爬虫爬取网络小说并保存为txt文件
最近突然想看小说,但是苦于无法下载为txt,于是秉持着“自己动手,丰衣足食”的原则,自己写了一个爬虫,仅供参考~
这里就以火星引力的《逆天邪神》为例:
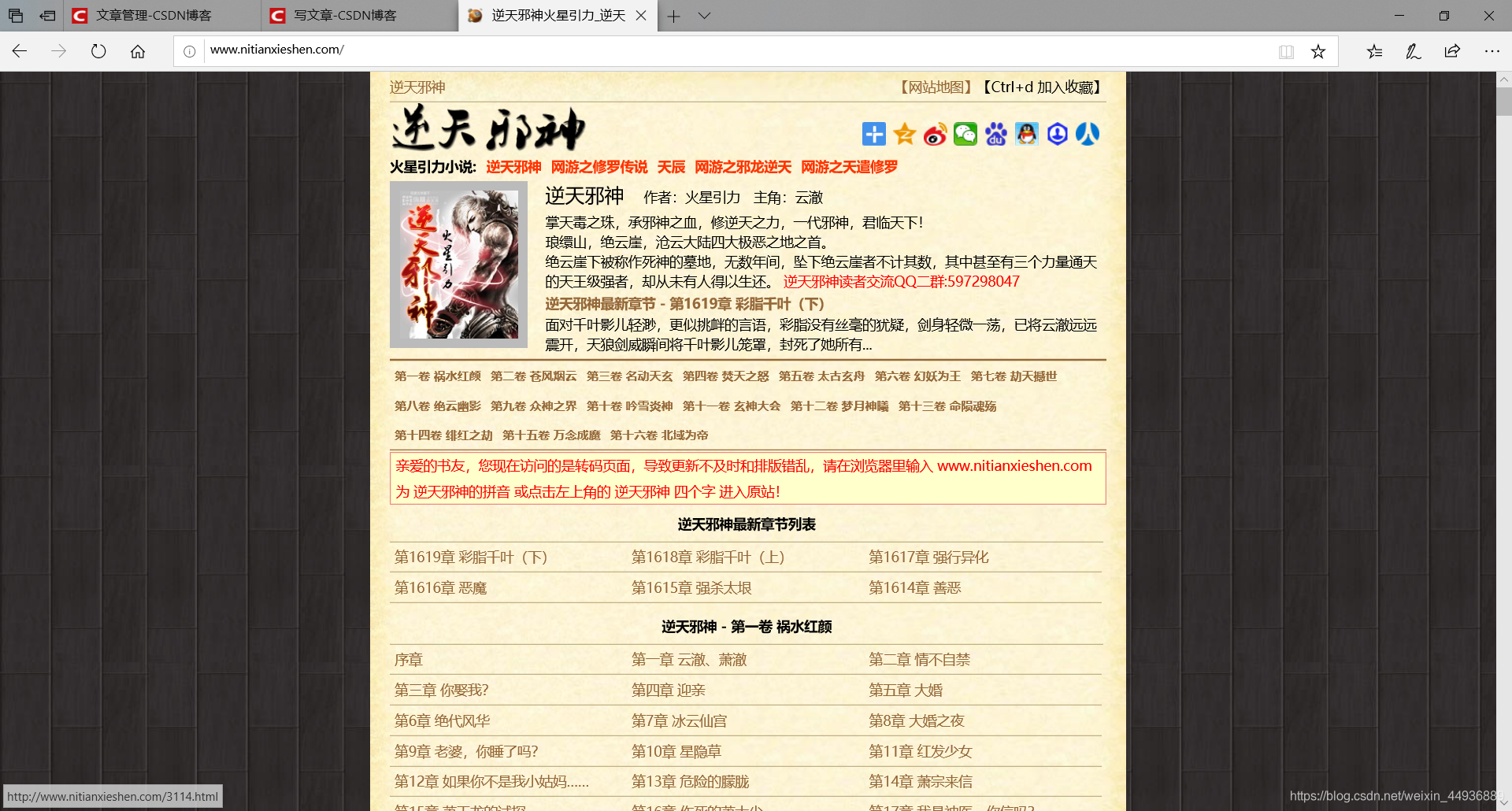
效果:
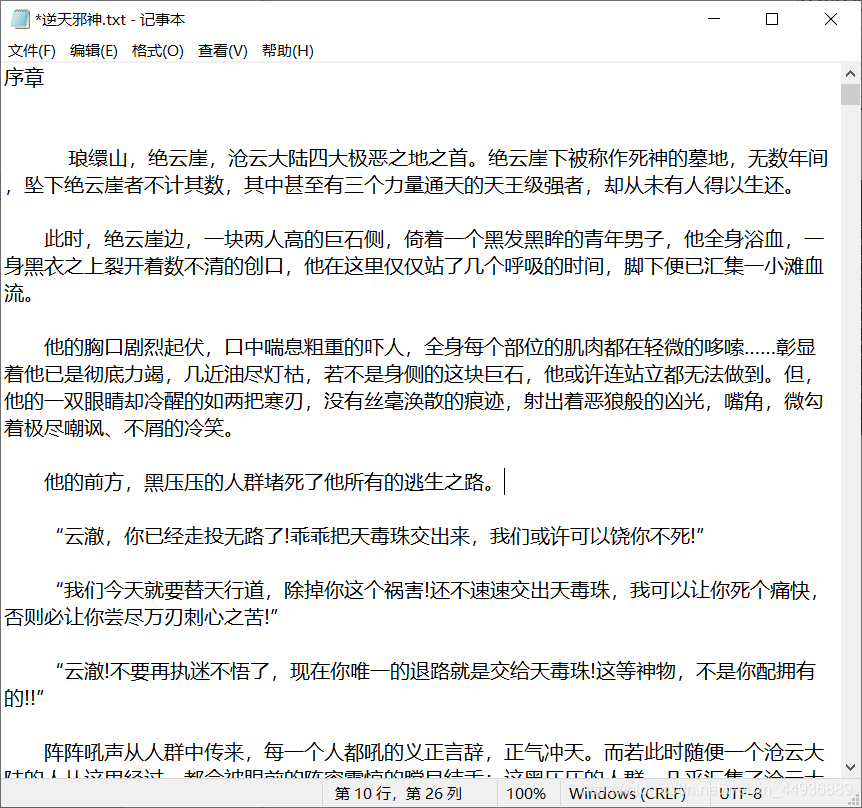
先上代码:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import sys
import time
class downloader(object):
def __init__(self):
self.target = 'http://www.nitianxieshen.com/' # 章节页
self.names = [] # 存放章节名
self.urls = [] # 存放章节链接
self.nums = 0 # 章节数
def get_one_text(self, url_i):
text = ' '
r = requests.get(url=url_i)
