先将模块导入文件中
import pandas as pd
1、DataFrame的属性
df = pd.DataFrame( data={ "name": ["zs", "ls", "ww", "zl"], "age": [18, 19, 29, 11], "score": [92.5, 93, 97, 65] }, index=["stu_1", "stu_2", "stu_3", "stu_4"] )
创建一个df
将df和df的类型打印看看:

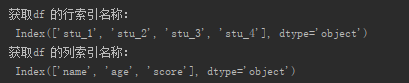
(1)df的索引属性
print("获取df 的行索引名称:\n", df.index) print("获取df 的列索引名称:\n", df.columns)
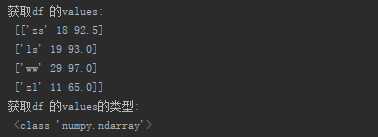
(2)df的values属性
print("获取df 的values:\n", df.values) print("获取df 的values的类型:\n", type(df.values))
(3)df的形状和维度属性
print("获取df 的形状:\n", df.shape) print("获取df 的维度:\n", df.ndim)

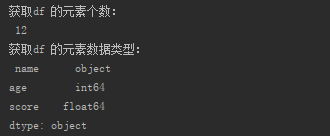
(4)df的元素个数和元素数据类型
print("获取df 的元素个数:\n", df.size) print("获取df 的元素数据类型:\n", df.dtypes)
2、pandas文件的操作
(1)使用read_table()方法读取文件
info = pd.read_table( filepath_or_buffer="./meal_order_info.csv", sep=",", header="infer", # 自动识别 # header=None, # 不指定列名 # header=0, # 指定第0行位 列索引名称 encoding="ansi", # index_col= 0 # 把第0列设置为行索引名称 # nrows=3, # usecols=[0,1], # names=["01","07"], # 可以自己设置列名 # usecols=["info_id","emp_id"] )
csv文件:以逗号“,”为分割符的文本文件,filepath_or_buffer:文件路径+文件名,sep/delimiter:分隔符,header="infer":自动识别索引列名称,names:可以自行指定列名称,index_col:可以指定哪一列、哪几列作为行索引名称,usecol:可以自行获取指定的列,encoding:设置编码,nrows:可以指定读取的行数
(2)使用read_csv()方法读取文件
info = pd.read_csv("./meal_order_info.csv",encoding="ansi")
具体参数参考read_table()方法
(3)使用read_excel()方法读取文件
users = pd.read_excel( "./users.xlsx", sheetname=0, parse_cols=[0, 1], # 在某些版本起作用, )
使用read_excel()方法读取excel文件(.xlsx、.xls结尾),参数1:文件路径+文件名,sheetname:表的序号,index_col:可以指定哪一列、哪几列作为行索引名称,parse_cols:读取指定的列
(4)使用to_csv()方法保存文件
info.to_csv("./info_save.csv",index=False,mode="a")
info:DataFrame变量,index:是否保存索引,mode:保存的模式