预备:
随便搞一个DataFrame 出来先!!!
import numpy as np
import pandas as pd
data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'],
'year': [2016,2016,2015,2017,2016, 2016],
'population': [2100, 2300, 1000, 700, 500, 500]}
frame = pd.DataFrame(data, columns = ['year', 'city', 'population'])
print(frame)

1、两列互换 ----> (城市去前面)
一行代码搞定!!!!
frame.insert(0,'city', frame.pop('city'))说明:
index = 0
colmun_name = 'city'
列的内容 = frame.pop('city')
<class 'pandas.core.series.Series'>
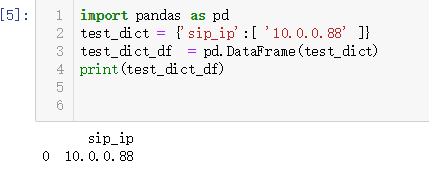
2、创建DataFrame
import pandas as pd
test_dict = {'sip_ip':[ '10.0.0.88' ]}
test_dict_df = pd.DataFrame(test_dict)
print(test_dict_df)
3、读取文件并重新rename
# 读取CSV 直接命名
df = pd.read_csv(file_path, header=None, sep='\t', names=['user_agent'])
# 对DataFrame 改名字
df.rename(columns={'oldName1': 'newName1', 'oldName2': 'newName2'}, inplace=True)4、DataFrame 进行去重
new_clean_data_df = new_clean_data_df.drop_duplicates(subset=['sip_ip'],keep=False).reset_index(drop=True)5、新增数据(DataFrame_A 为历史数据 DataFrame_B 为当天数据 DataFrame_C为新增数据)
new_clean_data_df = clean_data_df.append(get_black_sip_data_frame)
new_clean_data_df = new_clean_data_df.append(get_black_sip_data_frame)
new_clean_data_df = new_clean_data_df.drop_duplicates(subset=['sip_ip'],keep=False).reset_index(drop=True)A+B + A 去重 后就是 C 了

A是红色, B 是绿色, 再加A 是褐色, --> 去重 ,
这样保留的就是新增的了。
未完待续。。。
有一些场景可以描述一下,我来试着实现