爬虫步骤回顾:
根据前两篇文章,我们理解了爬虫的各个过程,简单回顾下:
爬虫第一步:根据URL获取网页的HTML信息;
Python3中可以通过urllib.request或者requests进行网页爬取;(前两篇文章中我们已经见识到了)
urllib库是Python内置的,无需我们额外安装;
requests库是第三方库,需要我们自己安装;(在上一节中我们是通过PyCharm安装的)或参照《requests库中文教程》
最常用的就是get方法:requests.get();
该方法必须设置的一个参数就是url,目的是告诉get请求,我们的目标是谁,需要谁的信息;
URL可能是我们事先已知的或者是通过网页中抓取的链接获取的,针对这些URL进行过第一步之后,就要对HTML信息进行解析了;
爬虫第二步:解析HTML信息;
以爬取小说举例,提取正文的方法很多:正则表达式、Xpath、Beautiful Soup等;(Xpath 我们在学习Selenium的过程中曾经学习过 用处多多啊)
我们使用简单易用的Beautiful Soup:
仍然通过PyCharm来安装,当然也可以使用命令行进行初始化;具体过程可以参照之前的文章;
有关bs的使用参考《Beautiful Soup 中文文档》;
爬虫第三步:将需要的信息进行输出保存;
可已经爬取到的小说内容,写入txt文件中,便于查阅;
网络小说爬取:
某一篇内容:
我们尝试爬取《元尊》某一章节的内容;
我们通过requests获取html内容,编码如下:(有关header如何获取请参考《第一个python爬虫示例——爬取天气信息》)
#!/usr/bin/python
# -*- coding:utf-8 -*-
import requests #用来抓取网页的html源码
import random #取随机数
import time #时间相关操作
from bs4 import BeautifulSoup #用于代替正则式 取源码中相应标签中的内容
def get_content(url, data = None):
#设置headers是为了模拟浏览器访问 否则的话可能会被拒绝 可通过浏览器获取
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'br, gzip, deflate',
'Accept-Language':'zh-cn',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1 Safari/605.1.15'
}
#设置一个超时时间 取随机数 是为了防止网站被认定为爬虫
timeout = random.choice(range(80,180))
while True:
try:
req = requests.get(url=url, headers = header, timeout = timeout)
break
except Exception as e:
print('3' + e)
time.sleep(random.choice(range(8, 15)))
return req.text
if __name__ == '__main__':
url = 'http://www.biqukan.com/0_790/21725523.html'
html = get_content(url)
print('天尊:' + html)运行代码,结果如下:

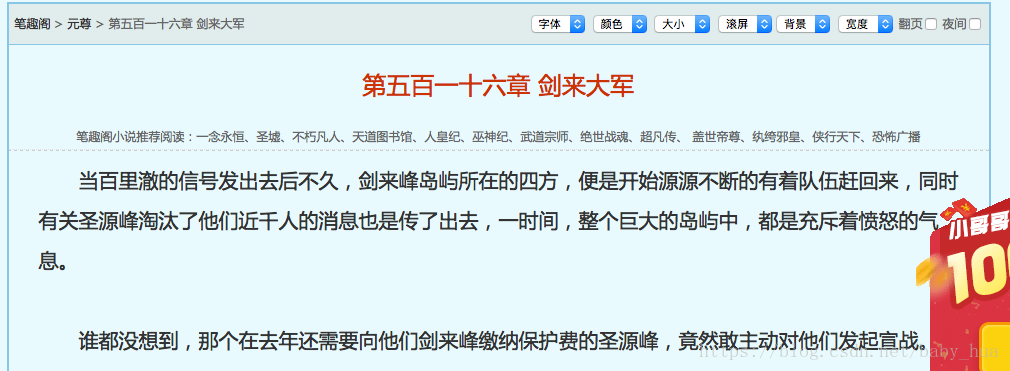
获取html内容很简单,但是其中有很多我们不关注的信息,我们只需要的是我们感兴趣的内容:把正文从html标签中提取出来;
编码如下:
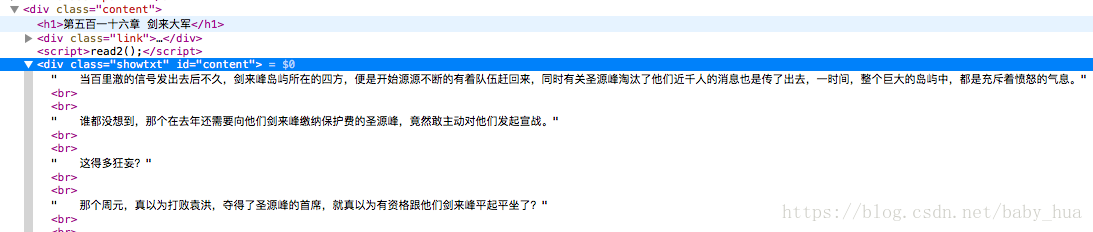
def get_data(html):
bf = BeautifulSoup(html,'html.parser')
texts = bf.find_all('div',{'class':'showtxt'})
print(texts)
if __name__ == '__main__':
url = 'http://www.biqukan.com/0_790/21725523.html'
html = get_content(url)
get_data(html)注意:用PyCharm来运行脚本可能会只显示一小部分的内容,这是因为Pycharm认为返回数据太多了,省略显示了;
但是获取到的数据 是div标签下的内容,我们还需要出掉多余的标签、空格或者是换行;

