讲授机器学习相关的高等数学、线性代数、概率论知识
大纲:
最优化中的基本概念
梯度下降法
牛顿法
坐标下降法
数值优化算法面临的问题
拉格朗日乘数法
凸优化问题
凸集
凸函数
凸优化
拉格朗日对偶
KKT条件
最优化中的基本概念:
最优化问题就是求一个函数的极大值或极大值问题,一般f(x)是一个多元函数,x∈Rn,一般把最优化问题表述为求极小值问题。
x称为优化变量,f(x)称为目标函数。
可能对x还有约束条件,一个或多个,等式约束或不等式约束,可能有的既有等式约束又有不等式约束,这样就比较复杂了。
满足约束条件且在f(x)定义域内的x组成的集合叫做可行域D。
局部极小值,全局最小值,极值点的导数或梯度等于零,机器学习中的函数一般都是可导的。
直接求一阶导数为零不就可以解出极值点了吗?但实际上不太可行,方程不好求解,会出现超越方程。如下:
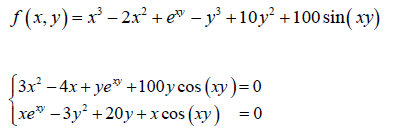
这时要用到迭代法,不断迭代更新未知量的值去找导数为零的点。

梯度下降法:
第一种数值优化(求近似解而非理论上的精确解)算法,叫梯度下降法。
推导梯度下降法的迭代公式:
如果x在x0的δ邻域的话,泰勒展开式中的高阶无穷小项就可以舍去,等式近似成立。
f(x)=f(x0)+▽Tf(x0)(x-x0)+O(x-x0),当x在x0的δ邻域时f(x)≈f(x0)+▽Tf(x0)(x-x0),即f(x)-f(x0)≈▽Tf(x0)(x-x0),于是,怎么让f(x)比f(x0)小逐渐靠近极小值点呢?就让▽Tf(x0)(x-x0)小于零就可以了。怎么做到让它小于零呢?要让▽Tf(x0)(x-x0)小于零,那么▽Tf(x0)、(x-x0)向量的夹角要大于90度,当取(x-x0)为负梯度方向时,f(x)下降速度最快,即xk+1=xk-r▽f(xk),这里▽f(xk)前加一个系数步长r,为了保持xk+1和xk离的充分近即xk+1在xk的邻域内,才能忽略泰勒展开中一次以上的项,即r要足够小。
实现细节问题:
初始值的设定,x从哪一点开始,尽量选一个开始就接近极值点的点。
步长的选择,r选多少合适,一般是经验值,充分接近于0的正数就可以,有时随着迭代过程动态调整。
迭代终止的判定规则,||▽f(xk)||≤ε,梯度足够小接近于零的时候退出循环;或者设定迭代次数。
牛顿法:
也是一种数值优化算法,牛顿是物理学家和数学家,牛顿和莱布尼兹一起发明了微积分,是数学历史上的一次飞跃。