r.encoding = r.apparent_encoding
html = r.text
html_bf = BeautifulSoup(html, features='html.parser')
texts = html_bf.find_all('div', class_='post_entry')
for t in texts:
text += str(t)
text = text.replace('<div class="post_entry">', ' ')
text = text.replace('</div>', '\n')
text = text.replace('<br/>', '\n')
text = text.replace('<p>', '\n')
text = text.replace('</p>', '\n')
text = text.replace('<\p>', '\n')
return text
def get_name_address_list(self):
list_a_bf = []
list_a = []
r = requests.get(self.target)
r.encoding = r.apparent_encoding
html = r.text
div_bf = BeautifulSoup(html, features='html.parser')
div = div_bf.find_all('div', class_='container')
div = div[1:]
for i in range(len(div)):
list_a_bf.append(BeautifulSoup(
str(div[i]), features='html.parser')) # div[0]是前100章
list_a.append(list_a_bf[i].find_all('a')) # 返回列表
self.nums += len(list_a[i][:])
for each in list_a[i][:]:
self.names.append(each.string) # string方法返回章节名
self.urls.append(each.get('href')) # get(‘href’)返回子地址串
print(self.names)
print(self.urls)
def writer(self, name, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f: # 打开目标路径文件
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__":
dl = downloader()
dl.get_name_address_list()
print('《逆天邪神》开始下载:')
for i in range(dl.nums):
time.sleep(0.2)
try:
dl.writer(dl.names[i], r'逆天邪神.txt', dl.get_one_text(dl.urls[i]))
except IndexError as e:
print(repr(e))
sys.stdout.write(" 已下载:%.3f%%" % float((i/dl.nums)*100) + '\r')
sys.stdout.flush()
print('《逆天邪神》下载完成')
思路:
(1)首先解析网页:
