西瓜书笔记 ML(三):线性模型(linear model)
标签(空格分隔): ML
一、基本形式
目标是习得一个通过属性的线性组合来进行预测的函数(具体为向量w和b):
向量形式为:
线性模型虽然简单,但是有很好的可解释性。如某一个属性的重要程度。下面介绍的几种模型都以这两个公式为基础。
对于样本离散属性值的处理:
如果属性是有序的,即可以比较其大小,则将其连续化,如映射到0到1之间。
如果是无序的,即属性之间是并列的关系,则将其维度化。
二、线性回归(linear regression)
1.思想:通过对样本的学习,在样本所在的空间中找到一条直线,使所有的样本距离直线的欧几里都距离最小。通过这条直线,尽可能准确地预测出标记。
目标是习得下式中的w和b:
使得
如何找到最适合的w和b使得欧几里都距离最小,可以使用最小二乘法。
2.标准:最小二乘法
使得
和
之间的均方差最小,即试图找到一条直线,使所有样本到直线上的欧式距离之和最小。
假设m个样本各有d个属性,我们将上式中的矩阵分别做如下变换:
则有:
对于这种多元线性回归,如果 为满秩矩阵或者正定矩阵,则有结果
注意现实中往往 不是满秩矩阵,当属性个数大于样本个数时往往有多个可能的 ,需要根据归纳偏好进行选择,如引入正则化。
3.广义线性模型
将样本线性变化后的结果再做一次处理再作为输出与标记进行比较。也可以看作是将标记做一些变化:
其中 称为联系函数,如: 。此时,形式上仍是线性回归,但实际上求出的已经是输入空间到输出空间的非线性映射了。如求出的可能不在是直线而是曲线。
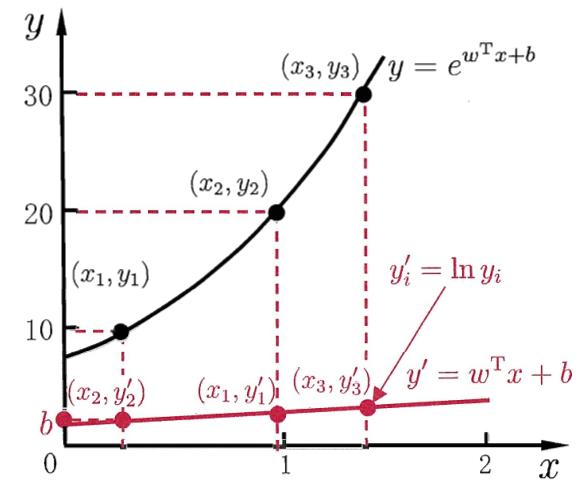
三、对数几率回归
1.思想:
为了实现分类的功能,需要将线性模型输出的预测值同真实标记y联系起来。即类似上述的广义线性模型,将线性模型输出的预测值再做进一步处理以便进行分类。如对于二分类,引热议对数几率函数。
2.对数几率函数:
将线性模型输出的预测值 作为z代入上式,可转化为一个接近0和1的值。对其进行形式上的变化:
将y视为样本 可能为正例的概率,1-y是样本可能为反例的概率,对数几率反映了其相对可能性的对数。
3.标准:最大似然估计
令每个样本属于其真实值的概率越大越好。同样可以解出w和b。
四、线性判别模型(linear discriminant analysis,LDA)
1.思想:
对于给定的样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能的远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来判断新样本的类别。

2.标准:最大化 和 的“广义瑞利商”
五、多分类学习
多分类学习的基本策略是利用二分类学习方法来解决多分类问题,即将任务拆解为多个二分类问题。关键问题是:
1.如何对多分类任务进行拆分
