线性模型
给定d个属性描述的实例x = (x1,x2,...,xd),其中xi是x在第i个属性上的取值,线性模型想要学得一个通过属性的线性组合来进行预测的函数,即:

一般写成向量模型:
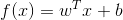
线性回归
给定数据集D={(x1,y1),(x2,y2),(x3,y3)...(xm,ym)} ,其中xi = (xi1,xi2,xi3,...xid) 是d维属性向量,yi∈R,线性回归试图学到一个线性模型以尽可能准确的预测实值输出标记.即:
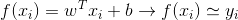
接下来要做的就是确定w和b,关键在于衡量f(x)与y的区别,这里我们常用均方误差作为回归任务中最常用的性能度量,通过最小化均方误差得到最优的w和b.即优化:
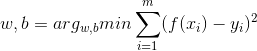
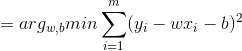
对于这种形式,我们采用最小二乘法进行估计,为了方便计算与编程,这里把w和b归入到同一个向量w^=(w,b),相应的,数据集d表示为一个m x (d+1)大小的矩阵X,其中每行对应一个实例,由于截距项的系数固定为1不需改变,所以矩阵X最后一列均为1,前d个元素对应实例的d个属性值,即:

再将均方误差转化为向量形式:

令:

对w求导,(向量可以看做是正常的二次项求导):

并令导数为0并左乘:
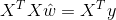
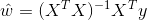
但这里要注意求逆部分,只有满秩或者正定时,上式才可以求逆,如果不满足求逆条件,则需要引入正则化项,规范参数.
回归实现
1)读取数据
#读取数据
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split('\t')) - 1
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat2)计算权数W
#计算w,如果不可逆则报错
def standRegres(xArr,yArr):
xMat = mat(xArr); yMat = mat(yArr).T#转化为向量形式
xTx = xMat.T*xMat
if linalg.det(xTx) == 0.0:#判断是否可逆
print ("该矩阵为奇异矩阵,无法求逆!")
return
ws = xTx.I * (xMat.T*yMat)#根据公式求出w
return ws通过最小二乘法计算的结果,得到复合权数w
3)绘制回归直线
#画出数据点并绘制回归直线
def plot_figure(xArr,yArr,ws):
xMat = mat(xArr)
yMat = mat(yArr)
yHat = xMat * ws#xi的预测值
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xMat[:,1].flatten().A[0],yMat.T[:,0].flatten().A[0],s=5)#画出原始数据点
xcopy = xMat.copy()
xcopy.sort(0)
yHat = xcopy * ws
ax.plot(xcopy[:,1],yHat,c='r')
ax.set_title('Linear Regression')#画出预测数据点
plt.show()根据线性公式和求出的参数w,分别画出原始数据与回归直线进行直观比较.
4)求相关系数
#计算回归后的相关系数
def print_cov(xArr,yArr,ws):
xMat = mat(xArr)
yMat = mat(yArr)
yHat = xMat * ws
cor = corrcoef(yHat.T,yMat)#自带的求相关系数
return cor[0][1]计算回归前后数据的相关系数,越高说明拟合越好
5)主函数
#主函数
if __name__ == '__main__':
xArr,yArr = loadDataSet('ex0.txt')
ws = standRegres(xArr,yArr)
plot_figure(xArr,yArr,ws)
print('相关系数 : ',print_cov(xArr,yArr,ws))6)运行结果
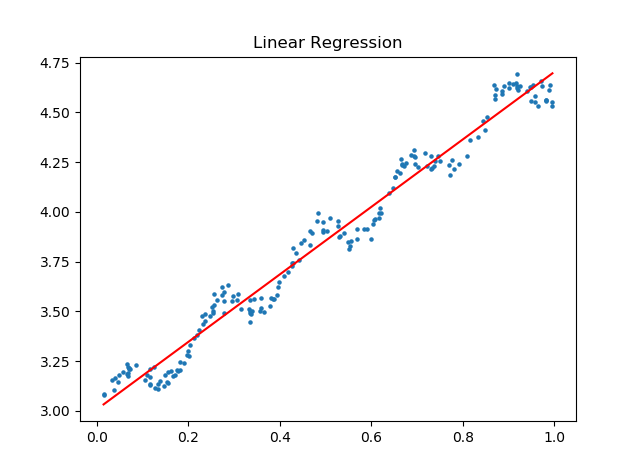
相关系数 : 0.986473562234总结
普通线性回归大概就这些,主要是利用最小二乘法进行最小化均方误差,但是在做回归预测时,要注意过拟合和欠拟合两种情况的出现,过拟合主要由于模型参数过于复杂,学到了数据的噪声,而欠拟合则因为模型过于简单,未能很好的利用数据信息,所以要基于二者有一个权衡,可以考虑加入正则化项,也可以考虑加入权数,下一篇介绍的局部线性加权回归就是加权回归的例子.