一、Series 简介。
二、Series 创建方式。
三、Series 属性与方法。
四、DataFrame 简介。
五、DataFrame 创建方式。
六、DataFrame 属性与方法。
一、Series 简介。
Series是一维结构,由一组数据和一组与之相关的数据标签(索引)组成。序列结构只有行索引(row index),没有列名称(column name),但是序列有Name、dtype和index属性,其中Name属性是指序列的名称,dtype属性是指序列值的类型,index属性是序列的索引。

二、Series 创建方式。
1. ndarray创建
import pandas as pd
import numpy as np
data = np.array(['a', 'b', 'c', 'd', 'e'])
ds = pd.Series(data)
# 手动指定索引
ds = pd.Series(data, index=np.arange(1,6))
2. 字典创建
import pandas as pd
import numpy as np
# 字典创建
data = {
'a': 1.,
'b': 2.,
'c': 3.,
'd': 4.
}
ds = pd.Series(data)
ds = pd.Series(data, index=['d', 'c', 'b', 'a'])
# 如果指定的索引在字典中不存在,缺少的索引元素使用NaN填充。
ds = pd.Series(data, index=['b', 'c', 'a', 'f'])
# out
# b 2.0
# c 3.0
# a 1.0
# f NaN
# dtype: float64
3. 标量创建
如果数据是标量值,则必须提供索引。将重复该值以匹配索引的长度。
import pandas as pd
import numpy as np
ds = pd.Series(5, index=[0, 1, 2, 3])
# out
# 0 5
# 1 5
# 2 5
# 3 5
# dtype: int64
三、Series属性与方法
1. 常用属性。
import pandas as pd
import numpy as np
data = {
'a': 1.,
'b': 2.,
'c': 3.,
'd': 4.
}
ds = pd.Series(data, index=['d', 'c', 'b', 'a'], name='number', dtype='float')
ds.name
ds.index # 获取行索引
ds.values
ds.ndim
ds.shape
ds.size # 元素个数
ds.empty # 是否为空
2.常用方法
当然也可以通过单独的函数分别计算出上面的统计量。比如:ds.min(), ds.max(), ds.median(), ds.quantile(), ds.counts()… …
常用的统计函数都可以直接调用
import pandas as pd
import numpy as np
data = {
'a': 1.,
'b': 2.,
'c': 3.,
'd': 4.
}
ds = pd.Series(data, index=['d', 'c', 'b', 'a'], name='number', dtype='float')
ds.head(2) # 前几个
ds.tail(2) # 末尾2个
ds.describe() # 常用统计量
四、DataFrame 简介。
DataFrame存储的是二维数据,数据框的结构由row和column构成,每一行都有一个row label,每一列都有一个column label,把row和column称作axis,把row label和column label称作axis label。通常情况下,column label 是文本类型,是列名称(column name),而row label是数值类型,也称作行索引(row index)。
