
chapterTitle = url[1]
print(chapterTitle)
chapterHtml = urllib.request.urlopen(chapterUrl).read()
chapterHtml = chapterHtml.decode("utf-8")
#print(chapterHtml)
GetNovel()
5.获取正文内容
现在我们基本已经可以打开各章节的源码了,剩下的就是获取正文内容。我们打开网站源码可以发现,小说的正文内容,基本都是在两个标签之中。
开始标签

于是我们可以再次通过正则表达式,来匹配正文内容。
Creg = r'<div id="content">(.*?)<p>'
Creg = re.compile(Creg,re.S)
chapterContent = re.findall(Creg,chapterHtml)
但是我们还发现,在正文中,还有一些特殊的符号:
<br />
所以我们通过replace函数进行替换
content = content.replace(" ","") #把" "字符全都替换为""
content = content.replace("<br />","") #把"<br/>"字符全部替换为""
6.把正文内容保存下来
这里我们已经获得了小说的正文内容,但是只有保存本地才能观看,所以我们需要进行文件操作。我是直接通过文件写入的添加模式,保存到一个txt文件中。
for content in chapterContent:
content = content.replace(" ","") #把" "字符全都替换为""
content = content.replace("<br />","") #把"<br/>"字符全部替换为""
#print(content)
txt = open('test.txt','a')
txt = txt.write(chapterTitle + "\n" + content + "\n")
至此,一个小说爬取网站就结束了。如果有需要交流的请评论区留言!
三、项目源码
import re
import urllib.request
from io import BytesIO
import gzip
import time
def GetNovel():
time.sleep(1)
html = urllib.request.urlopen("http://www.xbiquge.la/10/10489/").read()
#解压字符
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
html = f.read().decode('utf-8')
'''
html = html.decode("utf-8")
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
需要再次解压才是正常的utf-8
'''
#print(html)
#<dd><a href='/10/10489/9690361.html' >第六章 麻烦大了</a></dd>
#IndentationError: unindent does not match any outer indentation level 代码没有对齐
reg = r"<dd><a href='(.*?)' >(.*?)</a></dd>"
reg = re.compile(reg) #可添加可不添加,增加效率
urls = re.findall(reg,html)
#print(urls[0])
for url in urls:
#print(i)
#http://www.xbiquge.la/10/10489/9690361.html
##在实际运行中,发现了新问题
##有的章节需要再次解压,有的不需要,我这里使用异常处理来解决
try:
time.sleep(1)
chapterUrl = "http://www.xbiquge.la" + url[0] #因为这个网站解码出来的网址没有前缀,所以需要修改,根据实际情况来
chapterTitle = url[1]
print(chapterTitle)
chapterHtml = urllib.request.urlopen(chapterUrl).read()
chapterBuff = BytesIO(chapterHtml)
CF = gzip.GzipFile(fileobj=chapterBuff)
chapterHtml = CF.read().decode("utf-8")
except EnvironmentError:
time.sleep(1)
chapterUrl = "http://www.xbiquge.la" + url[0]
chapterTitle = url[1]
print(chapterTitle)
chapterHtml = urllib.request.urlopen(chapterUrl).read()
chapterHtml = chapterHtml.decode("utf-8")
#print(chapterHtml)
#匹配内容 开始标签<div id="content"> 结束标签<p>
Creg = r'<div id="content">(.*?)<p>'
Creg = re.compile(Creg,re.S)
chapterContent = re.findall(Creg,chapterHtml)
for content in chapterContent:
content = content.replace(" ","") #把" "字符全都替换为""
content = content.replace("<br />","") #把"<br/>"字符全部替换为""
#print(content)
txt = open('test.txt','a')
txt = txt.write(chapterTitle + "\n" + content + "\n")
GetNovel()