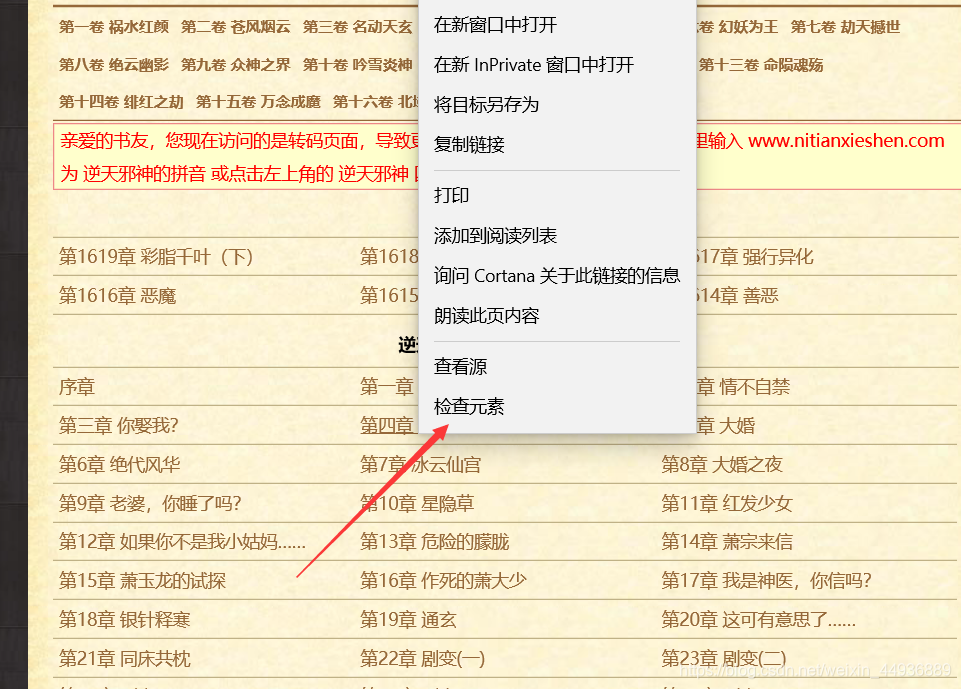
随便点开一章,检查元素:
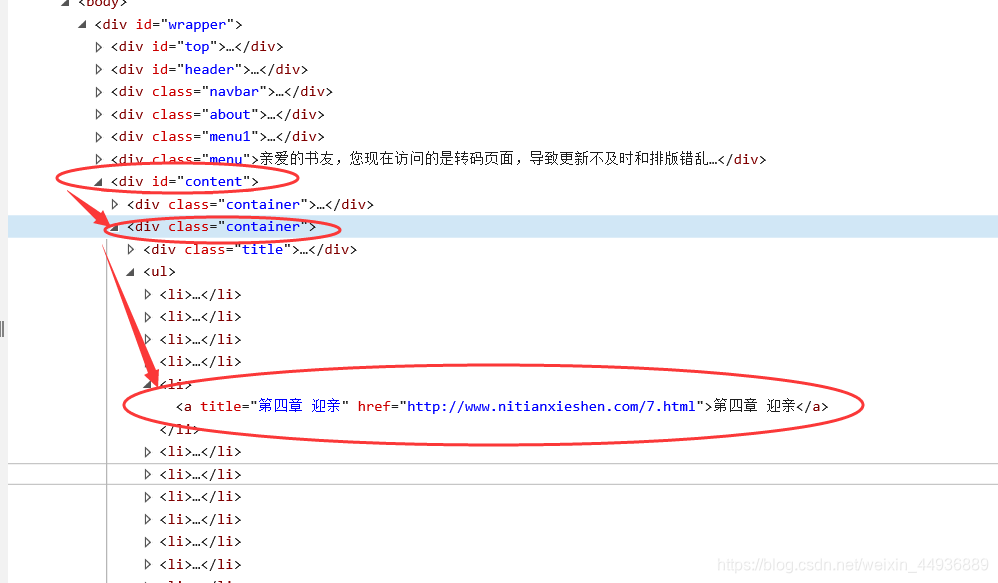
可以看到,每一章都保存在一个class="container"的标签里,每个container保存了100章,这样的话我们只需要历遍这个网页源里所有的container,然后分别取出li下的href地址,就得到了所有章节的地址;
(2)解析文字内容:
点开一个章节页,如图:
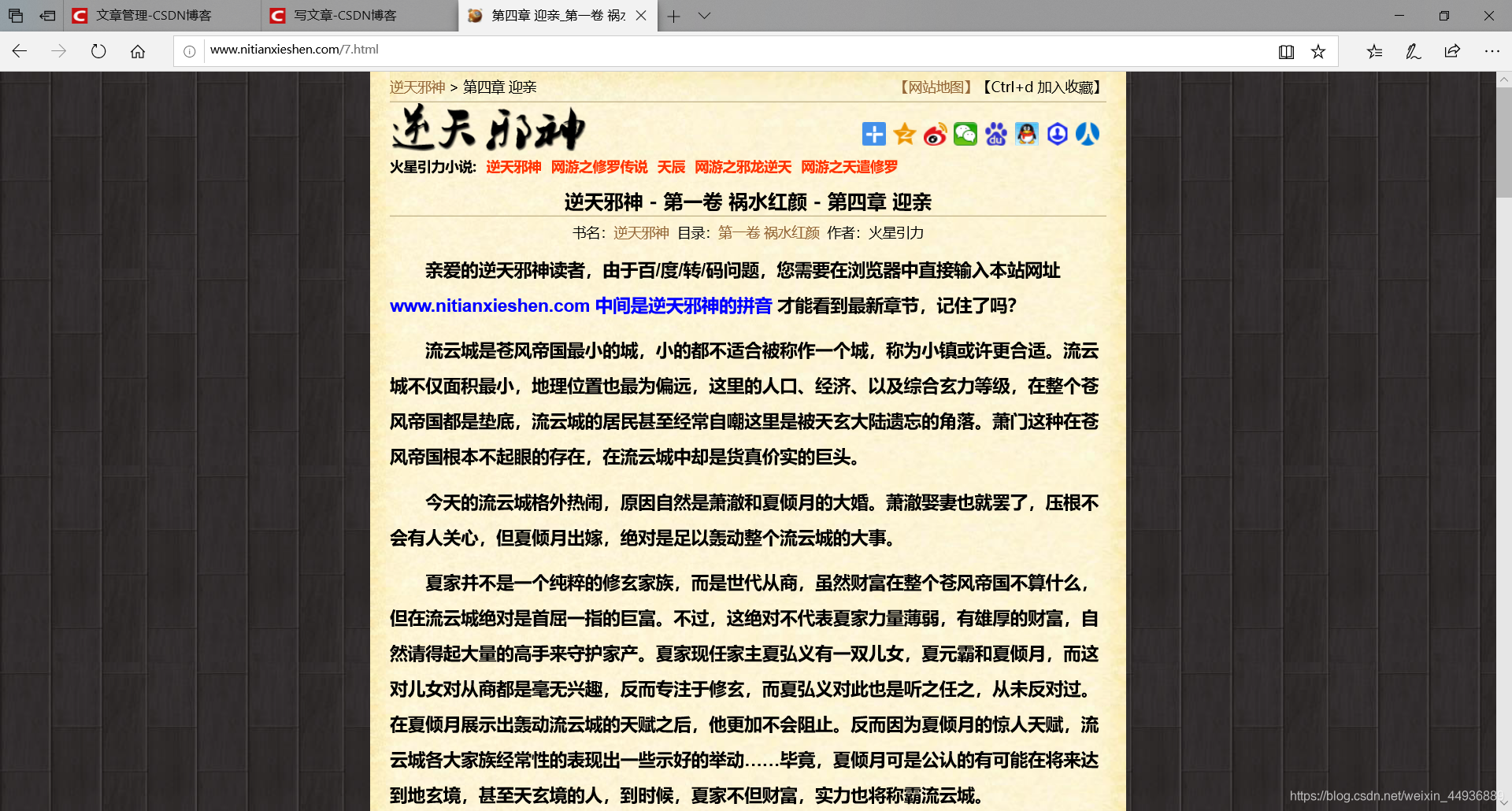
检查文字内容的源:

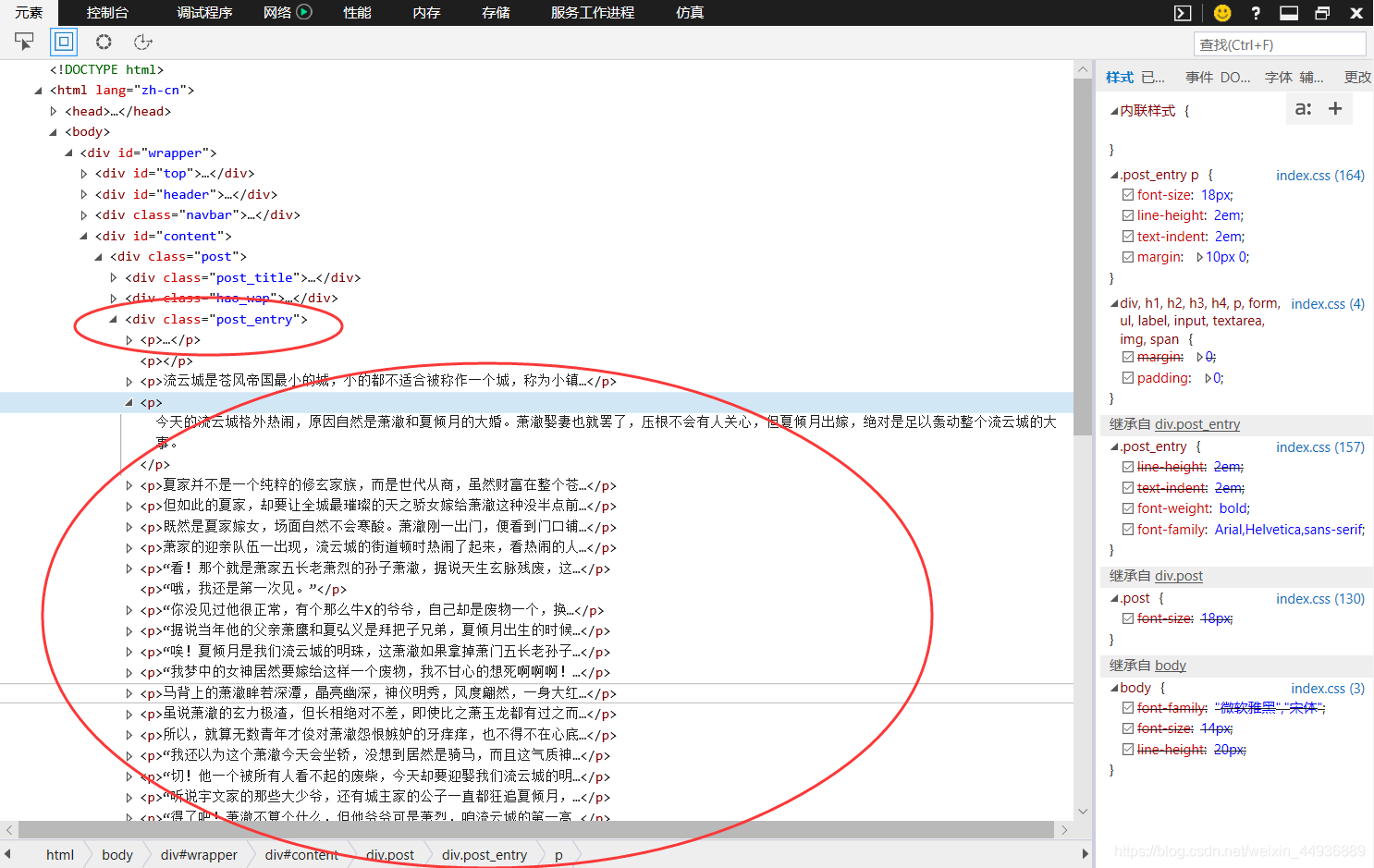 ok,成功找到了保存文本的标签——post_entry;
ok,成功找到了保存文本的标签——post_entry;
(3)遍历章节页,获取文本内容:
这里还是使用了beautifulsoup来解析网页源,如果需要爬取其他小说,只需要把url基质改一下就OK:
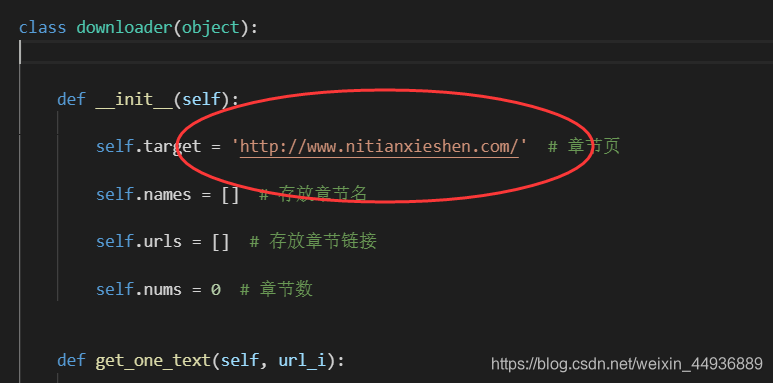
然后运行,效果如图:
耐心等待5到10min就下载完成啦~
