深度学习之经典神经网络框架(一):AlexNet
论文:ImageNet Classification with Deep Convolutional Neural Networks
深层卷积神经网络,获得12年ImageNet LSVRC的冠军,本文设计的模型特点有:加入ReLU及两个高效的GPU使训练更快;使用Dropout、Data augmentation、重复池化,防止过拟合;LRN归一化有助于增加泛化能力(在VGG中被证明无用被删除)。
问题or相关工作:
1.当时标记图像的数据集相对较小(数万个),使用这种大小的数据集可以解决简单的识别任务,但现实环境中物体差异性大,有必要用更大的数据集。本文设计了包含5个卷积和3个全连接层的CNN,且作者得出去掉任何一个卷积层都将导致性能的下降。
2.1使用ReLUs激活函数:在AlexNet中,使用了ReLUs (Rectified Linear Units)激励函数,该函数的公式为:f(x)=max(0,x),使用ReLUs的深度卷积神经网络的训练速度是使用tanh单元的数倍,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。。前人也有使用ReLUs用于在数据集上的局部平均池之后的对比度归一化类型,而作者在ImageNet数据集中,主要防止过拟合,原因在于更快的学习速度对大型模型的性能有很大影响。

在CIFAR-10上,具有ReLUs(实线)的四层卷积神经网络达到25%的训练错误率,比具有tanh神经元的等效网络(虚线)快6倍。
2.2 数据填充:增加训练数据,避免过拟合,可用水平翻转、随机裁剪、平移变换、颜色变换等方式
2.3 AlexNet的池化操作为重叠的最大池化,重叠池化可以避免过拟合,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。,此贡献了0.3%的Top-5错误率。
2.4 双GPU:每个GPU中放置一半核(或神经元),将网络分布在两个GPU上进行并行计算,The two-GPU net takes slightly less time to train than the one-GPU net2.
2.5 Dropout 主要为了防止过拟合,consists of setting to zero the output of each hidden neuron with probability 0.5. 以这种方式丢弃的神经元不参与前向和后向传播。因此,在下一次迭代中,神经网络都会对不同的体系结构进行采样,但所有这些体系结构都共享权重。这种技术减少了神经元复杂的协同适应,因为神经元不能依赖于特定的其他神经元的存在。如下图

模型:

AlexNet采用了两个GPU进行训练,该网络结构图由上下两部分组成,一个GPU运行图上方的层,另一个运行图下方的层,两个GPU只在特定的层通信。
以第一层为列:卷积–>ReLU–>池化–>归一化
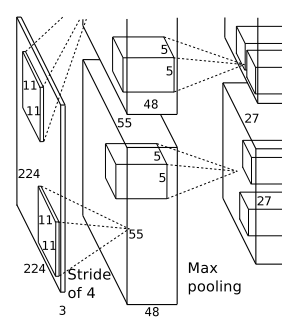
(1)卷积:通用公式,(Img_size-filter_size+2p)/stride+1=new_size,使用96个11×11×3的卷积核,每个GPU承担48个卷积核的运算,Alex第一层步长为4,特征图大小:(227-11)/4+1=55,即55×55,
(2)ReLU:生成激活层,尺寸仍为2组55×55×48的像素层数据。
(3)池化:运算的尺寸为3×3,步长为2,尺寸为 (55-3)/2+1=27,池化后像素的规模为27×27×96。
(4)归一化:尺寸5×5,归一化后的像素不变。这96层像素层被分为两组,每组48个像素层,分别在一个独立的GPU上进行运算。
注:在神经生物学有一个概念叫做“侧抑制”(lateral inhibitio),指的是被激活的神经元抑制相邻神经元。归一化(normalization)的目的是“抑制”,局部归一化就是借鉴了“侧抑制”的思想来实现局部抑制,尤其当使用ReLU时这种“侧抑制”很管用,因为ReLU的响应结果是无界的(可以非常大),所以需要归一化。使用局部归一化的方案有助于增加泛化能力。LRN的公式如下,核心思想就是利用临近的数据做归一化,这个策略贡献了1.2%的Top-5错误率。公式:

(5)全连接层:卷积(全连接)–>ReLU–>Dropout,第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值。
实验结果:
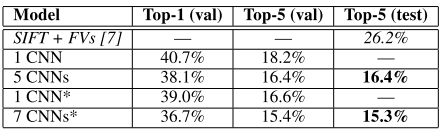
Our results show that a large, deep convolutional neural network is capable of achieving recordbreaking results on a highly challenging dataset using purely supervised learning. To simplify our experiments, we did not use any unsupervised pre-training even though we expect that it will help. 即一个大的,深卷积神经网络能够实现记录打破的结果。