我们修改代码,取第一个标签的文本内容,这样做会过滤掉标签:
def get_data(html):
bf = BeautifulSoup(html,'html.parser')
texts = bf.find_all('div',{'class':'showtxt','id':'content'})
print(texts[0].text)运行结果如下:

我们继续将连续的空白格替换为换行回车:
def get_data(html):
bf = BeautifulSoup(html,'html.parser')
texts = bf.find_all('div',{'class':'showtxt','id':'content'})
text = texts[0].text.replace('\xa0'*7,'\n\n')#\xa0表示连续的空白格
print(text)这里如果替换连续的8个会将小说的每段的第一个文字截掉,所以这里我只替换了7个:

……
这样我们就匹配到了所有的正文内容;
整部小说内容:
如果是下载整部小说的话,就需要获取每个章节的链接:小说目录;

其中具体的某一章节则是href属性值与当前目录url的拼接;
我们先获取相应div下边的所有内容:
def get_data(html):
bf = BeautifulSoup(html,'html.parser')
texts = bf.find_all('div',{'class':'listmain'})
text = texts[0]
print(text)
if __name__ == '__main__':
url = 'http://www.biqukan.com/0_790/'
html = get_content(url)
get_data(html)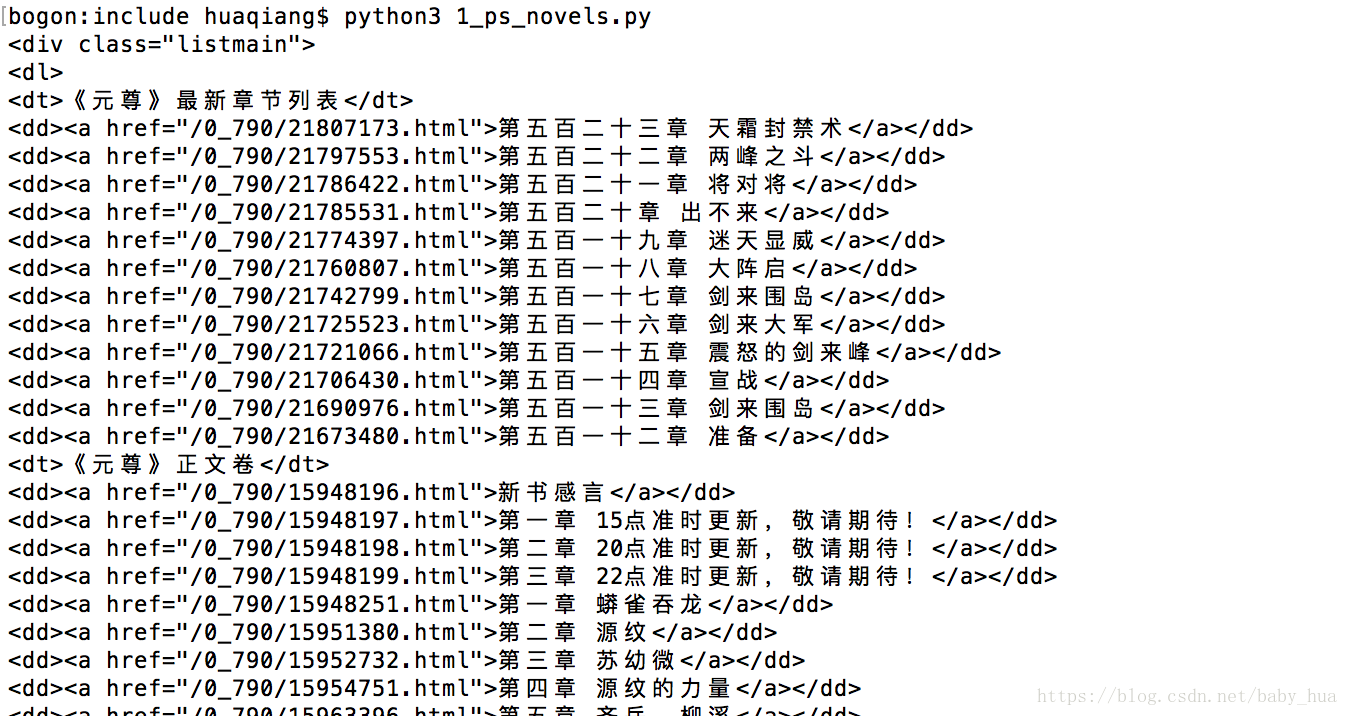
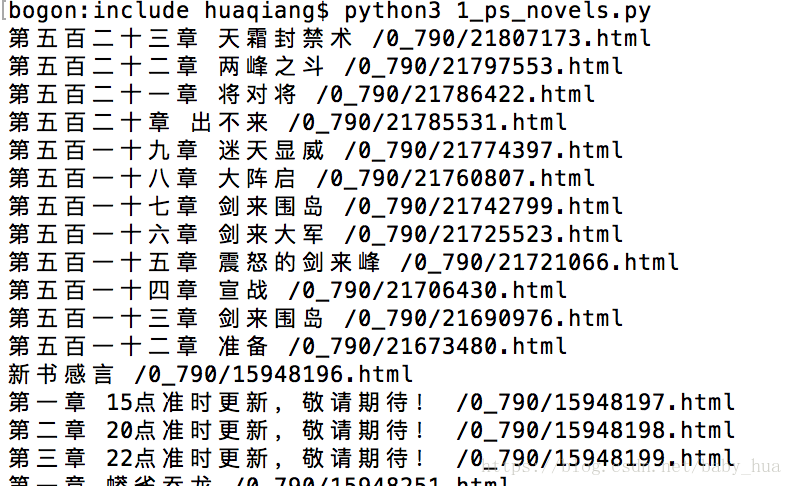
我们修改代码,继续获取div标签下的所有a标签,并打印a标签之间的字符串,以及a标签的href属性;
完整的示例程序:
最终我们整合编码,一个完整的爬虫如下:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import requests #用来抓取网页的html源码
import random #取随机数
from bs4 import BeautifulSoup #用于代替正则式 取源码中相应标签中的内容
import sys
import time #时间相关操作
class downloader(object):
def __init__(self):
self.server = 'http://www.biqukan.com'
self.target = 'http://www.biqukan.com/0_790/'
self.names = [] #章节名
self.urls = [] #章节链接
self.nums = 0 #章节数
"""
获取html文档内容
"""
def get_content(self,url):