多维数组存储二维或三维数据时,编写函数要注意数据集的方向,这对用户来说是一种负担,就像上一章讲过的numpy中,经常遇到要填参数axis,多少还是要过脑子思考一下的。不过在处理 DataFrame 等表格数据时,index(行)或 columns(列)比 axis 0 和 axis 1 更直观。用这种方式迭代 DataFrame 的列,代码更易读易懂。用“更恰当”的方式表示数据集的方向。这样做可以让用户编写数据转换函数时,少费点脑子。
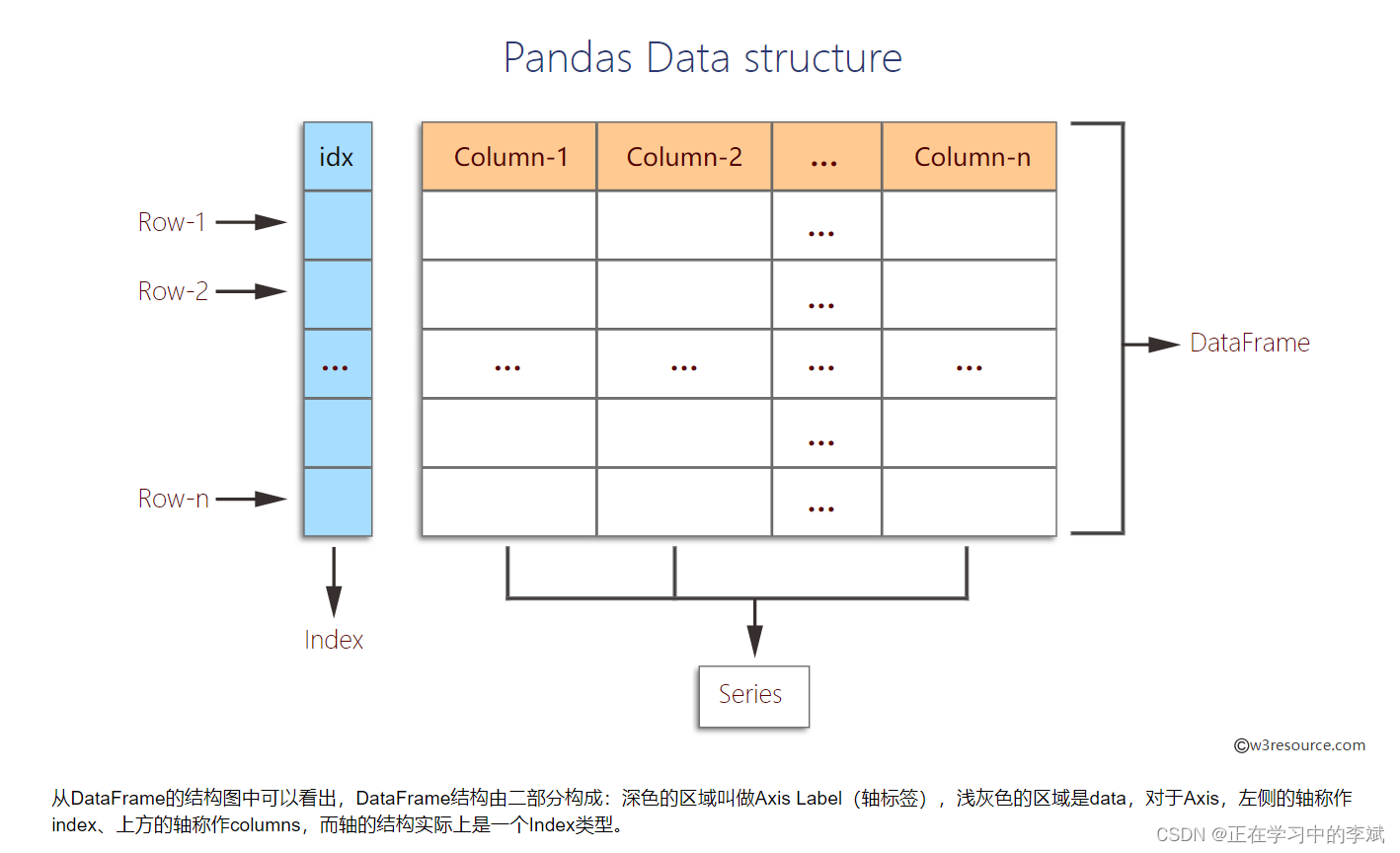
五、DataFrame 创建方式。
创建一个DataFrame数组可以有多种方式,其中最为常用的方式就是利用包含等长度列表或Numpy数组的字典来创建。
1.ndarrays/Lists字典创建
import pandas as pd
import numpy as np
data = {
'one':[1,2,3,4],'two':[4,3,2,1]}
df = pd.DataFrame(data)
# 通过columns参数可以指定列的顺序
df = pd.DataFrame(data, columns=['two', 'one'])
# -------------------------------------------------------
# 除了列表还可以通过numpy的方式生成数组创建dataframe
data = {
'one':np.arange(1, 6, 1), 'two':np.arange(5, 0, -1)}
df = pd.DataFrame(data, columns=['two', 'one'], index=['a', 'b', 'c', 'd', 'e'])
2.Series创建
当然除了List和ndarray之外,也支持用pandas原生的Series生成DataFrame类型
import pandas as pd
import numpy as np
# Series创建
data = {
'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
}
df = pd.DataFrame(data)
六、DataFrame的属性与方法。
DataFrame和Series有很多属性与方法都是通用的,不过在此基础上还增加了一些更多的方法供我们调用。
1. 常用属性
import pandas as pd
import numpy as np
data = {
'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
}
df = pd.DataFrame(data)
df.index # 获取行索引
df.columns # 获取列索引
df.axes # 同时获取 index和columns;df.axes[0] 等价于 df.index
df.values
type(df.values) # ndarray 类型
df.ndim # 维度
df.size # 元素个数
df.shape # 获取行列
#---------------------------------------------------------------------------------
# shape取出是个元组类型,可继续用df.shape[0]获取第一个值,用df.shape[1]获取第二个值
print(df.shape[0])
print(df.shape[1])
2. 常用方法
import pandas as pd
import numpy as np
data = {
'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
}
df = pd.DataFrame(data)
df.head(3) # 前3行
df.tail(3) # 后3行
df.info() # df 详细信息
df.describe() # 常用统计量