2.如何对多个分类器进行集成
有三种经典的拆分策略:
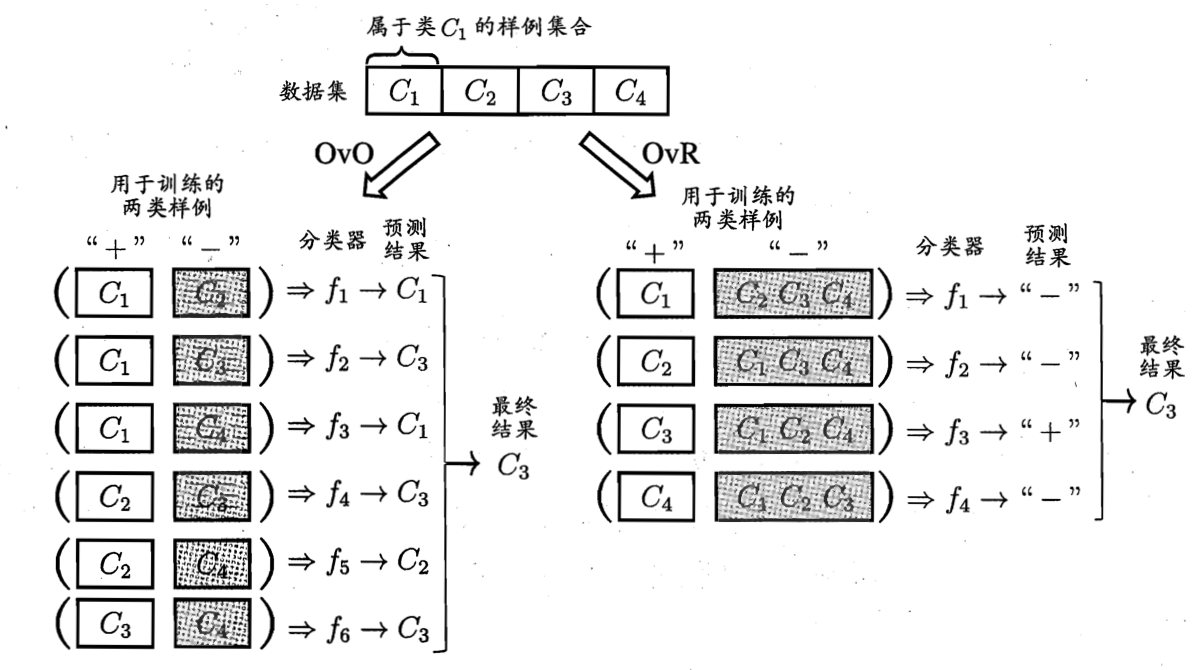
1.一对一(OvO)
将N个类别两两配对,其中一个做正例,一个做反例,从而产生N(N-1)/2个分类器。测试时,将新样本同时提交给所有分类器,然后对分类结果进行统计,投票最多者作为输出的标记。
2.一对其余(OvR)
在N个类别中,每次将一个作为正例,其余作为反例,总共形成N个分类器。测试时,若只有一个分类器输出为正例,则以这个分类器的类别为输出;若有多个分类器输出为正例,则选择置信度最大的类别标记。
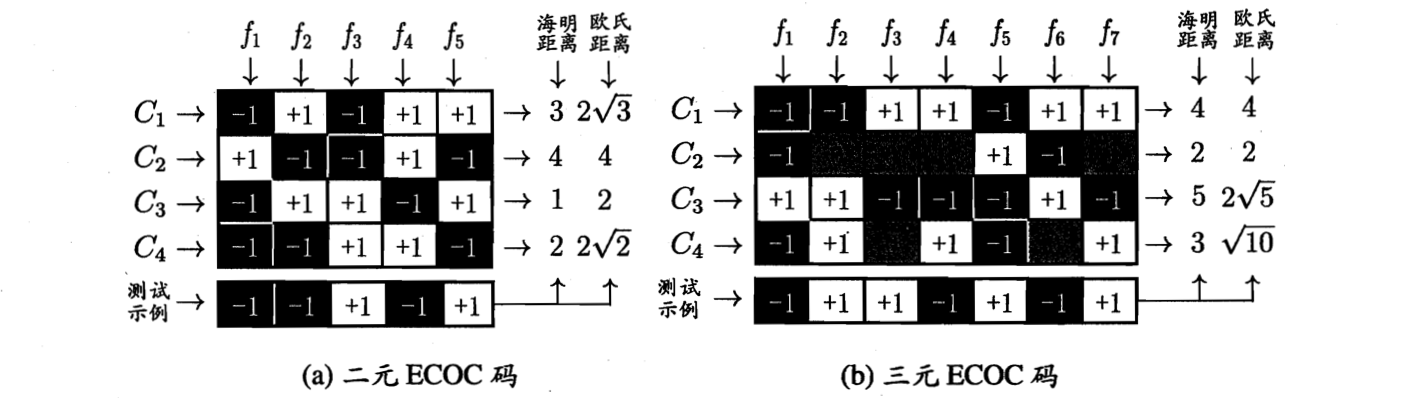
3.多对多(MvM)
对于N个类别,进行M次二分类,形成M个分类器。此时的正反类构造不能随意设置,常用的方法有“纠错输出码”(Error Correcting Output Codes, ECOC)。这个方法有一定的纠错能力(在预测时某个分类器出错并不一定导致结果出错,因为是在很多的结果中选出一个最接近的作为分类)。
主要分两步:
1. 编码: 对N个类别做M次划分,每次划分将一部分类别划为正类,一部分划为负类,从而形成一个二分类训练集,这样一共产生M个训练集,可训练出M个分类器。
2. 解码: M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个列别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。(理解:就是M(5)个分类器先对N(4)个类进行分类(实际上在划分的时候已经明确了),得到一个
的矩阵,然后对测试集的样本进行分类,形成一组
的编码,之后同矩阵中的每一个向量进行比对,距离(我的理解是角度)最小的对应的类别就是预测结果)
类别划分通过“编码矩阵”(coding matrix)指定。常见的编码矩阵有二元编码和三元编码。前者将每个类别划分为正类的负类,后者在正、负类之外,还可指定“停用类”。如图所示
。
显然上述两种方法都是多对多的特殊形式。
六、类别不平衡问题
指的是分类任务中不同类别的样例数差别很大,会对分类器的训练产生影响。
一般有三种解决方法,假设现在正例数相对较少。
1.欠采样
对于样例数较多的类别,去除一些样例。不能随机丢弃,可能造成信息损失,可以使用easyensemble算法。
1.过采样
对于样例数较少的类别,增加一些样例。不能简单重复初始的正例样本,会造成过拟合。可以进行插值,如SMOTE算法。
1.阈值移动(再放缩)
此前的类别判断,如二分类,都是以0.5为阈值进行分类,或者说是
和1的关系进行分类。对于这里的1我们可以做出调整。如根据正反例的数目进行调整(
)或根据代价进行调整(代价敏感性学习
,其中cost+是将正例误分为负例的代价,cost−是将负例误分为正例的代价。):