# 设置headers是为了模拟浏览器访问 否则的话可能会被拒绝 可通过浏览器获取
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-cn',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1 Safari/605.1.15'
}
# 设置一个超时时间 取随机数 是为了防止网站被认定为爬虫
timeout = random.choice(range(80, 180))
while True:
try:
req = requests.get(url=url, headers=header, timeout=timeout)
break
except Exception as e:
print('3',e)
time.sleep(random.choice(range(8, 15)))
return req.text
"""
获取下载的章节目录
"""
def get_download_catalogue(self,url):
html = self.get_content(url)
bf = BeautifulSoup(html, 'html.parser')
texts = bf.find_all('div', {'class': 'listmain'})
div = texts[0]
a_s = div.find_all('a')
self.nums = len(a_s[12:17]) #我们需要去掉重复的最新章节列表 只为演示 我们只取 不重复的前5章
for each in a_s[12:17]:
self.names.append(each.string)
self.urls.append(self.server + each.get('href'))
"""
获取下载的具体章节
"""
def get_download_content(self, url):
html = self.get_content(url)
bf = BeautifulSoup(html, 'html.parser')
texts = bf.find_all('div', {'class': 'showtxt', 'id': 'content'})
text = texts[0].text.replace('\xa0' * 7, '\n\n') # \xa0表示连续的空白格
return text
"""
将文章写入文件
"""
def writer(self,name,path,text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == '__main__':
dl = downloader()
dl.get_download_catalogue(dl.target)
for i in range(dl.nums):
dl.writer(dl.names[i], '天尊.txt', dl.get_download_content(dl.urls[i]))
print("已下载:%.2f%%"% float((i+1)/dl.nums * 100) + '\r')
print('下载完成!')控制台打印数据进程:

小说内容爬取示例:
至此,我们就得到了整篇小说的内容。