版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/baishengxu/article/details/81357003
1.重新索引:reindex可以对行和列索引,默认对行索引,加上关键字columns对列索引。
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]]
df = pd.DataFrame(data,index=['d','b','c','a'])
print(df)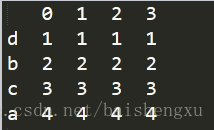
默认对列索引:如果是新的索引名将会用NaN
df=df.reindex(['a','b','c','d','e'])
print(df)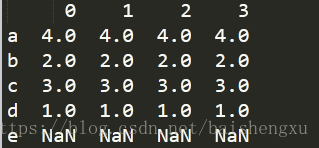
加上关键字columns对列重新索引:
df=df.reindex(columns=[2,1,3,4,0])
print(df)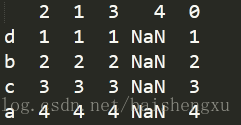
2.reindex插值处理:对于index为有序的数据,我们有时候可能会进行一些插值处理,只需要在reindex加上method参数即可,参数如下表

(图片来源:利用python进行数据分析 Wes McKinney 著)
例子:
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3]]
df = pd.DataFrame(data,index=range(3))
print(df)
df=df.reindex([0,1,2,3,4,5],method='ffill')
print('--------------')
print(df)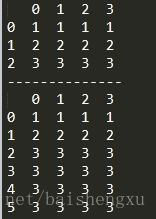
reindex函数的相关参数:

(图片来源:利用python进行数据分析 Wes McKinney 著)
3.删除任意项操作
如果我们不需要某行或某列的数据,我们可以使用DataFrame 的drop方法进行删除,drop方法会将删除某项后的DataFrame作为一个新对象返回。
drop:第一个参数为list,里面存放要删除的项,指定删除哪一轴项,增加axis参数,默认axis=0删除行轴的项,删除列轴的项axis=1
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3]]
df = pd.DataFrame(data,columns=['a','b','c','d'])
print(df)
df=df.drop(['a','b'],axis=1)
print('---------------')
print(df)
4.数据选择
切片操作:DataFrame的切片操作会取末端的数据
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]]
df = pd.DataFrame(data,index=['d','b','c','a'])
print(df)
print(df['b':'a'])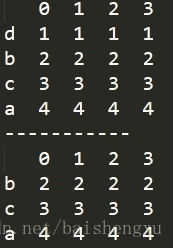
选择满足某个条件的数据:
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]]
df = pd.DataFrame(data,columns=['A','B','C','D'],index=['d','b','c','a'])
print(df)
print('--------------')
print(df['A']>2)
print('--------------')
print(df[df['A']>2])

通过ix选取行列数据:
import pandas as pd
data=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]]
df = pd.DataFrame(data,columns=['A','B','C','D'],index=['d','b','c','a'])
print(df)
print('--------------')
print(df.ix[['a'],['A']])
print('--------------')
print(df.ix[df.A>2,:3])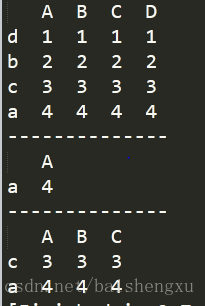
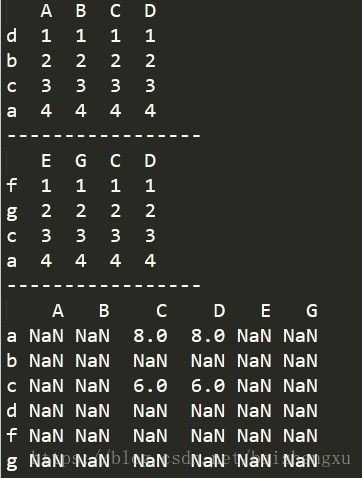
5.DataFrame的运算:只有行和列索引相同才会进行运算,否则运算结果为NaN,下列方法可以使用fill_value将NaN填充成某个值

import pandas as pd
data1=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]]
df1 = pd.DataFrame(data1,columns=['A','B','C','D'],index=['d','b','c','a'])
data2=[[1,1,1,1],[2,2,2,2],[3,3,3,3],[4,4,4,4]]
df2 = pd.DataFrame(data2,columns=['E','G','C','D'],index=['f','g','c','a'])
print(df1)
print('-----------------')
print(df2)
print('-----------------')
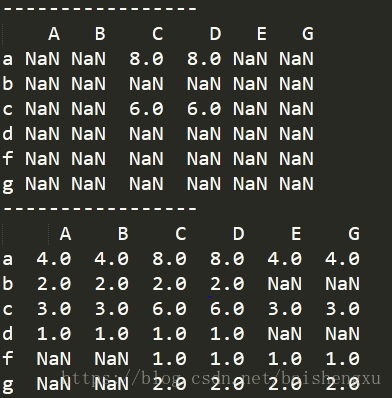
print(df1.add(df2))
print('-----------------')
print(df1+df2)
print('-----------------')
print(df1.add(df2,fill_value=0))